
Beaucoup de choses sont dites au sujet du machine learning. Certains le voit comme un monstre qui mène l’humanité à sa perte. D’autres comme un magicien solution à tous leurs maux. En réalité c’est beaucoup plus simple que ça (et un peu moins effrayant).

Qu’est-ce que le machine learning ?
Le machine learning est une technique qui permet aux systèmes automatiques de s’améliorer grâce aux données. Littéralement on parle d’apprentissage automatique.
L’explosion du volume de données et le progrès des techniques de traitement et de stockage, on permit au machine learning de s’imposer dans de nombreux domaines.
Comment fonctionne le machine learning ?
Derrière ce nom mystérieux, se cache un fonctionnement en principe très simple. Le système s’inspire d’exemples déjà existants, regroupés dans des bases de données, pour comprendre la tâche qui lui est demandée.
Que les choses soient claires. Ce n’est pas parce que l’on parle de machines qu’il faut imaginer des robots qui suivent des cours dans une salle de classe. Le vocabulaire utilisé n’est qu’une manière imagée de décrire le processus.
Quel est le lien entre machine learning, deep learning et intelligence artificielle ?
Comme tous les domaines polémiques, l’intelligence artificielle fait couler beaucoup d’encre. La conséquence directe de cela est l’apparition de buzzwords et on finit un peu par se perdre.
En réalité, le deep learning n’est qu’un sous ensemble du machine learning, lui même sous ensemble de l’intelligence artificielle. Dans un diagramme voici ce que ça donne.
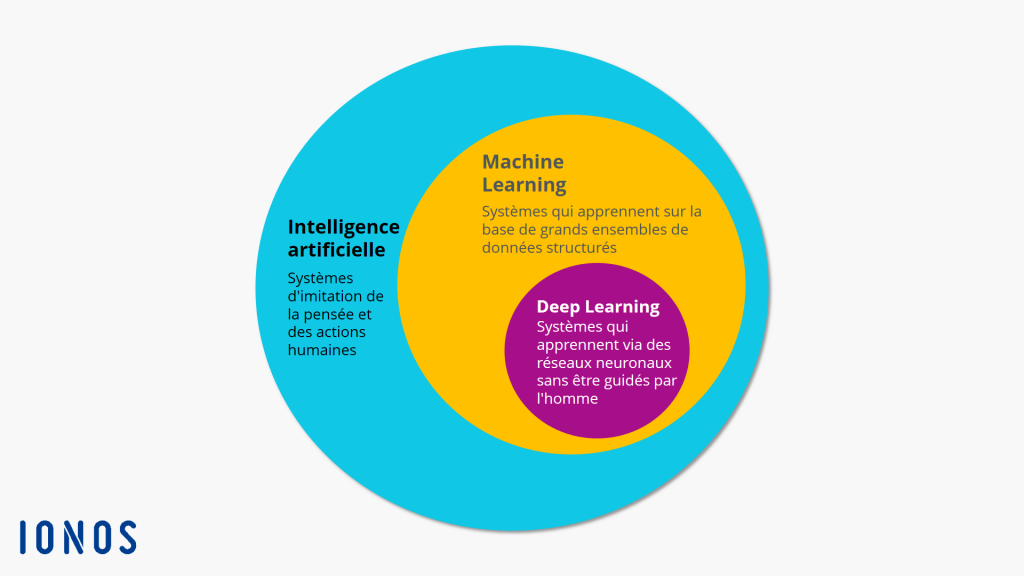
Quelles sont les applications du machine learning ?
Le machine learning s’est imposé dans un très grand nombre de domaines. Il n’y a pas réellement de limites à ce que les modèles de machine learning peuvent réaliser. Dès qu’il y a des données on peut faire du machine learning.
En finance par exemple, la volatilité des marchés boursiers semble ne pas laisser de place à la prédiction. Néanmoins, le machine learning fournit une solution. Il permet de donner des prévisions plus ou moins précises concernant l’évolution d’une action boursière.
Dans le domaine de la santé aussi, l’intelligence artificielle commence à s’imposer comme un outil majeur. L’IA est régulièrement utilisée par les médecins aujourd’hui. La médecine du futur est souvent associée aux 3 P : Prévention, Prédiction, Personnalisation
C’est surtout pour l’imagerie médicale que les IA d’aujourd’hui se démarquent vraiment. Les progrès en terme de computer vision ont été impressionnants ces dernières années. Et les IA d’aujourd’hui sont au moins aussi fortes que les médecins sur des tâches comme la détection de tumeurs cancéreuses ou le calcul de l’âge osseux.
