

A l’occasion du 1er avril, je me suis permis de prétendre que je devenais le ‘Head of AI content’ de la fameuse marque Balenciaga, et d’annoncer en grande pompe un partenariat entre la marque de luxe et le monde d’Harry Potter avec une vidéo soignée — sur une idée originale du créateur demonflyingfox.
Pensant que ma supercherie était vraiment beaucoup trop grosse pour être vraie, j’ai pourtant reçu nombre de félicitations… Pourtant, tout était absolument généré par une IA, le script, la vidéo, les images, l’animation des avatars, les voix des personnages.
Au delà du côté ludique et, avouons-le, un tantinet provocateur de ce poisson d’avril, c’était avant tout la parfaite occasion pédagogique pour nous de montrer en conditions réelles comment utiliser la panoplie des outils génératifs, et les enjeux éthiques associés
Je découperais donc l’article en deux axes:
1/ Tuto: montrer toute la panoplie des outils disponibles en matière de Generative AI qui peuvent vous permettre de créer une vidéo d’un avatar animé qui s’exprime, et ce de A à Z par vous-mêmes
2/ Analyse: partager quelques réflexions en fin de ce tuto sur les questions et implications éthique de ces outils très sophistiqués qui auraient faire pâlir d’envie Edward Bernays
Etre informé sur le monde technologique qui nous entoure, c’est aussi mieux être mieux armé pour tenter d’apporter un éclairage lucide et critique du fonctionnement de ces IA multi-modales.
Nous allons vous guider à travers les étapes simples pour décomposer le processus de création de cette vidéo ci-dessus, qui est entièrement fake.
Rendons à César ce qui est à César, l’idée de mixer l’univers de Balenciaga avec celui du monde de J.K Rowling, vient de cette brillante idée de l’AI-artist (demonflyingfox) – que je trouve très mordant et efficace.
Ce dont vous avez besoin avant d’aller plus loin:
- un générateur d’image AI-art (Midjourney, DreamStudio, Scenario — voir plus de détails)
- un compte gratuit chez play.ht
- un compte gratuit chez D-ID
- un outil gratuit super pratique comme Clip Interrogator
Etape 1: Image-To-Prompt
objectif: Trouvez le bon prompt qui permettra de créer notre personnage
Outils utilisés lors de cet étape:
Je vais tout bonnement commencer par faire une capture d’écran d’un des personnages stylés dans la vidéo, prenons par exemple ce Dumbledore total new-look dans le pur jus de Balenciaga.

On va passer cette image dans clip interrogator — ICI
Grosso modo, CLIP nous permet de traduire via une IA le contenu d’une image en mots. Vous lui donnez une image, il vous dit quel serait le “prompt” correspondant à utiliser dans un générateur d’AI-art comme Dall-E ou Stable diffusion etc si vous souhaitiez recréer l’image.
Pour plus de détails sur CLIP, je fais une aparté en fin de cet article. honnêtement c’est sans doute l’outil le plus sous-côté/méconnu du grand public, alors qu’il est absolument fondamental dans les progrès des algos Text-To-Image
Donc dans notre exemple
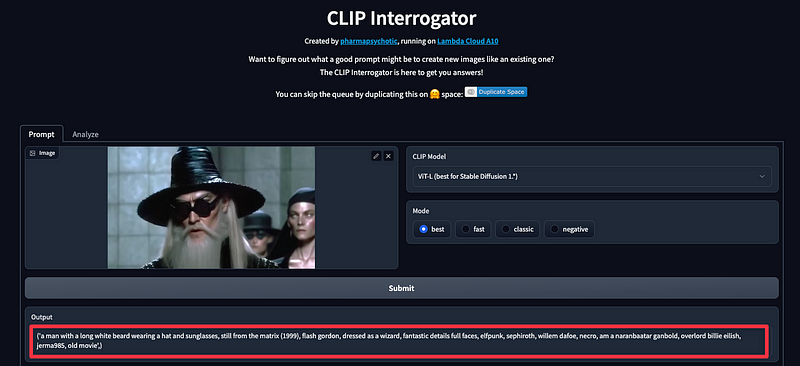
Voila un prompt que nous propose un CLIP, que nous allons nous empresser de copier/coller dans un bloc-note
a man with a long white beard wearing a hat and sunglasses, still from the matrix (1999), flash gordon, dressed as a wizard, fantastic details full faces, elfpunk, sephiroth, willem dafoe, necro, am a naranbaatar ganbold, overlord billie eilish, jerma985, old movie
Etape 2: Text-To-Image
Objectif: Générez l’image de notre personnage fictif, qui servira de base pour une animation vidéo future.
Outils utilisés lors de cette étape:
Ouvrons notre générateur d’AI-art, dans le cas échéant Midjourney. Si c’est la première fois pour vous que vous utilisez cette plateforme, lisez d’abord ce quick start guide de Midjourney pour pasgalérer sur votre set-up.
On se rend sur discord, on tape /imagine et on copie colle notre prompt donné par CLIP lors de l’étape 1

