
Nous allons explorer dans cet article les fondamentaux de LangChain, devenu aujourd’hui la bibliothèque de référence pour quiconque s’intéresse aux modèles de langage (LLMs), aux agents autonomes et à leur déploiement dans le monde professionnel.
Bien loin de ses débuts expérimentaux, LangChain est désormais un framework mature et incontournable. Il offre un écosystème riche permettant de construire des applications robustes, des systèmes RAG (Retrieval Augmented Generation) et des outils complexes.
Il s’interface aussi bien avec les modèles propriétaires (comme GPT-4o ou Claude 3.5) qu’avec les modèles open-source (Llama 3, Deepseek, etc.).
Quelles sont les applications de LangChain ?
Le framework s’est imposé comme le standard pour orchestrer presque tous les types d’applications d’IA génératives :
- Systèmes de RAG : Discutez avec vos propres données privées (PDF, Notion, Drive, SQL) en citant les sources exactes, sans jamais entraîner le modèle.
- Agents et copilotes intelligents : Création d’assistants capables non seulement de répondre, mais d’utiliser des outils (rechercher sur le web, envoyer un mail, utiliser une calculatrice) pour accomplir des tâches complexes.
- Extraction de données structurées : Transformer des données non structurées (emails, factures, longs rapports) en formats exploitables (JSON, CSV, bases de données).
- Analyse de données tabulaires : Interroger vos fichiers Excel/CSV ou vos bases de données SQL en langage naturel pour générer des rapports et des graphiques.
- Synthèse et résumé avancé : Traiter des volumes de textes massifs dépassant la fenêtre contextuelle standard des modèles.
- Assistants de code : Création d’outils capables de comprendre, debugger ou générer du code au sein de votre IDE.
La liste continue de s’allonger avec l’arrivée de la multimodalité (gestion des images et de l’audio) et des architectures basées sur des graphes (via LangGraph).
L’histoire de LangChain
Les grands modèles de langage, ou LLM, se sont imposés sur la scène mondiale avec la publication de GPT-3 par OpenAI en 2020.
Depuis, leur popularité n’a cessé de croître, notamment avec le couronnement de ChatGPT en décembre 2022 qui a propulsé cette technologie sous les feux des projecteurs.
L’intérêt pour les LLM et la discipline plus large de l’IA générative a littéralement explosé.
Ce progrès fulgurant a redéfini le paysage technologique en quelques années seulement, comme on peut le voir ci-dessous :

LangChain s’est positionné précisément à cette intersection critique où la puissance des modèles est devenue suffisamment mature pour le développement applicatif.
En d’autres termes, là où des acteurs comme OpenAI ont rendu l’intelligence accessible via des API, LangChain a construit le pont indispensable entre ces « cerveaux » et vos applications concrètes.
Ce rôle de connecteur universel est aujourd’hui essentiel, que vous utilisiez des modèles propriétaires comme GPT-5 ou que vous préfériez héberger vos propres modèles open source, tels que ceux de la famille Llama, Deepseek ou Mistral.
La philosophie de LangChain
La philosophie de LangChain est résumé par son fondateur Harrison Chase comme suit :
LangChain est un framework destiné au développement d’applications alimentées par des modèles de langage. Nous sommes convaincus que les applications les plus puissantes et les plus innovantes ne se contenteront pas d’interroger un modèle via une API, mais devront également :
- Être connectées aux données (data-aware) : relier le modèle de langage à d’autres sources de données externes.
- Être agentiques (agentic) : permettre au modèle de langage d’interagir avec son environnement.
Le framework LangChain a été conçu en gardant ces principes fondamentaux à l’esprit.
Ce qui est intéressant de prime abord, c’est ce parti pris très affirmé, les applications les plus radicales de demain utiliseront des modèles de language via API, et ces modèles de language pourront se renforcer:
- en “apprenant” de nouvelles sources de données non-vues lors de leur entraînement, mais aussi se connecter à d’autres flux de données via API
- en “augmentant” leurs capacités en étant capable d’utiliser de nouveaux outils et d’interagir avec son propre environnement de données – le concept d’agents si cher à LangChain, que nous verrons en détail lors de cet article
Si on fait un schéma, LangChain vient donc pouvoir s’interfacer avec de nouvelles données et vous permet de construire vos applications en unifiant le tout sous la bannière d’un modèle de language.
