
Le LLMOps est une discipline qui adapte les principes du MLOps pour gérer l’intégralité du cycle de vie des applications basées sur les LLM.
Son objectif est de rationaliser et de standardiser les processus complexes de développement, de déploiement et de surveillance des LLM. Cela permet d’assurer l’efficacité opérationnelle et la scalabilité des solutions mises en place.
Le LLMOps est ce qui permet de transformer les capacités brutes des modèles en applications robustes et dignes de confiance.
Quelle est la différence entre le LLMOps, le MLOps et le DevOps ?
L’émergence du LLMOps est une réponse à l’insuffisance des paradigmes précédents.
On a observé l’évolution des pratiques d’ingénierie logicielle, allant du DevOps centré sur le code source. A l’émergence du MLOps intégrant les données et les modèles d’apprentissage automatique. Pour finalement aboutir au LLMOps, spécifiquement adapté aux défis des grands modèles de langage.
Avec les LLM, l’attention se déplace vers la gestion des prompts, des modèles de fondation et des vecteurs. Tandis que les risques évoluent pour inclure les hallucinations, l’injection de prompt et l’optimisation du coût d’inférence.
Cette transition souligne la nécessité d’outils et de méthodologies spécialisés pour assurer le déploiement, la surveillance et la maintenance des applications basées sur l’IA générative.

