
Tensorflow est une des bibliothèques Python les plus utilisées lorsqu’il est question de machine learning. Combinée à Keras, elle rend la construction et l’entrainement de modèles beaucoup plus simples.

Dans cet article nous allons construire pas à pas un système de classification d’images de produits avec Tensorflow.
Tensorflow fourni des bases de données intéressantes, j’ai choisi la base Fashion MNIST. Elle comprend des milliers d’images d’articles de modes labellisés (T-shirt, Sacs, Pantalons, etc). L’objectif est de construire un système capable de reconnaître l’article de mode dans une image.
Prérequis
Vous commencez à me connaitre et vous savez déjà que je vais coder sur Google Colab. Vous pouvez aussi travailler avec un notebook Jupyter ou en local. L’avantage de Google Colab est que la plupart des modules sont déjà disponibles et vous n’aurez rien à faire au préalable.
De plus, Colab permet de profiter de la puissance du GPU, vous n’avez qu’à vous rendre dans Modifier puis Paramètres de Notebook et dans Accélérateur matériel sélectionnez GPU.
Si vous ne travaillez pas avec Colab vous n’avez qu’a installer Tensorflow, depuis votre console si vous êtes en local, dans le notebook sinon :
pip install Tensorflow # En local
!pip install Tensorflow # Depuis le notebookOn importe les modules dont on aura besoin.
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as npSi vous avez suivi les tutoriels précédents vous connaissez déjà ces modules.
Matplotlib est le module qui nous permettra de tracer des graphes et d’afficher les images.
Tensorflow nous permettra de construire nos réseaux de neurones.
Numpy est le module passe partout, c’est un des plus utilisés sur Python, il nous permettra notamment de gérer les images comme des matrices de valeurs.
Chargement des données et preprocessing
La base Fashion MNIST est une base constituée par Zalando, elle est disponible directement sur Tensorflow.
La base comprend 60 000 images pour entraîner notre modèle et 10 000 pour le tester. Les images sont de très basse résolution, elles ont une taille de 28 par 28. Cela permet d’accélérer l’entrainement du modèle.
Commençons par importer les données. Nous allons garder de côté les 10000 images de test pour la fin et nous entraîneront le modèle avec les 60000 premières.
Il faut savoir que nous allons utiliser keras dans Tensorflow. Keras est une API qui permet de construire rapidement des modèles de deep learning. Attention à ne pas confondre le Keras de Tensorflow et le module Keras. Lorsque l’on appelle une fonction on utilisera tf.keras pour différencier les deux.
fashion_mnist = tf.keras.datasets.fashion_mnist
(images_train, targets_train), (images_test, targets_test) = tf.keras.datasets.fashion_mnist.load_data()
print(images_train.shape)
print(targets_train.shape)Ici on importe la base de données fashion_minst depuis tensorflow. Ensuite on récupère les images et leur noms de catégories associés.
print(images_train.shape) permet d’afficher la taille de la base d’images d’entrainement. Les deux dérnières lignes donnent le résultat suivant :
(60000, 28, 28)
(60000,)Maintenant que la base d’images est importée, on peut essayer d’afficher quelques images :
plt.imshow(images_train[15000]) # affiche la 15000eme imageJ’en ai récupéré quelques unes pour avoir une idée de ce à quoi les images ressemblent.




Bon on voit que c’est des images de très faibles résolutions. Cette base a été constituée à des fins éducatives. Elle permet de coder un premier prototype de modèle de deep learning sans que ce soit trop coûteux en terme de temps de calcul.
Vérifions si nos données sont équilibrées. Pour la classification il faut s’assurer que toutes les classes sont équitablement représentées.
On commence par définir les noms des catégories :
targets_names = ["T-shirt", "Pantalon", "Pull", "Robe", "Manteau", "Sandale",
"Chemise", "Sneaker", "Sac", "Bottes"]On peut alors tracer le diagramme qui nous donne la répartition d’images selon ces catégories.