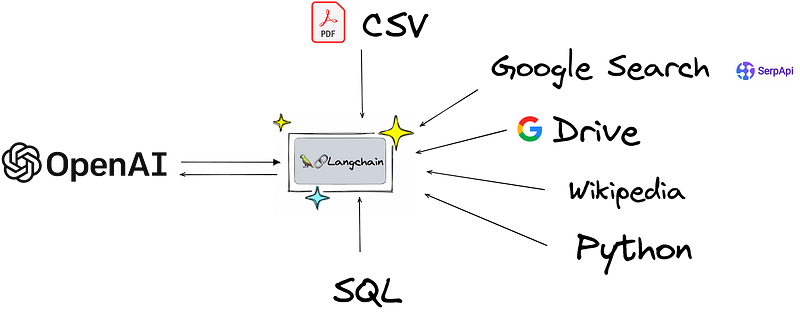
Les concepts fondamentaux de LangChain
Comme vu en introduction, LangChain permet de dépasser le simple chatbot pour créer des applications complexes. L’idée centrale est de pouvoir assembler (« chaîner ») différents composants via une syntaxe unifiée (le LCEL).
Si le framework est vaste, trois piliers soutiennent la majorité des applications :
Concept fondamental #1 : model I/O et prompts
Il ne s’agit plus seulement d’envoyer du texte, mais de structurer les interactions.
LangChain permet de gérer des Templates de Chat (rôle système, utilisateur, IA) et de formater les réponses des modèles pour obtenir non plus juste du texte, mais de la donnée structurée (JSON) directement exploitable par votre code.
Concept fondamental #2 : retrieval (RAG)
C’est le pont entre le LLM et vos données. Ce module permet de charger vos documents (PDF, CSV, Web), de les découper et de les stocker dans des bases vectorielles.
Le modèle peut ainsi aller « chercher » l’information pertinente avant de répondre, garantissant des réponses basées sur vos faits et non sur ses hallucinations.
Concept fondamental #3 : chaînes et agents
C’est ici que la magie opère. Une chaîne est une séquence d’actions prédéfinie (ex: récupérer un document, le résumer, puis le traduire).
Un agent, lui, est plus autonome : il utilise le LLM comme un cerveau pour raisonner. Il décide seul quelles actions entreprendre (faire une recherche web, calculer un chiffre, consulter une base de données) et dans quel ordre pour répondre à votre demande.
Dans la partie suivante, nous allons voir des exemples d’implémentation en python pour ces 3 concepts fondamentaux.
Concept #1 : les prompts dans Langchain
Commençons par un exemple simple pour mettre en place un template de prompt et interagir avec un modèle moderne comme GPT-4o ou GPT-5.
Tout d’abord, installons les bibliothèques nécessaires. LangChain est désormais modulaire, nous avons donc besoin du package principal et du connecteur OpenAI :
!pip install langchain langchain-openaiLa syntaxe LCEL
Dans les anciennes versions de LangChain, on utilisait une classe LLMChain. Aujourd’hui, on utilise une syntaxe beaucoup plus élégante et pythonique appelée LCEL (LangChain Expression Language) qui utilise le symbole | (pipe) pour chaîner les opérations.
Voici comment créer votre première interaction :
import os
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# 1. Configuration de la clé API (Variable d'environnement)
os.environ['OPENAI_API_KEY'] = 'votre-clé-api-ici'
# 2. Création du Modèle (ChatModel)
# Nous utilisons ChatOpenAI qui est optimisé pour la conversation
llm = ChatOpenAI(model_name="gpt-5")
# 3. Création du Template
template = """
Question de l'utilisateur : {question}
Réponse :
"""
prompt = PromptTemplate.from_template(template)
# 4. Création de la Chaîne (Syntaxe LCEL)
# C'est ici que la magie opère : Prompt -> Modèle
chain = prompt | llm
# 5. Exécution
reponse = chain.invoke({"question": "Qui a gagné la coupe du monde 2022 au Qatar ?"})
print(reponse.content)Dans l’exemple ci-dessus, on injecte dynamiquement le champ question dans le prompt. Le symbole | agit comme un tuyau : la sortie du prompt est envoyée directement dans le LLM. C’est simple, mais c’est la base de tout l’écosystème.
Prompt avec contexte
Voyons un prompt un peu plus complexe. Souvent, vous voudrez que le modèle ne réponde pas avec ses connaissances générales, mais uniquement avec des informations que vous lui fournissez (c’est la base du RAG).
template_contexte = """
Utilisez uniquement le contexte suivant pour répondre à la question.
Si vous ne connaissez pas la réponse d'après le contexte, dites "Je ne sais pas".
Contexte :
LangChain est un framework open-source lancé en 2022 par Harrison Chase.
Il permet de connecter des LLM à des sources de données externes.
