
Dans cet article, on vous explique comment utiliser apache Kafka pour faire de la classification de tweets en direct.
Depuis 3 ans, une grande quantité de tweets sur la Covid-19 a été posté sur Twitter. On y retrouve des news, des réflexions, l’expression de sentiments ou d’opinion et tant d’autres choses. Et depuis, cela ne s’arrête pas.

Le but de cet article est de tirer parti de cette quantité d’information immense et accessible afin de faire de la classification de tweets en direct, c’est-à-dire que nous allons récupérer les tweets qui ont été postés dans les dernières secondes, et les classifier selon leur topic.
Pour cela, nous allons utiliser Apache Kafka ainsi qu’une libraire python qui se nomme Tweepy. Kafka est défini par ses créateurs comme une plateforme open-source de streaming d’événements distribués utilisée par des milliers d’entreprises pour des pipelines de données haute performance, des analyses en continu, l’intégration de données et des applications critiques.
En d’autres termes, cela permet de mettre en contact des Producers (ici ceux qui tweetent) avec des Consumers (ici ceux qui lisent les tweets ou bien dans notre cas précis, notre algorithme qui va récupérer les tweets) via des Topics en temps réel. C’est un système de messagerie distribué à haut débit. C’est une technologie utilisée notamment par Twitter, Linkedin, Uber, AirBnB et Netflix.
Commençons sans plus tarder !
Installer Apache Kafka
Pour installer Kafka, je vous recommande de passer par Docker. Si vous n’avez pas Docker, il suffit de télécharger et installer Docker Desktop ici. Une fois que l’installation est terminée, vous pouvez utiliser Docker via votre terminal de commande. D’abord, il faut copier la cellule suivante dans un fichier texte que vous nommez docker-compose.yml
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:6.2.0
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:6.2.0
container_name: broker
ports:
# To learn about configuring Kafka for access across networks see
# https://www.confluent.io/blog/kafka-client-cannot-connect-to-broker-on-aws-on-docker-etc/
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1Une fois que c’est fait, ouvrez votre terminal de commande, naviguez jusqu’au dossier où vous avez sauvegardé docker-compose.yml et lancez la commande suivante :
docker-compose -f docker-compose.yml up -d
Un téléchargement devrait se lancer. Une fois qu’il est terminé, lancez la commander docker ps pour vérifier que tout s’est bien lancé :
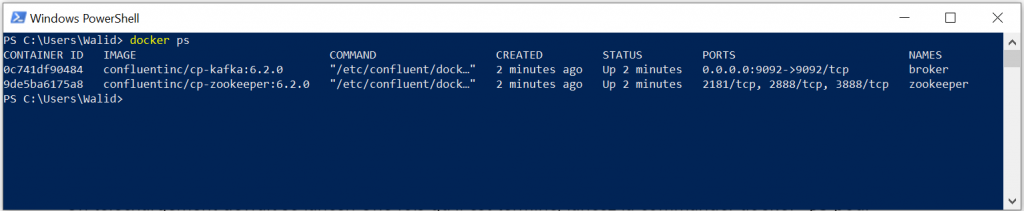
Vous pouvez également lancer Kafka via Docker en vous rendant dans l’onglet Containers/Apps de Docker :
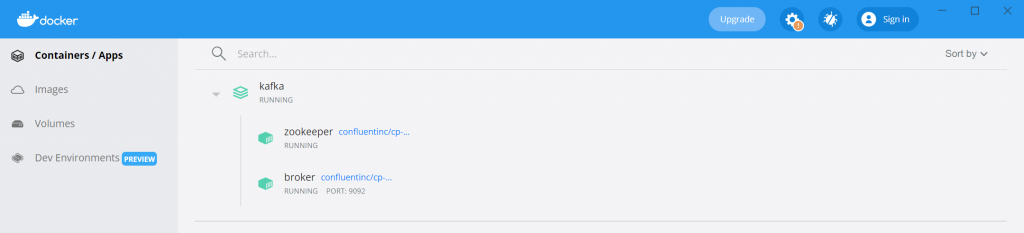
Il faut à présent créer un Topic, c’est-à-dire une catégorie où l’on va stocker les messages (ici les tweets) envoyés par le Producer. Comme nous allons récupérer des tweets sur la Covid-19, nous allons nommer notre topic covid. Pour ce faire, il suffit de lancer la commande suivante dans le terminal en ayant Docker lancé (vous pouvez vérifier que c’est le cas dans l’onglet Containers/Apps de Docker) :
docker exec broker kafka-topics --bootstrap-server localhost:9092 --create --topic covidUn message indiquant Created topic covid. devrait alors s’afficher. Si vous êtes arrivé jusque là, vous avez fait le plus dur !