# Noms des catégories et fréquences d'apparitions
labels = targets_names
sizes = np.unique(targets_train,return_counts=True)[1]
# Choix des couleurs
colors =['#fff100','#ff8c00','#e81123','#ec008c','#68217a', '#00188f',
'#00bcf2','#00b294','#009e49','#bad80a']
# Construction du diagramme et affichage des labels et des #fréquences en pourcentage
fig1, ax1 = plt.subplots()
ax1.pie(sizes, colors = colors, labels=labels, autopct='%1.1f%%', startangle=90)
# Tracé du cercle au milieu
centre_circle = plt.Circle((0,0),0.70,fc='white')
fig = plt.gcf()
fig.gca().add_artist(centre_circle)
# Affichage du diagramme
ax1.axis('equal')
plt.tight_layout()
plt.show()Je ne m’attarde pas sur ce code, ce n’est pas l’objectif du tutoriel. Néanmoins si la data visualisation vous intéresse je me ferais un plaisir d’écrire à ce sujet !
Le résultat obtenu est le suivant.
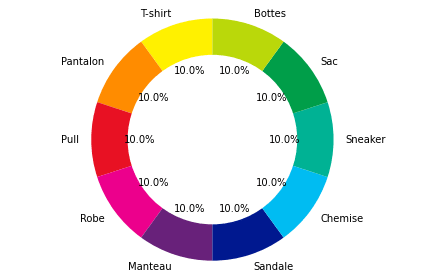
On voit bien que les catégories sont toutes représentées de manière égale. C’est rarement le cas dans le cadre d’applications concrètes, en entreprise par exemple. Néanmoins, des techniques existent pour rééquilibrer les données. Elles sont très faciles à mettre en place avec Scikitlearn par exemple.
Construction du premier modèle avec Tensorflow
Commençons par construire un premier modèle très simple. Voici le code complet.
Architecture du réseau
On prend un réseau de neurones avec deux couches cachées. La première comportera 256 neurones, la seconde en comportera 128.
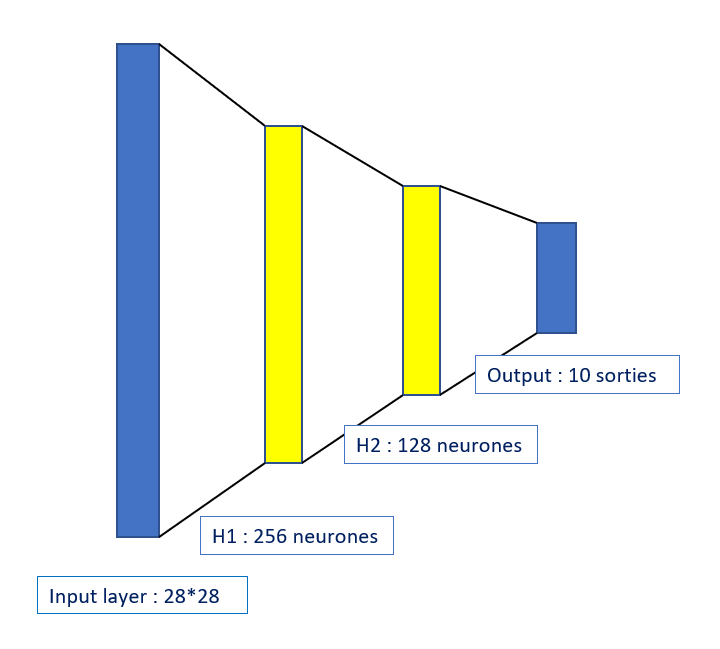
La couche d’entrée sera constituée de 784 neurones. On a des images de taille 28*28, on doit transformer l’image (qui est à la base une matrice) en un vecteur colonne de taille 784. Tous les neurones de ce réseau sont connectés entre eux.
La seconde couche contient 256 neurones. Il n’y a pas de raisons particulière à ce choix. Des techniques d’optimisation des hyper-paramètres existent, mais pour ce projet elles ne sont pas nécessaires.
De même pour la seconde couche, je n’ai pas d’explications pour le choix du nombres de neurones. Il est d’usage d’essayer plusieurs architectures et de les comparer. Cela permet de construire un bon modèle de façon empirique.
En revanche pour la couche de sortie, les 10 neurones correspondent aux valeurs des probabilités d’être dans une certaine classe. Si on avait 5 classes on aurait mis 5 neurones.