notez que je rajoute quelques paramètres à la fin du prompt — ar 2:1 — q 2 — s 750 — v 5. Ce sont des paramètres qui me permettent de mieux gérer l’aspect visuel de mon image qui sera générée, pour aller plus loin c’est ici.
Ok voyons le résultat.

OK on a notre dumbledore new-look.
Vous pouvez aussi essayer la prompt alternative suivante, si vous souhaitez donner un grain un peu plus dark et vintage à votre Dumbledore.

Bon ici vous pouvez prendre n’importe quelle image hein, pas forcément obligé d’utiliser Midjourney, vous pourriez tout à faire un screenshot d’une image d’un personnage dans une vidéo youtube.
Etape 3: Text-To-Speech
objectif: Créer le script + la voix de notre personnage fictif
Outils utilisés lors de cette étape:
A présent on va utiliser les fonctionnalités de play.ht pour créer le fichier audio.
En express, Play.ht est un service en ligne qui convertit du texte en audio grâce à la synthèse vocale. Il utilise des voix artificielles avancées pour lire des articles, des histoires ou d’autres types de contenu écrit, afin que tu puisses les écouter plutôt que de les lire.
On va sélectionner une voix synthétique d’IA, et lui faire dire notre texte/script.
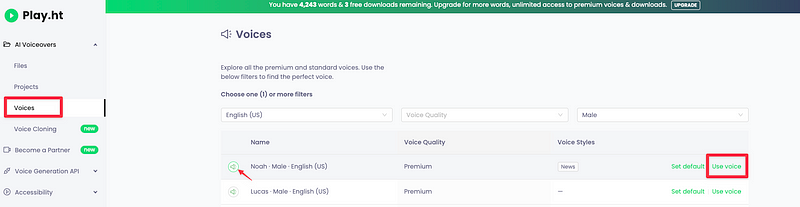
A présent familiarisez vous un peu avec l’interface suivante. Dans notre cas, on va copier-coller une des citations de Dumbledore (source)

Avec l’outil de pré-écoute, on peut apprécier la diction de notre voix-off et l’affiner au besoin. Mais vu que c’est un compte gratuit, soyez parcimonieux avant de télécharger le résultat final de votre audio.
Nous n’avons plus qu’à télécharger notre fichier .mp3.


