
La Retrieval-Augmented Generation (RAG) est aujourd’hui l’architecture de référence pour connecter un LLM à vos propres données. Au lieu de tout mettre dans le contexte (solution coûteuse et peu précise) le RAG récupère dynamiquement les passages pertinents au moment de la question.
n8n est un outil d’automatisation no-code / low-code qui supporte nativement les workflows d’agents IA. Il dispose de nœuds dédiés pour les LLMs, les vector stores et permet de connecter des outils facilement via le protocole MCP.
n8n est aujourd’hui une plateforme idéale pour tester et déployer des pipelines RAG rapidement. Dans cet article, nous comparons trois approches pour construire un RAG avec n8n :
- File Search : la solution la plus simple, déléguée entièrement à Google Gemini ou OpenAI.
- Construire un RAG via MCP : une knowledge base managée, connectée à n8n en quelques clics via le protocole MCP.
- Construire un RAG de façon manuelle : deux workflows distincts (ingestion + query) avec Qdrant ou le vector store intégré de n8n.
Ce guide s’adresse aux développeurs/concepteurs d’agents IA qui veulent comprendre les compromis entre simplicité, contrôle et performance de chaque approche.
File Search avec Google Gemini ou OpenAI
La méthode la plus rapide pour faire du RAG dans n8n consiste à déléguer l’indexation et la recherche au service de l’API elle-même. OpenAI propose le tool File Search dans l’API Assistants, et Google Gemini propose une fonctionnalité équivalente via ses outils de traitement de fichiers.
Principe
Dans cette approche, vous uploadez vos fichiers directement chez le fournisseur d’IA. Le modèle les indexe, les découpe en chunks et gère le retrieval de manière transparente. Côté n8n, vous configurez simplement le nœud AI Agent avec le bon outil.
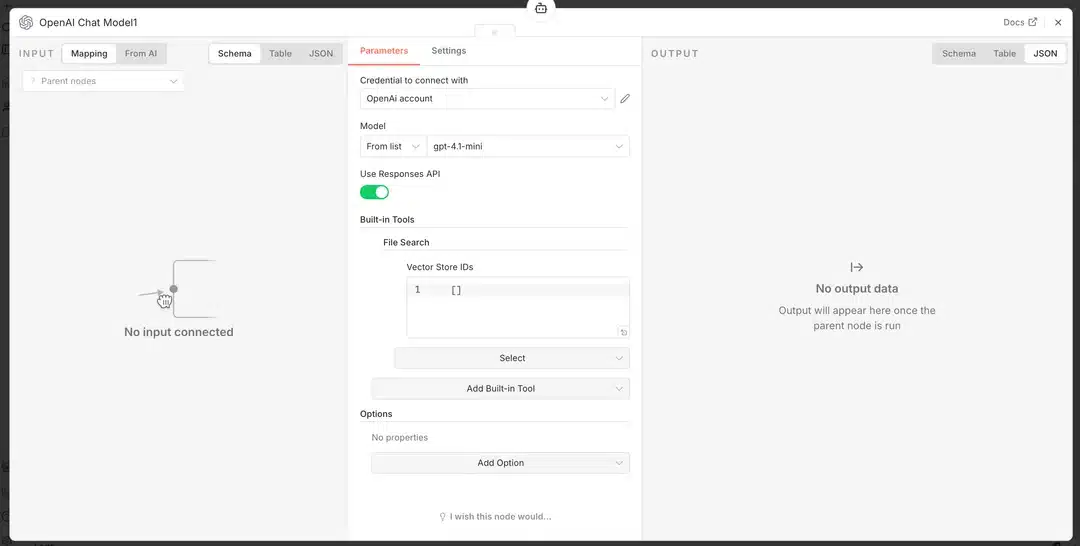
Workflow n8n : OpenAI File Search
Nœuds requis : Trigger → AI Agent → OpenAI Chat Model
1. Ajoutez un nœud « AI Agent »
2. Dans Chat Model, sélectionnez « OpenAI » → gpt-4o ou un autre modèle
3. Dans Tools, activez « File Search »
4. Uploadez vos PDF/DOCX via l'API OpenAI ou le dashboard
(ou utilisez un nœud HTTP Request pour automatiser l'upload)
5. L'agent interroge automatiquement les fichiers lors des questionsWorkflow n8n : Google Gemini
Nœuds requis : Trigger → AI Agent → Google Gemini Chat Model
1. Ajoutez un nœud « AI Agent »
2. Dans Chat Model, sélectionnez « Google Gemini » → gemini-3.5-pro ou un autre modèle
3. Uploadez vos fichiers via l'API Files de Gemini
POST https://generativelanguage.googleapis.com/upload/v1beta/files
4. Passez les file_uri dans le prompt ou via le nœud HTTP Request
5. Gemini extrait le contexte pertinent automatiquementAvantages et limites
Cette solution présente plusieurs avantages notables : elle nécessite zéro configuration de vector store, son workflow est non seulement très court (3 nœuds), ce qui la rend idéale pour prototyper rapidement, et elle bénéficie d’une maintenance nulle côté infrastructure.