En 2025, la fonctionnalité phare est LangGraph pour créer des agents cycliques.
Question : {question}
"""
prompt_rag = PromptTemplate.from_template(template_contexte)
# On réutilise le même modèle 'llm' défini plus haut
rag_chain = prompt_rag | llm
print(rag_chain.invoke({"question": "Qui a lancé LangChain ?"}).content)La notion de few-shot prompting avec Langchain
Les LLM sont performants, mais ils comprennent beaucoup mieux ce que vous attendez si vous leur donnez des exemples. C’est ce qu’on appelle le Few-Shot Learning.
Plutôt que d’expliquer longuement au modèle comment être « sarcastique », il suffit de lui montrer quelques paires de questions/réponses. LangChain propose des outils modernes pour gérer ces exemples proprement.
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
# 1. Définition de nos exemples
exemples = [
{"input": "Comment ça va ?", "output": "Je ne peux pas me plaindre, mais je le fais quand même."},
{"input": "Quelle heure est-il ?", "output": "L'heure de s'acheter une montre."},
]
# 2. Création du format pour les exemples
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
# 3. Injection des exemples dans le prompt final
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=exemples,
)
# 4. Assemblage du prompt final
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "Tu es un assistant sarcastique et plein d'esprit."),
few_shot_prompt, # On insère les exemples ici
("human", "{input}"),
]
)
# 5. Création et exécution de la chaîne
sarcastic_chain = final_prompt | llm
print(sarcastic_chain.invoke({"input": "Quel est le sens de la vie ?"}).content)
Grâce à FewShotChatMessagePromptTemplate, nous avons structuré les exemples comme une conversation passée. Le modèle « voit » l’historique et comprend immédiatement le ton à adopter pour la nouvelle question.
Concept #2 : construire un RAG avec Langchain
Si les « Prompt Templates » sont le moteur de votre application, le RAG (Génération Augmentée par la Récupération) en est le carburant.
Le problème des LLM comme GPT-5, c’est qu’ils sont limités :
- Ils ne connaissent pas vos données privées (vos PDF, vos emails, votre base Notion).
- Leurs connaissances s’arrêtent à leur date d’entraînement.
La solution ? Au lieu de demander au modèle de répondre de tête et risquer les hallucinations, nous allons d’abord lui donner accès à une « bibliothèque » contenant nos documents, lui demander de trouver les pages pertinentes, et ensuite de répondre.
C’est ce qu’on appelle la pipeline RAG, qui se déroule en 3 étapes clés : Indexation, Récupération (Retrieval) et Génération.
Voyons comment implémenter cela en quelques lignes de Python pour discuter avec un article de blog.
Pré-requis : Installation des packages
L’écosystème LangChain étant modulaire, nous avons besoin de quelques briques spécifiques, notamment pour la base de données vectorielle (ici Chroma) :
!pip install langchain langchain-openai langchain-chroma beautifulsoup4Étape 1 : Indexation avec Langchain (préparation des données)
Les modèles de langage ont une fenêtre de contexte (bien que GPT-5 soit très performant, il est plus efficace et moins coûteux de lui donner uniquement les passages pertinents). Nous allons donc :
- Charger une page web avec beautifulsoup
- La découper en petits morceaux (chunks)
- Transformer ces morceaux en vecteurs numériques (Embeddings) et les stocker
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
# 1. Chargement : On récupère le contenu d'un article Web
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_="post-content"))
)
docs = loader.load()
# 2. Découpage : On coupe le texte en morceaux de 1000 caractères
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 3. Stockage Vectoriel : On transforme le texte en vecteurs et on indexe dans Chroma
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# On crée un "retriever" : l'outil capable de faire la recherche
retriever = vectorstore.as_retriever()À ce stade, nous avons transformé un article brut en une base de connaissances interrogeable sémantiquement.
Étape 2 : La chaîne de génération (LCEL)
Maintenant, assemblons le tout. Nous allons créer une chaîne qui prend en entrée la question de l’utilisateur, elle va chercher les documents pertinents dans notre retriever et envoie le tout à GPT-5
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# Initialisation du modèle (Le dernier cri : GPT-5)
llm = ChatOpenAI(model_name="gpt-5")
# Définition du prompt système spécial RAG
template = """Vous êtes un assistant de recherche expert.
Utilisez le contexte suivant pour répondre à la question.
Si vous ne connaissez pas la réponse, dites simplement que vous ne savez pas.
Soyez concis.
