


En machine learning il est très fréquent d’avoir à construire un modèle sur des données présentant un déséquilibre des classes. Ce problème intervient lorsqu’une classe est beaucoup plus représentée que l’autre.
Par exemple en e-commerce, pour déterminer si une transaction est frauduleuse, on doit gérer le déséquilibre des classes. La très grande majorité des transactions ne sont pas des fraudes. Si ce facteur n’est pas pris en compte, on risque de construire un modèle qui sera incapable de détecter les fraudes.
C’est aussi un des problèmes que nous avions rencontrés pour la classification des accidents par gravité. On s’était aperçu que la classe des accidents qui ont conduit à un décès était sous-représentée (heureusement!).
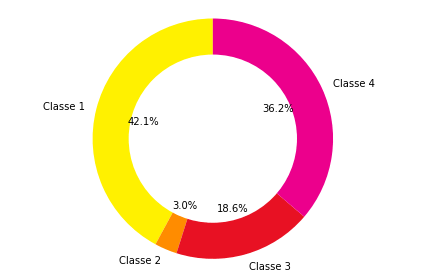
En conclusion de cet article j’expliquais qu’une option possible pour résoudre ce problème était de regrouper les classes 2 (tué) et 3 (hospitalisé). On devait ensuite les séparer avec un modèle de clustering et en enlevant les classes 1 et 4 cette fois. C’est une solution sur-mesure reposant sur la similarité entre les classes 2 et 3 et qui n’est pas généralisable.
Les méthodes de machine learning classiques ne sont pas toujours adaptées pour la classification sur des données déséquilibrées. Elles donnent souvent de mauvais résultats et, pire encore, elles peuvent induire en erreur avec des scores trop optimistes. Une des causes de ces échecs est que les points de la classe minoritaire sont considérés comme des outliers qui ne contiennent aucune information.
Heureusement de nombreuses techniques existent, laissez moi vous en présenter quelques-unes.