Afin d’interagir avec Kafka via Python, il faut télécharger une libraire qui se nomme kafka-python. Pour l’installer : pip install kafka-python dans le terminal de commande.
Tweepy et l’API Twitter
Pour pouvoir récupérer des tweets avec Kafka et Python, il nous faut passer par l’API Twitter. Pour cela, vous devez au préalable disposer d’un compte Twitter. Il vous faudra ensuite vous rendre ici et vous connecter pour activer votre compte développeur.
Il se peut que vous ayez à remplir quelques questions rapides (prénom, pays de résidence,…) ainsi qu’à valider votre compte développeur par mail. Une fois que c’est fait, il vous est demandé de choisir le nom de votre application :
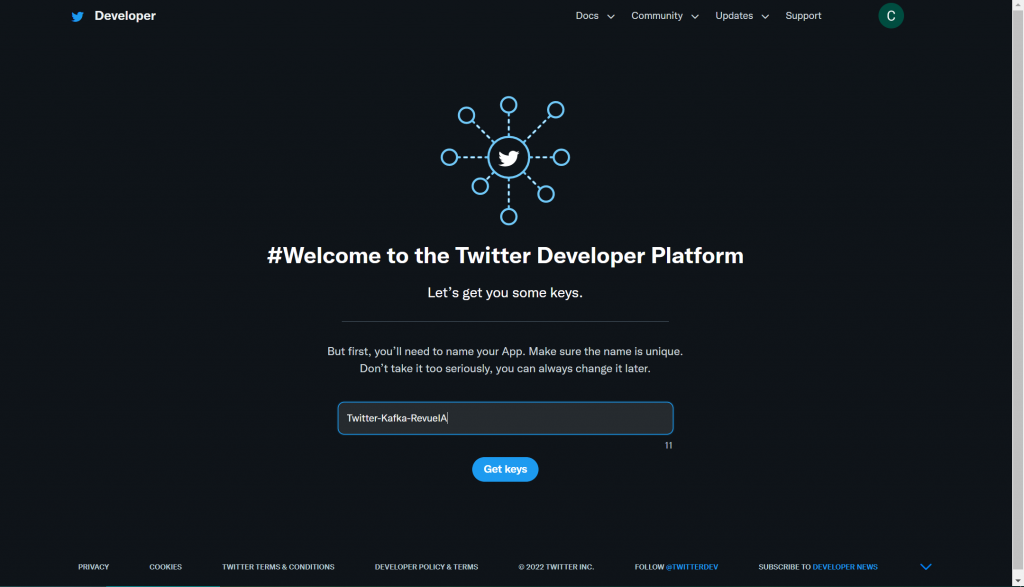
Dès que vous validez, vous avez accès à vos tokens de connexion à l’API. Gardez les en lieu sûr, on les utilisera juste après.
Récupérer les tweets en direct avec Apache Kafka
À présent, nous allons écrire le script python qui va nous permettre de récupérer les tweets en direct. D’abord, on importe les librairies dont on aura besoin :
from kafka import KafkaProducer
import tweepy
import datetime
import time
import json
KafkaProducer va nous permettre d’envoyer les tweets à Kafka (et on les récupérera plus tard avec KafkaConsumer). Tweepy permet de se connecter à l’API Twitter. Les autres modules nous seront utiles pour certaines manipulations.