Cependant, elle comporte également certaines limites qu’il convient de prendre en compte : les données sont hébergées chez le fournisseur, il n’y a pas de contrôle sur le chunking, le coût est calculé par fichier stocké, et des limites de taille et de format s’appliquent.
Cette approche est particulièrement adaptée aux prototypes, aux démos, ou aux cas où la donnée n’est pas sensible et où vous souhaitez un RAG fonctionnel en moins de 30 minutes.
| Avantages | Limites |
|---|---|
| Zéro configuration de vector store | Données hébergées chez le fournisseur |
| Workflow n8n très court (3 nœuds) | Pas de contrôle sur le chunking |
| Idéal pour prototyper rapidement | Coût par fichier stocké |
| Maintenance nulle côté infra | Limites de taille et de format |
Construire un RAG sur n8n via le protocole MCP
Akyn est une plateforme de knowledge bases optimisées pour les agents IA. Elle expose vos données via le Model Context Protocol (MCP), un standard ouvert qui permet à n’importe quel client compatible (n8n, Claude, Cursor…) de requêter vos documents avec une recherche sémantique.
L’idée est simple : vous créez une knowledge base sur Akyn, vous ingérez vos sources (URLs, PDFs, DOCX, Markdown…), et Akyn s’occupe automatiquement de générer les embeddings vectoriels. Côté n8n, il suffit de connecter un nœud MCP Client à votre endpoint Akyn.

Étape 1 – Créer et alimenter votre knowledge base
- Créez un compte sur akyn.dev
- Créez une nouvelle knowledge base depuis le dashboard
- Ingérez vos sources : collez des URLs, uploadez des PDFs, DOCX, fichiers Markdown
- Akyn génère automatiquement les embeddings — pas besoin de configurer un vector store
- Récupérez votre MCP endpoint :
https://akyn.dev/mcp/[votre-kb-id]
// Exemple d'endpoint MCP Akyn
URL : https://akyn.dev/mcp/[votre-kb-id]
Transport: HTTP Streamable (ou SSE)
Auth : Bearer Token (votre API key Akyn)
// Outils MCP disponibles
query → Recherche sémantique dans la knowledge base
list_sources → Liste tous les documents indexésÉtape 2 – Configurer le workflow n8n
Architecture du workflow : Trigger → AI Agent (Chat Model + MCP Client)
1. Créez un AI Agent workflow
Ajoutez un nœud Trigger (Chat, Webhook, Schedule…), puis un nœud AI Agent. Connectez-le à un Chat Model de votre choix (OpenAI, Anthropic, Gemini).
2. Ajoutez un nœud MCP Client comme Tool
Dans le nœud AI Agent → section Tools :
Cliquez sur « Add Tool » → MCP Client
Configuration du nœud MCP Client :
Endpoint : https://akyn.dev/mcp/[votre-kb-id]
Server Transport : HTTP Streamable
Authentication : Bearer Auth
Tools to Include : All3. Ajoutez votre clé API Akyn
Cliquez sur l'icône crayon à côté de « Credential for Bearer Auth »
Créez un nouveau credential :
Token : [votre API key depuis le Dashboard Akyn → Settings]4. Testez la connexion
Cliquez sur « Execute step » sur le nœud MCP Client. Si la connexion est établie, vous verrez les outils query et list_sources disponibles. Votre AI Agent peut maintenant interroger votre knowledge base Akyn.
Knowledge bases multiples : Pour interroger plusieurs knowledge bases, ajoutez simplement plusieurs nœuds MCP Client dans le même AI Agent, chacun pointant vers un endpoint Akyn différent. L’agent choisira automatiquement le bon outil selon la question.
Idéal pour : les équipes qui veulent un RAG production-ready rapidement, sans gérer d’infrastructure vector store, avec la possibilité de partager ou monétiser leurs knowledge bases.
Technique 3 – RAG manuel avec Qdrant (ou le vector store n8n)
La troisième approche donne un contrôle total sur chaque étape du pipeline RAG. Elle repose sur deux workflows distincts : un workflow d’ingestion et un workflow de query. C’est la solution la plus flexible — mais aussi la plus complexe à mettre en place.
Pour le vector store, vous avez deux options : Qdrant, une base vectorielle open-source très performante, ou le vector store intégré de n8n (In-Memory Vector Store), parfait pour les cas simples sans infrastructure externe.

Workflow 1 – Ingestion des documents
Architecture : Trigger → Lire Document → Text Splitter → Embeddings → Vector Store
- Trigger : déclenchez l’ingestion manuellement, via un webhook, ou en surveillance d’un dossier Google Drive/S3.