Les différentes méthodes pour pallier le déséquilibre des classes
On sépare les approches pour contourner le déséquilibre des classes en 2. Les méthodes data-level qui consistent en des transformations opérées sur les données d’entraînement, et les méthodes algorithm-level qui reposent sur des modifications des modèles utilisés pour qu’ils soient plus adaptés à ce problème.
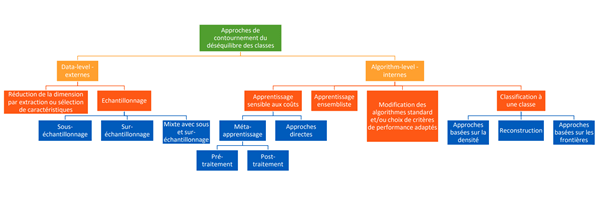
Méthodes data-level
L’idée derrière les approches data level est toujours la même. Il s’agit de transformer les données d’entraînement du modèle pour atténuer le déséquilibre. On va souvent utiliser des techniques d’échantillonnage pour ajouter des représentants dans la classe minoritaire et/ou en retirer de la classe majoritaire.
Sous-échantillonnage aléatoire
La première approche consiste en un sous-échantillonnage de la classe majoritaire. On cherche à réduire la taille de la classe majoritaire pour atténuer le déséquilibre des classes. On va choisir les points à retirer de manière très naïve, simplement en retirant des points de façon aléatoire.
Inutile de préciser que nous pouvons mieux faire.
Tomek links
Une autre approche de sous-échantillonnage de la classe majoritaire, un peu plus fine cette fois, propose un moyen plus naturel pour choisir les points à éliminer. L’idée est de chercher ceux de la classe majoritaire qui sont assez proches d’un point de la classe minoritaire. Les paires de points identifiées sont appelées tomek links. Dans chaque tomek link on va retirer le point qui appartient à la classe majoritaire.
On peut remarquer au passage que l’identification des tomek links se fait comme l’identification des plus proches voisins dans l’algorithme k-nn.
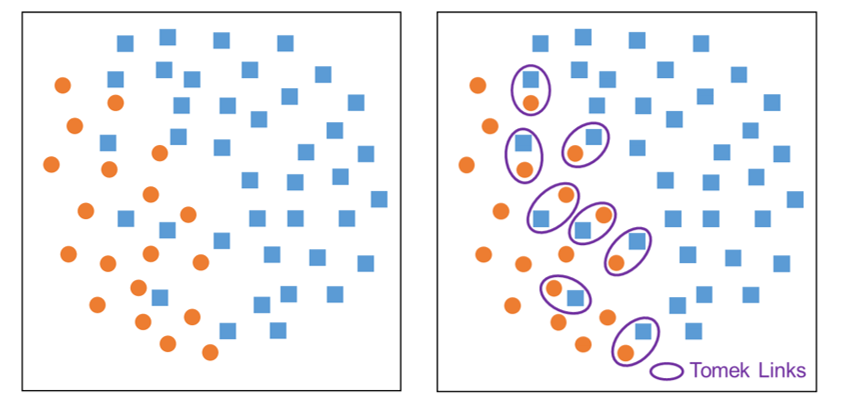
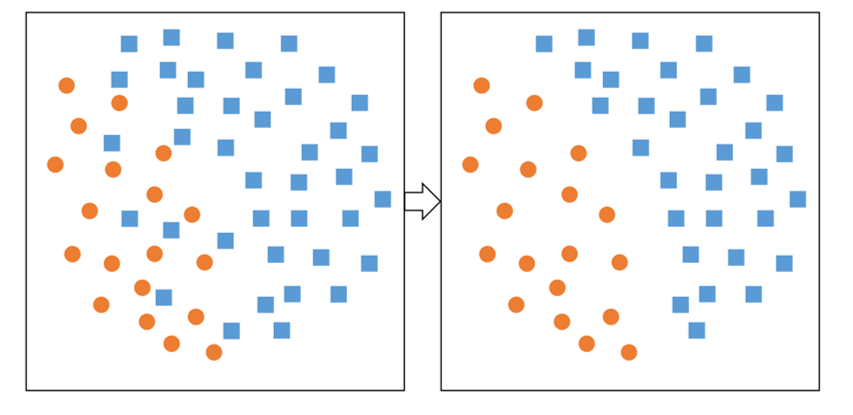
Cette approche sera en pratique plus efficace que le sous-échantillonnage aléatoire. Elle va réduire la variance de la classe majoritaire et supprimer d’éventuels outliers, qui peuvent être une grande source de confusion.
SMOTE
L’autre approche d’échantillonnage que l’on retrouve souvent est SMOTE (Synthetic Minority Oversampling Technic). C’est une technique de sur-échantillonnage cette fois. Plutôt que de réduire la taille de la classe majoritaire, on cherche à agrandir celle de la classe minoritaire.
Pour cela, on va sélectionner des points de la classe que l’on souhaite agrandir et en créer de nouveaux. C’est une méthode très semblable à la data augmentation que l’on utilise pour réduire les risques d’overfitting.

Si vous souhaitez vous amuser avec SMOTE, sachez que les variantes de cette méthode sont nombreuses et que vous pourrez les explorer dans la librairie smote-variants.
Comme pour l’under-sampling, on trouve aussi une approche de random over-sampling, même si je ne suis pas très convaincu des performances qu’une telle méthode permettrait d’avoir.
Méthodes algorithm-level
La deuxième grande famille d’approches regroupe les méthodes dites algorithm-level. Elles reposent sur des adaptations des modèles de machine learning classiques afin qu’ils soient en mesure de mieux gérer le déséquilibre.
Apprentissage sensible aux coûts
Une des méthodes algorithm-level possible, est celle qui consiste à affecter un poids plus important à la classe minoritaire. On parle d’apprentissage sensible aux coûts. En pratique on va spécifier à notre modèle que le fait de bien classer un point de la classe minoritaire est plus important que de bien classer un point de la classe majoritaire. De cette façon on s’arrange pour qu’une erreur de classification d’un point de la classe minoritaire soit considérée par le modèle comme étant plus grave qu’une erreur de classification sur la classe majoritaire.
Dans l’illustration ci-dessous on cherche à déterminer si un matériel est défaillant ou non. Précisons que c’est la classe des matériaux défaillants qui est minoritaire. On va faire comprendre au modèle que prédire qu’un matériel est défaillant alors qu’il est sain, est beaucoup moins grave que de faire l’erreur inverse. Parallèlement, une bonne prédiction sur la classe des matériaux défaillants vaut plus qu’une bonne prédiction sur la classe des matériaux sains.