Nous allons nous connecter à l’API Twitter avec la classe Client de Tweepy. On aura pour cela besoin du BearerToken que vous avez mis de côté précédemment. Nous allons également initialiser un objet de la classe KafkaProducer :
client = tweepy.Client(bearer_token="PLACER_VOTRE_BEARER_TOKEN_ICI")
producer = KafkaProducer()
query = "covid"On définit également la query, c’est-à-dire le mot que l’on veut chercher dans tous les tweets. Pour nous, ce sera « covid », mais vous pouvez essayer d’autres mots ou séries de mots si vous le voulez ! Nous allons récupérer les tweets anglais puisqu’ils sont plus nombreux et que nous allons utiliser un modèle entrainé sur des tweets anglais.
Avec tweepy, on ne peut récolter que les tweets qui datent d’au moins 10 secondes. Pour être sûr de respecter ce délai (et comme j’ai rencontré des problèmes même en prenant 15 secondes), nous allons prendre 30 secondes. Nous allons donc régler le temps de début de récolte des tweets à 40 secondes du temps actuel, et la fin à 30 secondes.
On utilise la méthode search_recent_tweets pour récolter les tweets les plus récents. Nous sommes limités à 100 par appel de la méthode, nous allons donc nous limiter à 100 tweets. Enfin, on spécifie les champs que l’on veut récolter via le paramètre tweet_fields : le corps du tweet, sa date de création ainsi que sa langue :
start_time = datetime.datetime.utcnow() - datetime.timedelta(seconds=40)
end_time = datetime.datetime.utcnow() - datetime.timedelta(seconds=10)
tweets = client.search_recent_tweets(query=query,
tweet_fields=['context_annotations', 'created_at', 'lang'],
max_results=100,
start_time=start_time,
end_time=end_time)
start_time = end_time
end_time = start_time + datetime.timedelta(seconds=10)
Puis on récupère le contenu des tweets en sélectionnant uniquement les tweets anglais, on envoie les tweets sur Kafka et on affiche un message pour indiquer que tout s’est bien passé.
for i,tweet in enumerate(tweets.data):
if tweet.lang == 'en':
tweet = json.dumps(tweet.text).encode('utf-8')
producer.send('covid', tweet)
print(f'Le {i}ème tweet a été envoyé à Kafka avec succès!')
On ajoute une boucle while pour répéter le processus sans arrêt. On fait une pause de 10 secondes pour ne pas avoir une redondance dans les tweets récupérés : Le script complet :
from kafka import KafkaProducer
import tweepy
import datetime
import time
import json
client = tweepy.Client(bearer_token='PLACER_VOTRE_BEARER_TOKEN_ICI')
producer = KafkaProducer()
# producer.flush()
query = 'covid'
start_time = datetime.datetime.utcnow() - datetime.timedelta(seconds=40)
end_time = datetime.datetime.utcnow() - datetime.timedelta(seconds=30)
while True:
tweets = client.search_recent_tweets(query=query,
tweet_fields=['context_annotations', 'created_at', 'lang'],
max_results=100,
start_time=start_time,
end_time=end_time)
start_time = end_time
end_time = start_time + datetime.timedelta(seconds=10)
for i,tweet in enumerate(tweets.data):
if tweet.lang == 'en':
tweet = json.dumps(tweet.text).encode('utf-8')
producer.send('covid', tweet)
print(f'Le {i}ème tweet a été envoyé à Kafka avec succès!')
print('Pause de 10 secondes!')
time.sleep(10)En lançant le script, on obtient le message que les tweets ont bien été envoyés à Kafka. Toutes les 10 secondes, une centaine de tweet sont envoyés à Kafka au topic « covid ». Il faut maintenant les récupérer pour pouvoir les utiliser ultérieurement. Il est indispensable que ce script soit lancé lorsque vous réaliserez les parties suivantes ! Je vous conseille de le lancer via le terminal de votre PC en ouvrant un terminal au niveau de votre script et en lancant python nom_de_votre_script.py
Nuage de mots
Faisons tout d’abord un nuage de mots des tweets que nous avons récupéré. Cela nous permettra de voir quels sont les mots les plus récurrents. D’abord nous allons définir une fonction pour nettoyer et préparer nos tweets. Comme d’habitude, si vous n’avez pas la librairie nltk, faites pip install nltk.