Contexte : {context}
Question : {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# Petite fonction utilitaire pour joindre les documents trouvés en un seul texte
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# LA MAGIE DU LCEL (La chaîne RAG complète)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)Étape 3 : L’exécution
Il ne reste plus qu’à poser une question. Le système va chercher la réponse dans l’article chargé, et non dans sa mémoire générale.
# On pose une question sur le contenu spécifique de l'article
response = rag_chain.invoke("Qu'est-ce que la décomposition des tâches dans les agents autonomes ?")
print(response)En quelques lignes de code, on a créé un système capable d’ingérer n’importe quelle donnée (Juridique, Médicale, Technique) et d’utiliser la puissance de raisonnement de GPT-5 dessus, sans jamais avoir besoin de ré-entraîner le modèle.
C’est la brique fondamentale de 90% des applications d’IA en entreprise aujourd’hui.
Concept #3 : agents
Bien que très performants, les LLM ont des limitations majeures qui les rendent inutilisables pour certaines tâches critiques :
- Ils sont coupés du monde : Ils ne connaissent pas la météo de ce matin ni le cours de la bourse en temps réel.
- Ils sont nuls en maths : Demandez à un modèle littéraire de calculer
(4.5*2.1)^2.2, et il essayera de deviner la réponse plutôt que de la calculer.
C’est là qu’interviennent les Agents IA.
Qu’est-ce qu’un agent IA ?
Si le LLM est le « cerveau », l’Agent est le corps qui lui donne des « mains ». Concrètement, un agent est un système qui utilise un LLM pour raisonner : il analyse votre demande, décide de quels outils il a besoin, les utilise, observe le résultat, et recommence jusqu’à avoir la réponse.
En 2025, ça repose sur le Tool Calling (appel d’outils). Les modèles modernes comme GPT-5 sont entraînés pour détecter quand ils doivent s’arrêter de parler pour appeler une fonction Python (calculatrice, API, recherche Web).
On peut aussi accorder à l’agent l’accès à nos outils via des protocoles comme le MCP.
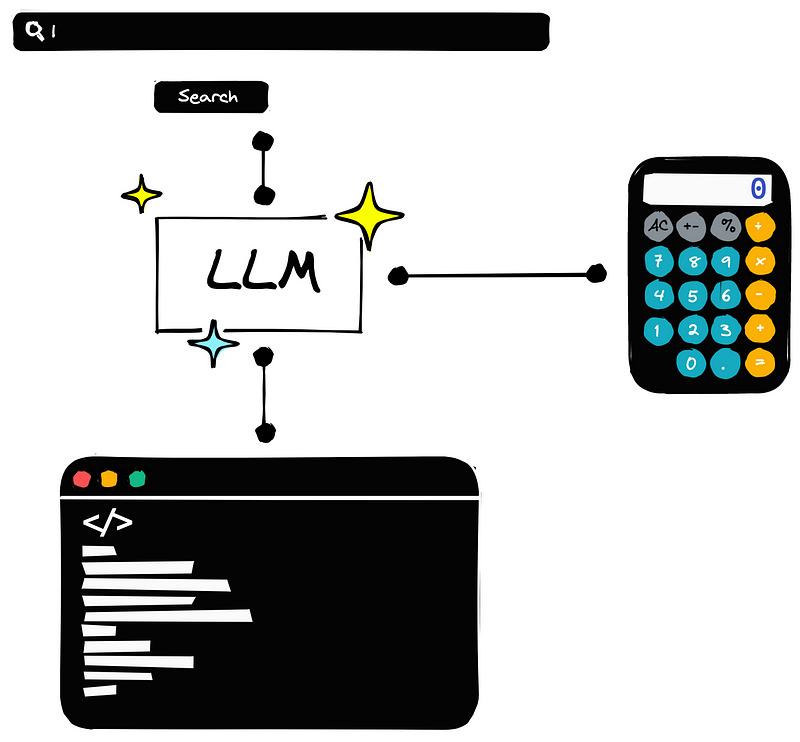
En utilisant des agents, un LLM peut écrire et exécuter du code Python, utiliser une calculatrice. Il peut également rechercher des informations et interroger une base de données SQL.
Imaginez toutes les applications qui peuvent en découler !
Comment construire un agent en pratique ?
Aujourd’hui, construire un agent IA se fait très simplement. Les outils sont simplement des décorateurs Python.
Créons un agent capable de faire des maths complexes et de connaître la longueur des mots (tâches où les LLM échouent souvent).
Etape 1 – Installation des dépendances
Le standard actuel pour orchestrer des agents est LangGraph, une extension de LangChain.