Construction avec Tensorflow
On peut commencer à coder. Vous verrez qu’avec Keras c’est vraiment très facile.
# On converti nos valeurs en float
images_train = images_train.astype(float)
images_test = images_test.astype(float)
# On normalise les pixels pour avoir des valeurs entre 0 et 1
images_train = images_train/255
images_test = images_test/255On commence toujours par créer un modèle de type Sequential.
model = tf.keras.models.Sequential()
On crée une première couche qui va permettre d’aplatir la matrice. C’est à dire la transformer en vecteur.
model.add(tf.keras.layers.Flatten(input_shape=[28,28]))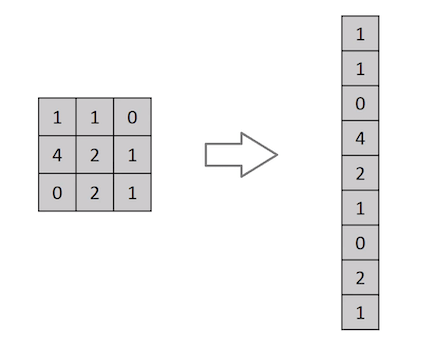
On construit maintenant nos 2 couches cachées et la couche de sortie. Le paramètre activation correspond à la fonction d’activation choisie. Je ne vais pas m’attarder sur ces choix. Néanmoins cet article vous permettra de comprendre comment elles sont choisies.
model.add(tf.keras.layers.Dense(256, activation="relu"))
model.add(tf.keras.layers.Dense(128, activation="relu"))
model.add(tf.keras.layers.Dense(10, activation="softmax"))Une fois ces cellules exécutées, on peut faire un résumé de ce que l’on a :
model.summary()Le résultat est le suivant. Cela nous permet de nous assurer qu’il n’y a pas d’erreurs.
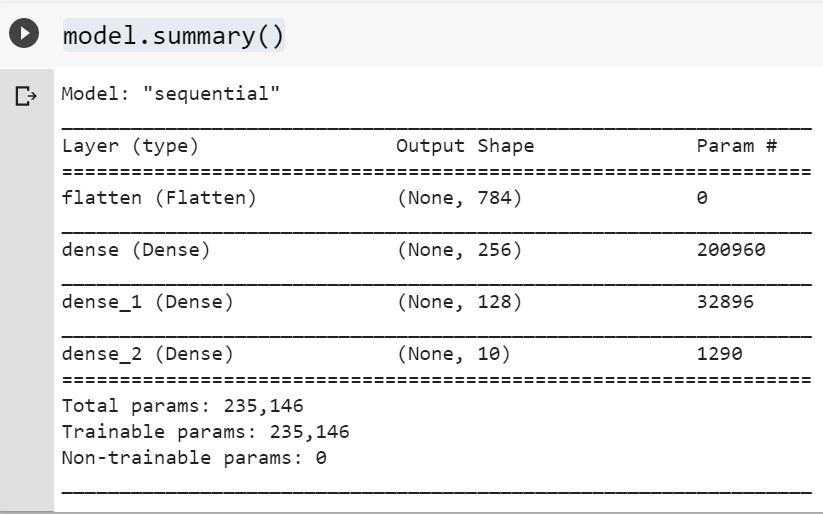
Il faut maintenant compiler le modèle et comme toujours en machine learning, il faut faire des choix. On doit déterminer quelle méthode d’optimisation on veut utiliser pour trouver les poids. On doit choisir un fonction de perte et une fonction de mesure de la précision.
Ces choix sont aussi importants que le choix de l’architecture du réseau. La méthode d’optimisation influence la vitesse d’entrainement du réseau et les deux autres paramètres permettent d’évaluer les performances de notre modèle.
Voici ce que j’ai choisi pour ce modèle. Vous pouvez essayer de jouer sur les paramètres pour améliorer les résultats globaux. C’est un des meilleurs moyen pour apprendre !
model.compile(
loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"]
)On peut maintenant commencer l’entrainement du réseau avec model.fit :
history = model.fit(images_train,
targets_train,
epochs=10,
validation_split=0.2)Vous verrez les époques s’exécuter l’une après l’autre. L’entrainement devrait durer moins d’une minute.