from nltk.tokenize import RegexpTokenizer
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
import re
import string
def pre_process_tweet(tweet):
tokenizer = RegexpTokenizer(r'\w+')
lemmatizer = WordNetLemmatizer()
# tokenize and remove stop words and number
tweet_tokens = tokenizer.tokenize(tweet)[1:]
tweet_tokens = [word for word in tweet_tokens if word.isalpha()]
tweet_tokens = [word for word in tweet_tokens if word.lower() != 'rt']
tweet = " ".join([word for word in tweet_tokens if word not in stopwords.words('french')])
# remove \n from the end after every sentence
tweet = tweet.strip('\n')
# Remove any word that starts with the symbol @
tweet = " ".join(filter(lambda x: x[0] != '@', tweet.split()))
# remove non utf-8 characters
tweet = bytes(tweet, 'utf-8').decode('utf-8','ignore')
# Remove any URL
tweet = re.sub(r"http\S+", "", tweet)
tweet = re.sub(r"www\S+", "", tweet)
# remove colons from the end of the sentences (if any) after removing url
tweet = tweet.strip()
tweet_len = len(tweet)
if tweet_len > 0:
if tweet[len(tweet) - 1] == ':':
tweet = tweet[:len(tweet) - 1]
# Remove any hash-tags symbols
tweet = tweet.replace('#', '')
# Convert every word to lowercase
tweet = tweet.lower()
# remove punctuations
tweet = tweet.translate(str.maketrans('', '', string.punctuation))
# trim extra spaces
tweet = " ".join(tweet.split())
# lematize words
tweet = lemmatizer.lemmatize(tweet)
return(tweet)Parmi les opérations effectuées : tokenization, lemmatization (prendre la racine d’un mot), suppression des url, de la ponctuation, des symboles, …
Pour créer notre nuage de mots, nous allons utiliser la librairie wordcloud. Si elle n’est pas installée sur votre machine, faites simplement pip install wordcloud. Pour récupérer les tweets qui ont été envoyé sur le topic « covid », nous allons initialiser un Consumer avec le paramètre « covid » (le nom du topic) :
from wordcloud import WordCloud
from kafka import KafkaConsumer
consumer = KafkaConsumer("covid")Nous allons d’abord récupérer les 50 premiers tweets et construire le wordcloud avec les mots qu’ils contiennent. Pour cela, nous allons concaténer tous les tweets dans la chaine de caractère nommée total_sentences. Nous allons ajouter un mask afin de donner à notre nuage de point la forme du logo Twitter. Pour ce faire, télécharger l’image ici, nommez la « twitter_logo.jpg » et placer-là dans le même dossier que votre script/notebook. Vous pouvez vous amuser en modifiant les paramètres du nuage de mots pour obtenir des résultats differents.
import numpy as np
from PIL import Image
import json
import numpy as np
from PIL import Image
import json
import matplotlib.pyplot as plt
total_sentences = ""
twitter_mask = np.array(Image.open("twitter_logo.jpg"))
for i in range(50):
tweet = json.loads(next(iter(consumer)).value)
clean_tweet = pre_process_tweet(tweet=tweet)
total_sentences += clean_tweet
total_sentences += " "
wordcloud = WordCloud(width=800, height=500, random_state=42, max_font_size=100, mask=twitter_mask,
contour_color="steelblue", contour_width=0, background_color="white").generate(total_sentences)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()Le code peut prendre un peu de temps à se lancer. Kafka peut parfois être capricieux, si vous utilisez une notebook, n’hésitez pas à réinstancier votre Consumer avant de lancer une cellule. J’ai effectué le nuage de mots en français pour que cela soit plus parlant (et car on n’a pas besoin d’utiliser le modèle entrainé sur les tweets anglais), mais je passerai à l’anglais à partir de maintenant. Vous devriez obtenir quelque chose semblable à ceci :