- Lire le document : nœud « Read Binary File » ou « Google Drive » pour récupérer le fichier (PDF, DOCX, TXT…).
- Document Loader : nœud « Default Data Loader » pour extraire le texte brut.
- Text Splitter : nœud « Recursive Character Text Splitter » — configurez la taille des chunks (ex. 500 tokens) et l’overlap (ex. 50 tokens).
- Embeddings : nœud « OpenAI Embeddings » (text-embedding-3-small) ou « Google Gemini Embeddings ».
- Vector Store : nœud « Qdrant Vector Store » (mode Insert) ou « In-Memory Vector Store ».
// Configuration Qdrant dans n8n
Host : http://localhost:6333 (ou votre instance cloud)
Collection : ma-knowledge-base
Vector Size : 1536 (OpenAI text-embedding-3-small)
Distance : Cosine
// Lancer Qdrant en local avec Docker
docker run -p 6333:6333 qdrant/qdrantWorkflow 2 – Query (RAG au moment de la question)
Architecture : Trigger (Chat) → AI Agent → Tool: Vector Store Retriever → Chat Model
- Trigger Chat : nœud « Chat Trigger » pour recevoir la question de l’utilisateur.
- AI Agent : le cerveau du workflow, il décide quand utiliser le retriever.
- Tool – Vector Store Retriever : nœud qui effectue la recherche sémantique dans Qdrant. Configurez le nombre de résultats (topK : 3 à 5).
- Embeddings : même modèle d’embeddings que lors de l’ingestion — c’est critique.
- Chat Model : le LLM (GPT-4o, Claude, Gemini) qui synthétise les chunks récupérés pour formuler la réponse.
// Paramètres recommandés du Vector Store Retriever
Top K : 4 (nombre de chunks récupérés)
Score Min : 0.7 (filtrer les résultats peu pertinents)
// System prompt suggéré pour l'AI Agent
"Tu es un assistant expert. Utilise l'outil de recherche pour
trouver des informations pertinentes avant de répondre.
Cite tes sources quand c'est possible."Vector store intégré n8n vs Qdrant
| Critère | n8n In-Memory | Qdrant |
|---|---|---|
| Persistance | ❌ Perdu au redémarrage | ✅ Persistant |
| Scalabilité | ⚠️ Limité à la RAM | ✅ Haute performance |
| Setup | ✅ Aucun | ⚠️ Docker ou cloud |
| Filtrage | Basique | Avancé (metadata) |
| Usage idéal | Tests / prototypes | Production |
Avantages et limites
| ✅ Avantages | ⚠️ Limites |
|---|---|
| Contrôle total sur le chunking | 2 workflows à maintenir |
| Aucune dépendance externe pour les données | Infrastructure Qdrant à gérer |
| Filtrage avancé par metadata | Temps de mise en place plus long |
| Scalable pour de grands corpus | Pas de mise à jour automatique des sources |
| Open-source et auto-hébergeable |
Idéal pour : les projets production avec de grands volumes de données, des besoins de filtrage avancé, ou des contraintes de souveraineté des données (on-premise).
Comparatif des 3 approches
| Critère | File Search | Akyn MCP | RAG Manuel |
|---|---|---|---|
| Facilité de setup | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ |
| Contrôle | ⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Mise à jour sources | Manuelle | Automatique | Manuelle |
| Infra à gérer | Aucune | Aucune | Qdrant / n8n |
| Données hébergées | OpenAI / Google | Akyn (cloud) | Vous |
| Personnalisation RAG | Limitée | Bonne | Totale |
| Coût variable | Par fichier | Par query | Embeddings seuls |
| Idéal pour | Prototype | PME / Équipes | Enterprise |
Conclusion
Ces trois techniques ne sont pas en compétition : elles répondent à des contextes différents. Voici notre recommandation en fonction de votre situation :
Vous voulez tester en 30 minutes → Technique 1 (File Search). Quelques nœuds, aucun setup, résultats immédiats. Parfait pour valider votre cas d’usage.
Vous êtes une équipe qui veut du RAG en production sans gérer d’infra → Technique 2 (Akyn MCP). Setup en 5 minutes, knowledge bases gérées, mises à jour automatiques des embeddings, et possibilité de partager ou monétiser votre knowledge.
Vous avez des contraintes de données sensibles ou besoin de contrôle total → Technique 3 (RAG Manuel + Qdrant). Plus complexe à mettre en place, mais aucune dépendance externe pour vos données.
Si vous voulez explorer la Technique 2 plus en détail, la documentation d’Akyn est disponible sur akyn.dev/docs. Vous y trouverez notamment le tutoriel dédié à la connexion n8n ↔ Akyn.


Laisser un commentaire