Etape 4: (Image+Speech)-To-Video
objectif: Mixer l’image et la voix de notre personnage fictif pour créer un rendu vidéo animé avec un avatar qui parle
Outils utilisés lors de cet étape:
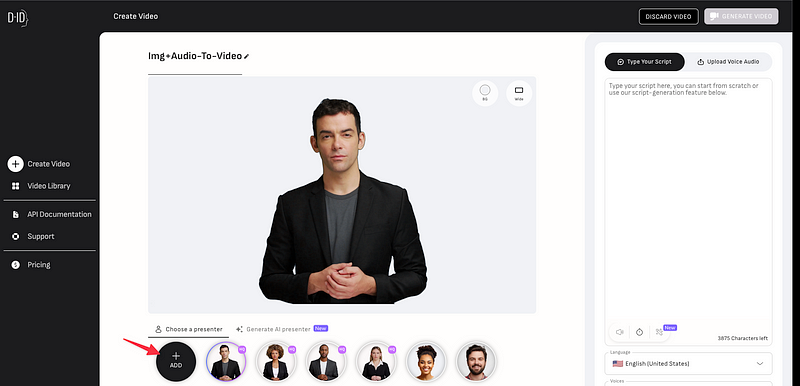
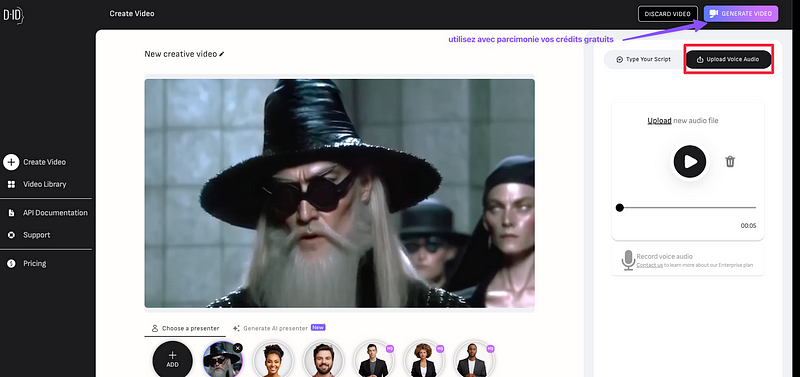
A présent, rendons nous sur notre compte D-ID (je suis personnellement en essai gratuit). D-ID est une application web qui utilise l’animation faciale en temps réel et la synthèse vocale avancée pour créer une expérience d’IA conversationnelle immersive et réaliste. En somme, c’est un outil d’IA générative pour créer des avatars parlants en quelques clicks.
On va faire une nouvelle vidéo, et commencez par importer notre image créée lors de l’étape 2.
A présent, on va uploader notre voix créée lors de l’étape 3.
Notez que vous pouvez aussi tout à fait utiliser les pre-sets existants de voix dans D-ID, c’est juste que je trouve ça un peu cher et pas forcément très flexible.
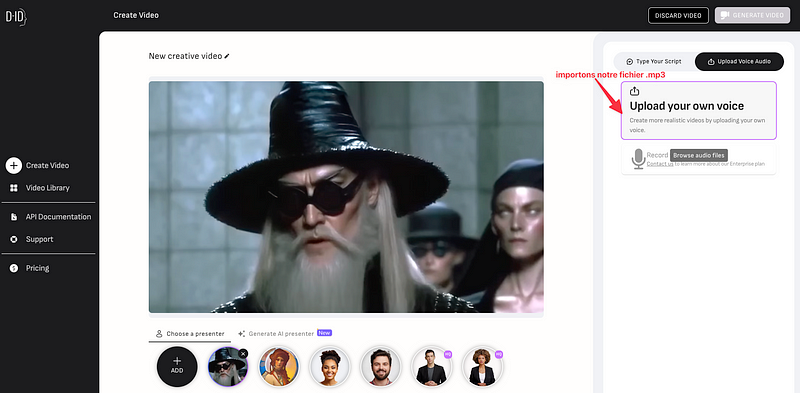
on upload notre fichier audio, pour moi c’est le fichier Dumbledore Balenciaga Audio Script.mp3
Et plus qu’à cliquer sur generate Video, et exportez votre résultat final, une vidéo .mp4 avec votre avatar parlant.
Récap
On aura donc successivement en moins de 5min:
- généré une prompt à partir d’une image cible
- reproduit cette image cible dans midjourney
- généré une voice-over avec un texte personnalisé
- synchronisé la voice-over avec notre image pour créer une vidéo (ou notre Dumbledore nous troll superbement d’ailleurs)
Pour aller plus loin
Réflexions éthiques: le Generative AI, Edward Bernays et la fabrique du consentement
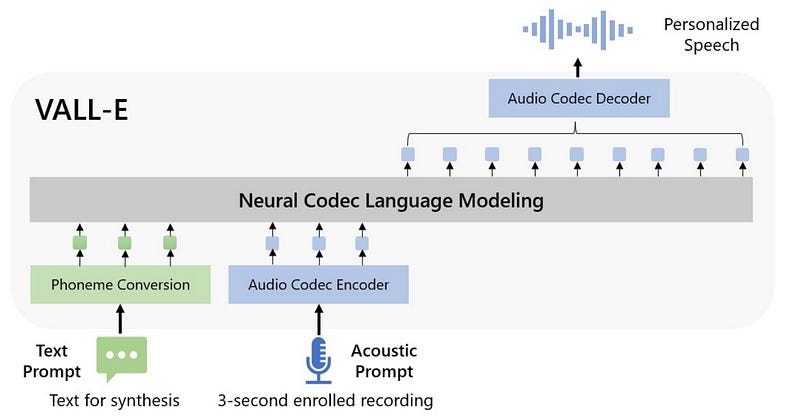
Ce qui est intéressant à observer dans cette expérimentation, c’est qu’il est aisé de créer un contenu réaliste et faire dire ce qu’on veut à à peu près n’importe qui. J’aurais pu tout à fait également cloner la voix de n’importe qui à partir de 60 secondes d’audio, pour utiliser la voix de christopher lee ou celle de Steve Jobs — les études de Vall-E montrent que nous sommes également en train de passer un cap dans ce domaine.
De tels outils posent nécessairement la question de la limite de leurs utilisations face à leur capacités à modeler le consentement du public.
Et c’est bien la ou je souhaite en venir.