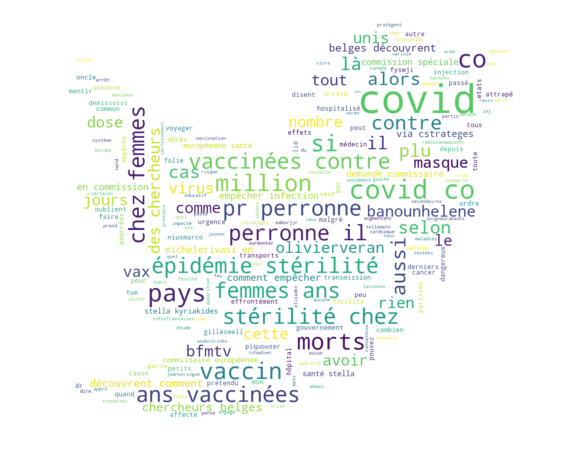
On obtient des mots qui sont bien liés au covid et qu’on a beaucoup entendus ces dernières années : morts, vaccin, olivier veran, épidémie, …
Vous n’obtiendrez pas exactement la même chose que moi car les tweets que vous allez récupérer sont différents des miens. On peut modifier le code pour actualiser le nuage de mots avec les nouveaux tweets toutes les 5 secondes :
import numpy as np
from PIL import Image
import json
import numpy as np
from PIL import Image
import json
import matplotlib.pyplot as plt
plt.figure(figsize=(15,8))
twitter_mask = np.array(Image.open("img_notebook/twitter_logo.jpg"))
total_sentences = ""
while True:
for i in range(10):
tweet = json.loads(next(iter(consumer)).value)
clean_tweet = pre_process_tweet(tweet=tweet)
total_sentences += clean_tweet
total_sentences += " "
wordcloud = WordCloud(width=800, height=500, random_state=42, max_font_size=100, mask=twitter_mask,
contour_color="steelblue", contour_width=0, background_color="white").generate(total_sentences)
# plot the graph
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
plt.pause(5)
clear_output(wait=True)
plt.figure(figsize=(15,8))Il est important de noter que nous aurions pu effectuer ces manipulations et obtenir ce nuage de mots sans passer par Apache Kafka, uniquement avec l’API Twitter. Nous n’avons pas utilisé tout le potentiel de Kafka. Nous pourrions par exemple récupérer les tweets avec différents scripts donc chacun serait indépendant et aurait un but différent : créer un wordcloud dynamique, classifier les tweets, prévenir l’utilisateur dès lors qu’un certains type de tweet est détecté, ou qu’un utilisateur en particulier poste un tweet, …Il est également possible d’envoyer les tweets vers différents topics en même temps et les récupérer sur différents scripts pour différentes utilisations.
Ici, la force de Kafka que l’on utilise est que les tweets sont récupérés et envoyés dans un topic Kafka de manière indépendante de tous les autres scripts. Ainsi, en initialisant un Consumer avec le topic « covid », nous pouvons récupérez tous les tweets qui ont été envoyé sur Kafka peu import où l’on se trouve sur la machine.
Création des topics
Nous passons maintenant à la partie Machine Learning de l’article ! Afin de déterminer les topics dans lesquels nous allons classer nos tweets, nous allons récupérer 20 000 tweets, puis, après les avoir nettoyés, nous allons déterminer les 10 sujets les plus récurrents. Pour transformer nos tweets (qui sont des chaines de caractères), en inputs compréhensibles pour l’ordinateur (des chiffres), nous allons utiliser word2vec. Je vous en ai déjà parlé dans un article précédent ici. Nous allons utiliser un modèle qui a été pré-entrainé sur plus de 400M de tweets anglais. Vous pouvez le télécharger ici (attention, il est assez volumineux). Pour le charger, nous utilisons gensim :
model = gensim.models.KeyedVectors.load_word2vec_format('word2vec_twitter_model.bin', binary=True, unicode_errors='ignore')
Ce modèle transforme chaque tweet en un vecteur de taille 400. Le script suivant permet de récupérer 20000 tweets. tweet_embeddings est un tableau qui contient l’embedding de chaque tweet, et text_data contient les tweets bruts.