!pip install langchain langchain-openai langgraphEtape 2 – Création des outils (les super-pouvoirs de l’agent)
Nous allons créer deux outils simples. Remarquez le décorateur @tool : c’est lui qui explique au modèle comment utiliser la fonction.
from langchain_core.tools import tool
@tool
def multiplier(a: float, b: float) -> float:
"""Multiplie deux nombres. Utile pour les calculs précis."""
return a * b
@tool
def compter_lettres(mot: str) -> int:
"""Compte le nombre de lettres dans un mot."""
return len(mot)
tools = [multiplier, compter_lettres]Etape 3 – Initialisation de l’Agent (le cerveau)
Nous utilisons ici une architecture pré-construite de LangGraph appelée create_react_agent :
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
# On instancie le modèle (GPT-5 ou GPT-4o)
llm = ChatOpenAI(model="gpt-5", temperature=0)
# On crée l'agent : on lui donne le cerveau (LLM) et les mains (tools)
agent_executor = create_react_agent(llm, tools)Etape 4 : Testons l’agent en action
Commençons par une question qui nécessite un outil :
query = "Combien font 4589 fois 12.5 ? Et combien de lettres compte le mot 'Anticonstitutionnellement' ?"
# L'agent va exécuter une boucle de réflexion
response = agent_executor.invoke({"messages": [("human", query)]})
# Affichons la réponse finale
print(response["messages"][-1].content)
Ce qui se passe en coulisses :
- L’agent reçoit la question.
- Il « décide » (via le Tool Calling) d’appeler
multiplier(4589, 12.5). - Il reçoit le résultat mathématique exact.
- Il décide ensuite d’appeler
compter_lettres("Anticonstitutionnellement"). - Il formule une phrase finale en français avec les deux résultats exacts.
Quels sont les types d’agents dans Langchain ?
Aujourd’hui, le standard de l’industrie est le Tool Calling Agent, une méthode fiable où le modèle décide souverainement quel outil appeler et avec quels arguments.
Au-delà de ce standard, LangChain permet de piloter les Assistants OpenAI natifs (bénéficiant de leur Code Interpreter) ou de déployer des architectures de planification (Plan-and-Execute) qui séparent la réflexion stratégique de l’exécution tactique pour les tâches complexes.
Enfin, la grande tendance de 2025, propulsée par LangGraph, réside dans les systèmes Multi-Agents : plutôt que de tout demander à un seul agent généraliste, on orchestre désormais une « équipe » d’agents spécialisés (comme un chercheur, un rédacteur et un critique) qui collaborent et débattent entre eux pour atteindre un résultat optimal.
Conclusion
LangChain a parcouru un chemin immense. D’une simple bibliothèque de « bricolage » à ses débuts, elle est devenue le véritable système d’exploitation des applications génératives.
Elle fournit aujourd’hui l’abstraction nécessaire pour ne pas se soucier de quel modèle (OpenAI, Mistral ou Llama) tourne en arrière-plan, permettant aux développeurs de se concentrer sur la logique métier.
Mais construire un prototype n’est que la première étape. L’avenir du développement IA se joue désormais sur deux nouveaux fronts :
- Le LLMOps et l’observabilité (LangSmith) : Passer en production signifie devoir répondre à des questions difficiles : Pourquoi mon agent a-t-il donné cette réponse ? Combien me coûte cette chaîne ? C’est là qu’intervient le LLMOps. Avec des outils intégrés comme LangSmith, LangChain permet désormais de tracer, débugger et évaluer chaque étape de vos applications. L’enjeu n’est plus seulement de faire marcher le code, mais de le rendre fiable et observable.
- L’interopérabilité (le protocole MCP) : La prochaine révolution est celle de la connectivité. Jusqu’ici, connecter un agent à un outil demandait du code spécifique. L’arrivée du Model Context Protocol (MCP), standard ouvert supporté par LangChain, change la donne. Il promet un avenir où n’importe quel agent pourra se connecter instantanément à n’importe quel système de données ou logiciel métier via un protocole universel, sans avoir à réécrire d’adaptateurs.
En somme, nous quittons l’ère de la « découverte » pour entrer dans celle des systèmes agentiques robustes. LangChain vous donne les briques ; à vous maintenant d’assembler les architectures intelligentes de demain.
Matt Schlicht, CEO d’Octane AI, que nous vous recommandons de suivre et de lire, propose la petite analyse suivante des cas possibles ou LangChain devient hyper pertinent:




Merci pour ce guide détaillé sur LangChain ! Les explications sont claires et les exemples pratiques vraiment utiles. J’ai hâte d’explorer davantage cette technologie et de l’intégrer dans mes projets.