Dans son livre “Propaganda” (1928), Bernays, considéré comme le père des relations publiques modernes mais aussi au passage neveu d’un certain Sigmund Freud, soutient que le consentement du public peut être “fabriqué” ou “manipulé” par des experts en communication et en relations publiques des masses.
La thèse de Bernays est que des personnes “invisibles” qui créent le savoir et la propagande règnent sur les masses, avec le monopole du pouvoir de façonner les pensées, les valeurs et les réactions des citoyens. Selon lui, il serait alors nécessaire d’avoir un “consentement technique” — ou “engineering consent” qui signifie influencer l’opinion publique en utilisant des techniques de communication et de persuasion pour façonner les perceptions, les attitudes et les comportements des individus. Bernays voyait cette approche comme un outil nécessaire pour maintenir l’ordre social et la stabilité, étant donné que les gens sont souvent influencés par des forces irrationnelles et émotionnelles. Tout un programme donc pour ce cher Edward Bernays.
Je pense qu’il est intéressant en tout cas de percevoir à quel point ces outils d’IA génératives, qui ne sont que des artefacts, peuvent rapidement être prise à leur compte par des visées de propagande, et bien entendu pose la légitime question du copyright que ce soit pour les images ou la voix.
Si l’on fait un parallèle entre la thèse de Bernays à l’aune du Generative AI on peut donc au moins dénoter deux facteurs amplificateurs de chaos dans la manipulation du consentement du public:
💥 Premier facteur de Chaos : l’IA permet de diminuer les coûts des 3 types d’opérations indispensables à une propagande efficace : il est possible de simuler des auteurs instantanément et même d’usurper leur identité, de simuler leur succès (en générant de faux commentaires crédibles ou des reprises d’informations par de faux utilisateurs) et, bien entendu, de produire du contenu automatiquement.
💥 Deuxième facteur de Chaos : affaiblir la confiance dans le système en instaurant un doute constant. Plutôt que de provoquer l’adhésion à des fausses convictions, semer l’incertitude est souvent le premier but des propagandistes. Avec l’évolution de l’IA, tout le monde se demandera si un message particulier pourrait être inauthentique ou trompeur.
Je vous invite à aller plus loin en consultant cette étude captivante, pédagogique et mesurée, réalisée des chercheurs d’OpenAI (développeurs de ChatGPT), en collaboration avec le “Georgetown’s Center for Security and Emerging Technology” et le “Stanford Internet Observatory”, ont réalisé des études pour identifier les dangers et établir les fondements d’un débat sur les régulations envisageables.
En tout cas, j’espère que cela vous apporte un peu d’esprit critique et de mises en perspective de plus en plus nécessaire sur l’utilisation de ces outils.
Pur aller plus loin:
- https://davidrozado.substack.com/p/political-bias-chatgpt
- https://arxiv.org/abs/2301.04246
- https://youtu.be/8OpW5qboDDs
Aparté:
Quel est le point commun entre les récentes percées de l’IA, DALL-E et de stable diffusion ?
Elles utilisent toutes deux des éléments de l’architecture CLIP. Par conséquent, pour comprendre le fonctionnement de ces modèles, il est indispensable de comprendre CLIP.
D’ailleurs, CLIP a été utilisé pour indexer des photos sur Unsplash.
Mais que fait CLIP et pourquoi est-ce une étape importante pour la communauté de l’IA ?
CLIP est l’acronyme de Constastive Language-Image Pretraining :
CLIP est un modèle open source, multimodal et sans prise de vue. Étant donné une image et des descriptions textuelles, le modèle peut prédire la description textuelle la plus pertinente pour cette image, sans optimiser pour une tâche particulière.
Décortiquons cette description :
- Open Source: Le modèle est créé et mis à disposition par OpenAI.
- Multi-modalité : les architectures multimodales exploitent plus d’un domaine pour apprendre une tâche spécifique. CLIP combine le traitement du langage naturel et la vision par ordinateur.
- Zero-shot : L’apprentissage à partir de zéro est un moyen de généraliser sur des étiquettes inédites, sans avoir été spécifiquement entraîné à les classer. Par exemple, tous les modèles ImageNet sont formés pour reconnaître 1000 classes spécifiques. CLIP n’est pas soumis à cette limitation.
- Langage contraignant : Avec cette technique, CLIP est entraîné à comprendre que les représentations similaires doivent être proches de l’espace latent, tandis que les représentations dissemblables doivent en être éloignées.



Laisser un commentaire