# n_sample = 20000
# tweets_embeddings = np.zeros((n_sample, 400))
# text_data = []
# row = 0
# for tweet in consumer:
# if row == n_sample:
# break
# tweet = json.loads(tweet.value)
# clean_tweet = pre_process_tweet(tweet)
# embeddings = get_word2vec_embeddings(model=model, tokenizer=tokenizer, sentence=clean_tweet, k=400)
# if np.isnan(embeddings).sum() == 0:
# tweets_embeddings[row,:] = embeddings
# text_data.append(clean_tweet)
# row += 1Cette étape est relativement longue (environ 1h30). Pour la faire durer moins longtemps, vous pouvez réduire le nombre de tweets à récupérer. Vous pouvez également utiliser les tweets que j’ai moi-même récupérés. Vous pouvez télécharger text_data ici et tweets_embeddings ici. Il faut ensuite les charger avec la librairie pickle (si vous avez Python 3.9 ou plus, pickle devrait être nativement présent, sinon pip install pickle4 ou pip install pickle-mixin.
TF-IDF
Afin de déterminer quels sont les topics préponderants dans nos tweets, nous allons utiliser la méthode TF-IDF. Si vous ne savez pas ce que c’est, nous en avons déjà parlé ici. En quelques mots, TF-IDF compte de manière intelligente le nombre de fois que chaque mot apparaît dans une classe de documents. Si le mot apparaît également dans toutes les autres classes, il n’est probablement pas important (comme « le » ou « un ») et, pour cette raison, il n’est pas considéré comme « fréquent ». Cela nous permet de récupérer les topics les plus pertinents. Pour ce faire, nous allons définir trois fonctions :
from sklearn.feature_extraction.text import CountVectorizer
def c_tf_idf(documents, m, ngram_range=(1, 1)):
count = CountVectorizer(ngram_range=ngram_range, stop_words="english").fit(documents)
t = count.transform(documents).toarray()
w = t.sum(axis=1)
tf = np.divide(t.T, w)
sum_t = t.sum(axis=0)
idf = np.log(np.divide(m, sum_t)).reshape(-1, 1)
tf_idf = np.multiply(tf, idf)
return tf_idf, count
def extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20):
words = count.get_feature_names()
labels = list(docs_per_topic.Topic)
tf_idf_transposed = tf_idf.T
indices = tf_idf_transposed.argsort()[:, -n:]
top_n_words = {label: [(words[j], tf_idf_transposed[i][j]) for j in indices[i]][::-1] for i, label in enumerate(labels)}
return top_n_words
def extract_topic_sizes(df):
topic_sizes = (df.groupby(['Topic'])
.Doc
.count()
.reset_index()
.rename({"Topic": "Topic", "Doc": "Size"}, axis='columns')
.sort_values("Size", ascending=False))
return topic_sizesLa fonction c_tf_idf permet d’obtenir le score TF-IDF ainsi que le nombre de mots totaux; extract_top_n_words_per_topic et extract_topic_sizes donnent respectivement les n mots avec le score TF-IDF le plus élévé et la taille de chaque topic. Pour déterminer les topics, nous utilisons un modèle K-Means de scikit-learn que nous entrainons avec nos 20000 tweets. Nous choisissons 15 clusters pour avoir 15 topics. Vous pouvez choisir plus ou moins, en fonction du nombre de topics que vous désirez.
from sklearn.cluster import MiniBatchKMeans
n_clusters=15
cluster = MiniBatchKMeans(n_clusters=n_clusters, random_state=0).fit(tweets_embeddings)
Pour chaque cluster, nous regroupons tous les tweets en un seul gros tweet afin de pouvoir effectuer le comptage TF-IDF. Ensuite, pour chaque classe, nous récupérons les n premiers mots ayant le score TF-IDF le plus élevé, puis, pour chaque classe, nous choisissons le mot ayant le score le plus bas. Cette méthode nous permet de récupérer les mots qui apparaissent souvent dans un document mais qui sont en même temps discriminants.