L’époque (epochs) correspond au nombre de passage effectués sur les poids. Plus il y a d’époques plus l’entrainement prendra de temps mais plus le modèle sera efficace. Attention à ne pas faire trop d’époques, c’est le meilleur moyen de tomber dans l’over-fitting.
validation_split est le paramètre qui permet de séparer les données d’entrainement et les données de test. Il est d’usage de prendre 20% de données de test et 80% de données d’entraînements. Ici on aurait pu prendre les données de test fournis par Zalando mais je préfère les garder pour comparer ce modèle avec celui que nous allons construire dans la partie 2.
Résultats
Maintenant que le réseau est entraîné, nous pouvons regarder l’évolution de nos performances époque après époque. Cette étape est importante.
Elle permet d’abord de nous assurer que les résultats sont bons. Et elle peut aussi permettre de détecter un éventuel over-fitting.
history permet de stocker les valeurs de la perte et de la précision, à la fois sur les données d’entraînements (loss et acc) et sur les données de test (loss_val et acc_val).
C’est surtout les valeurs sur les données de test qui nous intéressent. Les valeurs sur les données d’entraînements sont toujours bonnes puisque c’est elles qui permettent de configurer le modèle.
Une fois que ces valeurs sont stockées dans des listes, on a plus qu’à les tracer avec plt.plot de matplotlib.
loss_curve = history.history["loss"]
acc_curve = history.history["accuracy"]
loss_val_curve = history.history["val_loss"]
acc_val_curve = history.history["val_accuracy"]
plt.plot(loss_curve, label="Train")
plt.plot(loss_val_curve, label="Val")
plt.legend(loc='upper left')
plt.title("Loss")
plt.show()
plt.plot(acc_curve, label="Train")
plt.plot(acc_val_curve, label="Val")
plt.legend(loc='upper left')
plt.title("Accuracy")
plt.show()Voici les courbes obtenues.
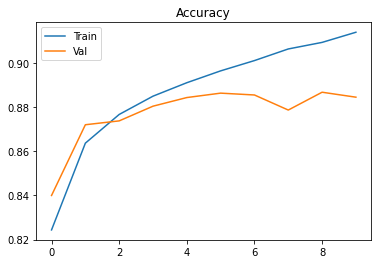
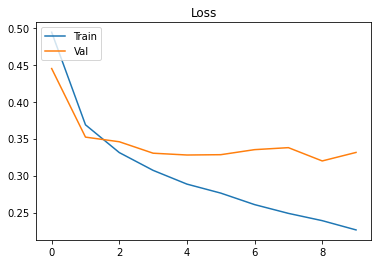
Après l’entraînement du modèle, et malgré la grande simplicité de celui-ci, nous avons des résultats déjà assez bons. 88% des images de test sont bien classées par le modèle. 10560 images sur 12000 au total ont été bien classés.
Rappelez-vous que nous avions garder de côté la base de test fournie par Tensorflow. Elle nous permet de confirmer nos résultats.
loss, acc = model.evaluate(images_test, targets_test)
print("Test Loss", loss)
print("Test Accuracy", acc)Avec cette base on a 87,6% de réussite. C’est quasiment le même résultat.
On peut quand même essayer de faire mieux. Il reste quand même 12% d’erreurs.
Les réseaux à convolution (CNN) sont mieux adaptés pour la classification d’images
Le premier modèle construit donne d’assez bons résultats. Néanmoins, lorsqu’il est question de classification d’images d’objets (et d’analyse d’images en général), il est plus courant d’utiliser des réseaux à convolution.
Le code suivant est disponible à ce lien.
Le fonctionnement des réseaux à convolution est détaillé dans mon article sur les réseaux de neurones. Nous nous focaliserons uniquement sur le code avec Tensorflow.
Le début du code est quasiment le même que précédemment. Il faut simplement modifier la taille des images et normaliser.