Comme l’objectif des modèles de machine learning est toujours d’optimiser un paramètre prédéfini, on observe que l’optimisation du gain va inciter l’algorithme à donner plus d’importance à la classe minoritaire et donc à améliorer les prédictions sur celle-ci.
D’ailleurs, dans l’implémentation Scikit-learn de random forest vous pouvez jouer avec la classe sample_weights. Et d’après cette discussion sur Stack, il semblerait que ce paramètre repose sur la technique d’apprentissage sensible aux coûts. Random forest, lors du calcul des probabilités d’appartenance d’un point à une classe, redistribue ces probabilités en tenant compte des ratios spécifiés.
Apprentissage à une classe
Une autre approche qui pourrait donner de bons résultats dans certains cas est l’apprentissage à une classe. Plutôt que d’entraîner un classifieur sur nos 2 classes, on entraîne un détecteur sur la classe majoritaire. Il sera ensuite capable de prédire si un point fait partie de la classe ou non.
Même si les modèles d’apprentissage à une classe ne sont pas spécialement conçus pour contrer le déséquilibre des classes, ils peuvent offrir de gros gains de performances.
Bien choisir les métriques pour mesurer les performances des modèles
Généralement en machine learning, il faut s’attarder sur le choix des métriques de mesure des performances. Cette règle est encore plus fondamentale lorsque l’on travaille sur des données déséquilibrées. Même si ça ne nous permet pas de contrer le problème, bien choisir les métriques nous permettra d’éviter des déconvenues.
Par exemple, en classification binaire il est d’usage d’utiliser le pourcentage de bonnes prédictions comme score. Sauf que ce pourcentage peut être élevé même si une grande partie des points de la classe minoritaire sont mal classifiés. Le score va lui aussi être affecté par le déséquilibre des classes. On pourrait croire que notre modèle est bon même lorsqu’il n’est bon que pour la classe majoritaire.
Pour pallier ce problème, nous allons nous tourner vers des métriques qui ne seront pas affectées par la mauvaise répartition. On peut par exemple tracer la matrice de confusion du modèle :
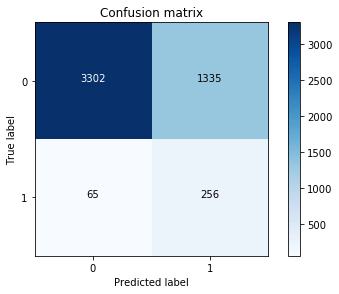
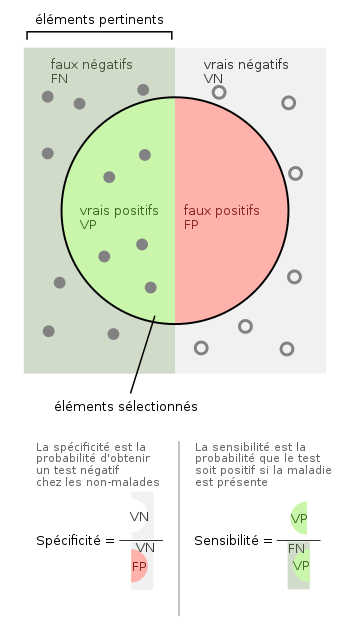
On pourra aussi utiliser des métriques qui seront beaucoup moins influencées par la classe majoritaire. Le recall (sensibilité) ou le F-Score sont de bons exemples.
Pour conclure, rappelons que pour résoudre un problème de machine learning il faut des datasets de qualité. Et c’est en fait la plus grosse limitation que l’on rencontre. Une mauvaise répartition des classes dans votre dataset peut affecter sérieusement les performances de vos modèles. C’est d’ailleurs la première chose que l’on vérifie lorsque l’on veut évaluer la qualité de nos données. Alors, si ce n’est pas déjà fait, ajoutez la vérification de la répartition des classes à votre checklist de prétraitement !
Les méthodes que nous avons vues sont celles qui sont les plus utilisées. Néanmoins, il est nécessaire d’avoir une bonne compréhension de son dataset en l’étudiant à la lumière de la problématique qui est en jeu. Il n’y a pas vraiment d’approche qui satisfera tout le monde, c’est là que réside le défi du data scientist.



Laisser un commentaire