docs_df = pd.DataFrame(text_data, columns=["Doc"])
docs_df['Topic'] = cluster.labels_
docs_df['Doc_ID'] = range(len(docs_df))
docs_per_topic = docs_df.groupby(['Topic'], as_index = False).agg({'Doc': ' '.join})
tf_idf, count = c_tf_idf(docs_per_topic.Doc.values, m=len(text_data))
top_n_words = extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=10)
topic_sizes = extract_topic_sizes(docs_df).set_index('Topic')
topic_sizes.head(15)Nous pouvons voir nos 15 topics avec la taille de chaque topic (sans le label des topics pour le moment) :

Pour obtenir le label de chaque topic, nous allons prendre l’élément avec le plus petit score TF-IDF dans top_n_words pour chaque topic :
data = pd.DataFrame(top_n_words[0][:n_clusters])
data['Class'] = [0]*len(data)
for i in range(1,len(top_n_words)):
data_i = data_0 = pd.DataFrame(top_n_words[i][:1000])
data_i['Class'] = [i]*len(data_i)
data = data.append(data_i)
data = data.sort_values(by=1,ascending=False)
final_data = data.drop_duplicates(subset=0).sort_values(by='Class').drop_duplicates(subset='Class',keep='last').rename(columns={0:'label', 1:'TF-IDF score'})
final_dataCe qui donne les labels suivants :
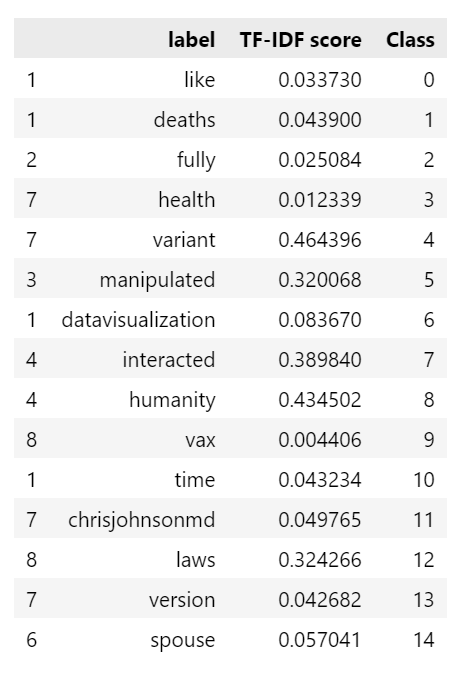
On trouve des topics assez parlant comme « vax », « laws » ou « variant », et d’autres un peu moins comme « spouse » ou « like ». C’est néanmoins assez représentatif du covid. Vous pouvez vous amusez à jouer avec le nombre de topics ainsi que le nombre de mots que vous choisissez dans la fonction top_n_words pour obtenir des résultats différents.
Visualisation des topics via PCA
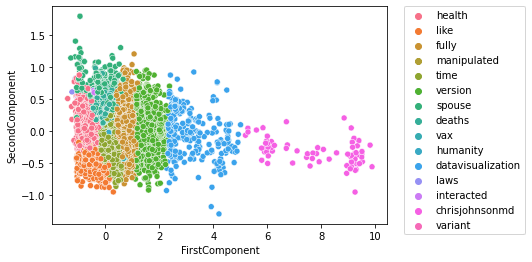
Nous pouvons faire une PCA (Analyse par Composantes Principales) pour voir comment se répartissent les différents topics. D’abord, effectuons une PCA en 2D avec scickit-learn. Nous allons faire la PCA sur les embeddings des 20 000 tweets que nous avons récupérés, puis nous allons associer à chaque embedding son topic. Pour cela, nous utilisons seaborn et scikit-learn.
from sklearn.decomposition import PCA
import seaborn as sns
pca_2d = PCA(n_components=2)
pca_2d.fit(tweets_embeddings)
pca_2d_data = pd.DataFrame(pca_2d.transform(tweets_embeddings),columns=['FirstComponent','SecondComponent'])
sns.scatterplot(x=pca_2d_data.FirstComponent,y=pca_2d_data.SecondComponent,
hue=[labels_to_class[cluster_label] for cluster_label in cluster.labels_])
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0)On obtient un résultat assez élégant, les différents topics sont bien séparés !