Les défis uniques du LLMOps
Le LLMOps est nécessaire pour gérer des défis qui n’existent pas en MLOps traditionnel :
- Non-déterminisme et variabilité. Les LLM sont fondamentalement non déterministes, ce qui complexifie les tests logiciels traditionnels comme les tests de régression.
- Hallucinations et fiabilité : Les LLM peuvent générer des informations factuellement incorrectes avec confiance. Le LLMOps doit donc intégrer des mécanismes de détection et de vérification des faits (via un RAG, par exemple).
- La nouvelle pile d’artefacts : Le LLMOps doit gérer de nouveaux éléments critiques :
- Les prompts : L’ingénierie des prompts est essentielle ; les prompts doivent être versionnés et testés comme du code.
- Les données vectorielles : Les bases de données vectorielles sont une composante d’infrastructure de premier niveau.
- L’économie de l’inférence contre l’entraînement : contrairement à ce que l’on pense, le coût principal réside dans l’inférence (génération de tokens en production), et non dans l’entraînement du modèle.
- Nouvelles surfaces d’attaque : Le LLMOps doit faire face à des menaces spécifiques comme la prompt injection (manipulation du modèle via l’entrée utilisateur) et la fuite de données sensibles (mémorisation ou divulgation via le contexte ou l’entrée utilisateur).
Quelles sont les différentes phases du LLMOps ?
Le cycle de vie LLMOps se décompose en quatre phases principales : développement, personnalisation, déploiement et monitoring.
Développement
Cette phase initiale se concentre sur la gestion des données et des prompts :
- Gestion des données : Inclut la collecte, le nettoyage, l’étiquetage (pour le fine-tuning), le versioning et, si nécessaire, le formattage des données pour les pipelines de RAG (ingestion, chunking, vectorization vers une base de données vectorielle).
- Gestion des prompts : Le prompt est un composant critique qui doit être rigoureusement versionné, soumis à des tests (A/B testing de prompts) et dont le déploiement doit être rapide, souvent sans redéploiement complet de l’application.
Personnalisation des modèles
La personnalisation des modèles pour un cas d’usage spécifique se fait principalement via deux techniques. Le RAG et le fine-tuning (l’ajustement des LLM).
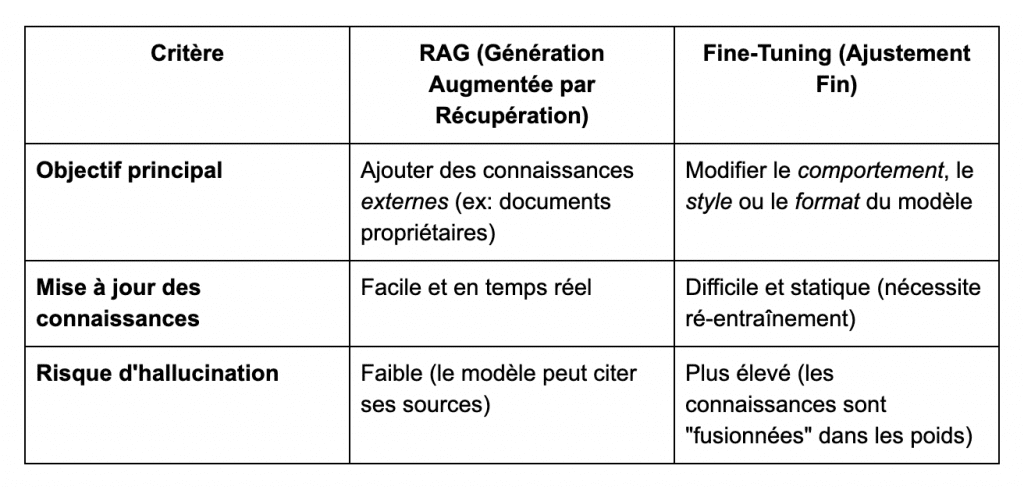
La méthode RAG consiste à enrichir les réponses du modèle avec des connaissances externes. Ces connaissances sont souvent issues de documents propriétaires, ce qui permet une mise à jour rapide et dynamique des informations.
Elle présente l’avantage de réduire le risque d’hallucinations, car le modèle peut appuyer ses réponses sur des sources explicites.
À l’inverse, le fine-tuning modifie en profondeur le comportement ou le style du modèle. Il y intégre de nouvelles connaissances directement dans ses poids.
Cette méthode, bien que plus puissante pour transformer le modèle, est plus coûteuse. Et elle est sujette à un risque accru d’hallucinations, car les connaissances sont internalisées sans possibilité de vérification explicite.
Déploiement et inférence
Cette phase est axée sur la fiabilité et la viabilité économique du modèle en production. L’optimisation de l’inférence est une exigence de base du LLMOps et pour la mise en place de solutions d’IA générative fiable :
- Optimisation de l’inférence : Utilisation de techniques pour réduire les coûts et la latence, telles que la quantification (réduction de la précision numérique), la mise en cache (KV caching) (pour l’inférence conversationnelle) et le batching continu (pour maximiser le débit GPU).
- Gestion des coûts : Mise en place de la mise en cache des requêtes (pour les prompts identiques), du routage de modèles (vers un modèle moins cher pour les requêtes simples) et du suivi des coûts.
Monitoring et évaluation
La phase de monitoring est la phase la plus critique pour l’amélioration continue des produits basés sur des LLM. Elle comporte la partie suivi, la parti évaluation et la collecte puis le traitement des feedbacks des utilisateurs su service :
- Monitoring : Nécessite le suivi des métriques opérationnelles (latence, coût par token), des métriques de qualité des données (dérive des données d’entrée/RAG) et des métriques de qualité du modèle (score d’hallucination, toxicité, biais).
- Évaluation : Les métriques NLP traditionnelles sont inefficaces. Les nouvelles approches incluent le LLM-as-a-Judge (utilisation d’un LLM puissant pour noter la sortie) et les golden datasets.
- Boucle d’amélioration continue : Elle consiste à capturer le feedback utilisateur (explicite ou implicite) et à le réinjecter dans le système. Ces corrections deviennent des nouvelles données d’entraînement pour le fine-tuning ou des mises à jour pour la base de données RAG, transformant l’utilisation en un pipeline de R&D continu.
LLMOps et observabilité
Cette phase de monitoring est souvent appelée observabilité dans le cadre du LLMOps.
L’observabilité permet de comprendre, d’expliquer et de fiabiliser des systèmes fondamentalement non déterministes.
Contrairement aux applications classiques, un agent IA ou un LLM peut produire des réponses différentes à partir des mêmes entrées, appeler plusieurs modèles, invoquer des outils ou chaîner des API, ce qui rend l’exécution difficile à suivre sans instrumentation dédiée.
Une stack d’observabilité moderne doit donc capturer chaque étape du raisonnement du modèle (le tracing), le contenu des prompts et sous-prompts, les appels d’outils, les scores d’évaluation automatique (LLM-as-a-Judge) et les métriques opérationnelles (latence, coût/token, dérive des données).

Des solutions comme LangSmith, Weights & Biases ou Honeycomb rendent possible cette visibilité fine. L’observabilité est essentielle pour détecter les hallucinations, comprendre les échecs, optimiser le modèle routing et améliorer continuellement l’expérience utilisateur.
Sans observabilité, aucune scalabilité réelle n’est possible : on ne peut ni diagnostiquer, ni contrôler, ni reproduire, donc on ne peut pas industrialiser.
Conclusion
Le LLMOps n’est pas un simple prolongement du MLOps : c’est un nouveau paradigme opérationnel imposé par l’arrivée des LLM.
Il apporte les outils nécessaires pour rendre les systèmes d’IA générative réellement exploitables : stabilité, sécurité, contrôle, optimisation de coût et boucle d’amélioration continue.
Un autre sujet important en matière de LLMOps concerne les protocoles de communication entre agents, comme Agent2Agent ou encore entre un agent et des outils, comme les MCP.
À mesure que les entreprises passent des POC aux produits, c’est cette discipline qui fera la différence entre une IA gadget… et une IA qui crée de la valeur.



Article hyper intéressant, merci pour le partage !
Hâte de lire plus d’articles à ce sujet 🙂