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
fashion_mnist = tf.keras.datasets.fashion_mnist
(images_train, targets_train), (images_test, targets_test) = tf.keras.datasets.fashion_mnist.load_data()
targets_names = ["T-shirt", "Pantalon", "Pull", "Robe", "Manteau", "Sandale", "Chemise", "Sneaker", "Sac", "Bottes"]
images_train = images_train.reshape(-1,28,28,1)
images_test = images_test.reshape(-1,28,28,1)
images_train = images_train.astype('float')/255
images_test = images_test.astype('float')/255Architecture du réseau
Nous allons construire un réseau avec deux premières couches de convolution avec un filtre de taille 3 par 3 et 64 neurones. La couche d’après sera une couche de pooling.
Les deux couches suivantes seront des couches de convolution avec 256 neurones. Suivra une couche de pooling encore.
Si vous ne comprenez rien à ce que je raconte, vous pouvez lire mon article sur le sujet.
Avant de gérer la sortie, il faut faire l’opération d’aplanissement car les couche de convolution et de pooling traitent des matrices. J’ai décidé d’ajouter des opérations que l’on appelle dropout. A chaque étape de l’entraînement, nous allons ignorer 30% de neurones choisies de façon aléatoire. Cette technique permet de réduire les risques d’over-fitting.
On ajoutera deux couches denses constituées de 256 et 128 neurones pour l’interprétation. Comme dans le premier modèle, on finit par une couche avec 10 neurones qui correspondra aux 10 catégories.
Construction avec Tensorflow
Le code pour la construction du réseau est le suivant :
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(64, kernel_size=(3, 3),
activation='relu',
input_shape=(28, 28, 1)))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Dense(512, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(512, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))On reprend les mêmes paramètres d’optimisation et de performances :
model.compile(
loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"]
)Nous allons entraîner le modèle sur 15 époques. L’entraînement devrait durer une 5 à 6 minutes.
history = model.fit(images_train,
targets_train,
epochs=15,
validation_split=0.2)Résultats
Au bout d’une époque d’entrainement (40 secondes), nous avons déjà un score de 88,6%.
On peut tracer les courbes d’évolution de la perte et de la précision :
loss_curve = history.history["loss"]
acc_curve = history.history["accuracy"]
loss_val_curve = history.history["val_loss"]
acc_val_curve = history.history["val_accuracy"]
plt.plot(loss_curve, label="Train")
plt.plot(loss_val_curve, label="Val")
plt.legend(loc='upper left')
plt.title("Loss")
plt.show()
plt.plot(acc_curve, label="Train")
plt.plot(acc_val_curve, label="Val")
plt.legend(loc='upper left')
plt.title("Accuracy")
plt.show()Voici les résultats :
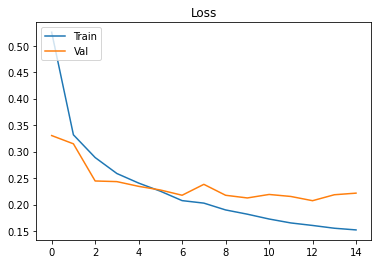
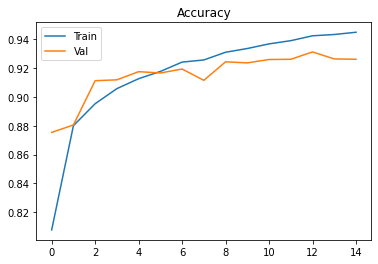
On atteint un score de 92,6%. C’est déjà bien mieux que le premier modèle. Vous pourriez observer de meilleurs résultats encore en prolongeant l’entraînement sur plus d’époques.
loss, acc = model.evaluate(images_test, targets_test)
print("Test Loss", loss)
print("Test Accuracy", acc)Le test sur les données de test donne 92,4% :
313/313 [==============================] - 3s 8ms/step - loss: 0.2409 - accuracy: 0.9246
Test Loss 0.2408551722764969
Test Accuracy 0.9246000051498413
On voit finalement que les CNN donnent de meilleurs résultats et c’est souvent le cas pour l’analyse d’images.
Vous devez noter tout de même que ces données sont déjà nettoyées pour rendre l’apprentissage plus simple. Elle a été constituée à des fins purement pédagogiques mais peut quand même permettre de créer des prototypes de modèles.
Je serais ravi de recevoir vos feedbacks ou vos questions !


Leave a Comment