Nous pouvons également le faire en 3D pour encore mieux visualiser les embeddings. C’est un peu plus complexe que pour la 2D mais rien de très difficile à comprendre. Nous utilisons plotly :
import plotly.express as px
pca_3d = PCA(n_components=3)
pca_3d.fit(tweets_embeddings)
pca_3d_data = pd.DataFrame(pca_3d.transform(tweets_embeddings),columns=['FirstComponent','SecondComponent','ThirdComponent'])
x = pca_3d_data.FirstComponent
y = pca_3d_data.SecondComponent
z = pca_3d_data.ThirdComponent
df_3D = pd.DataFrame(columns=['x', 'y', 'z', 'label'])
df_3D['x'] = x
df_3D['y'] = y
df_3D['z'] = z
df_3D['label'] = [labels_to_class[cluster_label] for cluster_label in cluster.labels_]
fig = px.scatter_3d(df_3D, x='x', y='y', z='z',
color='label')
fig.show()Le résultat est encore meilleur ! Lorsque vous le lancez chez vous, pouvez faire bouger le plot avec la souris pour visualiser comme bon vous semble !

Vous pourriez avoir l’idée d’utiliser les tweets obtenu via la PCA pour faire la classification (que nous ferons à la prochaine partie), mais cela ne fait que trop réduire l’information, et cela mène à de moins bon résultats. Vous verrez que le modèle se débrouille plutôt bien même avec 400 composantes dans l’embeddings !
Classification en direct des tweets
Nous passons dorénavant à la partie Machine Learning avec laquelle vous êtes, je pense, un peu plus à l’aise ! Nous allons utiliser les clusters que nous avons déterminés dans la partie précédente, ainsi que le même MiniBatchKMeans. Chaque fois qu’un tweet est classé, nous le mettons dans un DataFrame qui contient les tweets et leur prédiction. Tous les 100 tweets, nous sauvegarderons ce DataFrame ainsi que notre modèle sous le nom « cluster ». Nous devons d’abord initialiser un Consumer avec le topic « covid ». N’oubliez pas de lancer docker et Kafka avant cette étape si ce n’est pas déjà fait (toujours dans l’onglet Containers/Apps).
consumer = KafkaConsumer('covid')
Toutes les 100 prédictions, nous affichons un message qui indique que cents tweets supplémentaires ont été classifiés. Notez bien qu’il faut lancer le script qui récupère les tweets et les envoie sur Kafka avant de lancer la cellule suivante !
df_predictions = pd.DataFrame(columns=['tweet', 'prediction'])
for tweet in consumer:
row = df_predictions.shape[0]
tweet = json.loads(tweet.value)
clean_tweet = pre_process_tweet(tweet)
embeddings = get_word2vec_embeddings(model=model, tokenizer=tokenizer, sentence=clean_tweet, k=400).reshape(1,-1).astype(np.double)
cluster.partial_fit(embeddings)
prediction = cluster.predict(embeddings)[0]
df_predictions.loc[row, 'tweet'], df_predictions.loc[row, 'prediction'] = tweet, labels_to_class[prediction]
sample_score_embeddings[row % 1000, :] = embeddings
sample_score_labels[row % 1000, :] = prediction
if row % 100 == 0:
print(f'{row} tweets ont été classifiés')
print(100*'-')
with open('cluster', 'wb') as f:
pickle.dump(cluster, f)
try:
df_predictions.to_excel('df_predictions.xls')
except:
passLe script est conçu pour tourner en continu et ne pas s’arrêter, vous pouvez interrompre son exécution quand vous le voulez, ou le modifier pour qu’il s’arrête lorsque vous le désirez. Voilà un extrait de ce que j’ai obtenu :

On retrouve le numéro du tweet classifié (dans l’ordre croissant d’arrivé), le tweet en question et le topic dans lequel il a été classifié.
Conclusion
Ceci conclu notre tutoriel de classification non supervisé de tweet en utilisant Apache Kafka. Il est important de noter que nous n’avons pas exploité Kafka à son plein potentiel dans cet article.
Nous avons seulement voulu vous introduire cette technologie. Il est possible de faire beaucoup plus, notamment en utilisant différents topics, différents consumers, différents producers, differentes applications, …
Vous pouvez vous entrainer et développer le potentiel de Kafka sur des données de vélos partagés : https://developer.jcdecaux.com/#/login. Vous obtiendrez les données de Bike Sharing Systems (comme Vélib à Paris) disponible partout dans le monde. On a, entre autre, le nom de la station, la ville, le nombre de vélos disponibles, le nombre de vélos maximum,… Vous pouvez vous entrainer et vous amusez avec ce jeu de données en direct!


Leave a Comment