De manière plus générale, l’IA constitue une opportunité de développement sans précédent pour les entreprises. Elle permet d’établir des stratégies à plus ou moins long terme à travers des outils d’aide à la prise de décision.
Le machine learning permet de répondre à des questions comme : Dois-je me lancer dans ce projet de construction immobilière ? Est-ce que le profil de ce candidat correspond à ce poste ? Comment va évoluer le marché de la voiture électrique d’ici 2025 ? Et des millions d’autres questions propres à chaque activité.
Quelle est la différence entre apprentissage supervisé et apprentissage non supervisé ?
Le machine learning se divise essentiellement en deux modes d’apprentissage. L’apprentissage supervisé et l’apprentissage non supervisé.
En apprentissage supervisé, les données dont on dispose sont labellisées. C’est à dire, les sorties du modèle sont déjà connues. C’est le cas pour les réseaux de neurones par exemple.
A l’inverse, lorsque l’on fait de l’apprentissage non supervisé, on laisse le modèle s’entraîner tout seul, sans labelliser les données. Un des algorithmes de clustering non supervisé les plus utilisés est k-means. On donne à l’algorithme tous les points de notre dataset et on a en sortie ces mêmes points regroupés en plusieurs catégories.
Qu’est-ce que l’explicabilité en machine learning ?
Beaucoup de modèles que l’on utilise aujourd’hui sont ce qu’on appelle des boîtes noires. Dans le sens où ils sont opaques et leur fonctionnement interne est très peu compris.
Le dilemme efficacité/explicabilité est un dilemme bien connu en science des données. Bien souvent les modèles les plus efficaces sont des boîtes noires dont le fonctionnement est le moins explicable.
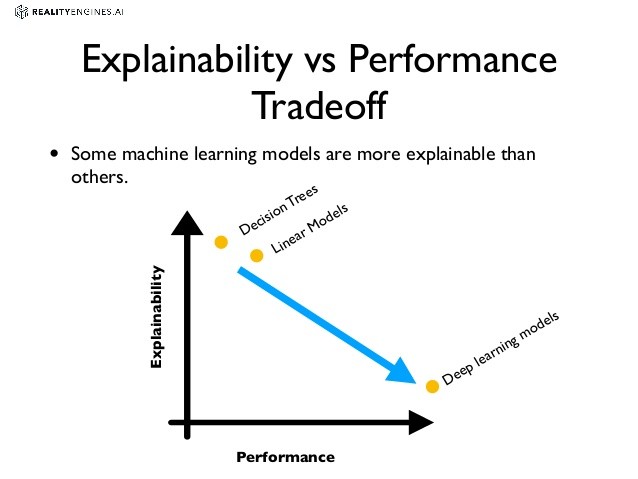
Quelles sont les étapes d’un projet en data science ?
Lorsque j’ai commencé à travailler sur des projets de data science, j’ai été surpris de voir que la construction du modèle ne représentait qu’une petite étape d’un long processus.
Les projets se divisent souvent de la sorte :
- Collecte et stockage des données
- Preprocessing (nettoyage des données et études préalables)
- Construction des modèles
- Etudes de performances et choix du meilleur modèle
- Déploiement du modèle
Comment se déroule le nettoyage des données (preprocessing) ?
Contrairement à ce que l’on pense, le nettoyage des données est la tâche principale lors d’un projet de machine learning. Et c’est dommage (d’après moi en tout cas 🙂 ), car c’est beaucoup moins amusant que la conception du modèle ! Tous ce travail que l’on fait en amont est ce que l’on appelle le preprocessing.
Les techniques de preprocessing dépendent du projet et du types de données que l’on étudie. Bien souvent on suit les étapes suivantes :
- Traitement des valeurs manquantes
- Calcul de corrélations ou de variances
- Réduction de la dimension
- Encodage des features
- Découpage des données en train/test
Comment évaluer un modèle ?
Avant de mettre un modèle en production, il y a toute une phase de validation qui débute. Et pour ne rien faciliter cette phase de validation implique d’être minutieux.
D’abord, avant d’entraîner un modèle on s’assure de séparer les données disponibles en 2. Données d’entraînements et données de tests. On parle de cross validation.
Cela permet de tester le modèle une fois entraîné, cette étape est primordiale. Elle permet de s’assurer de la fiabilité du modèle mais aussi de comparer plusieurs approches pour pouvoir déterminer la quelle est la plus intéressante.
Comment éviter l’overfitting ?
L’overfitting est le plus grand ennemi du data scientist. Il survient lorsque le modèle essaye de trop coller aux données. Si bien qu’il n’est plus généralisable.
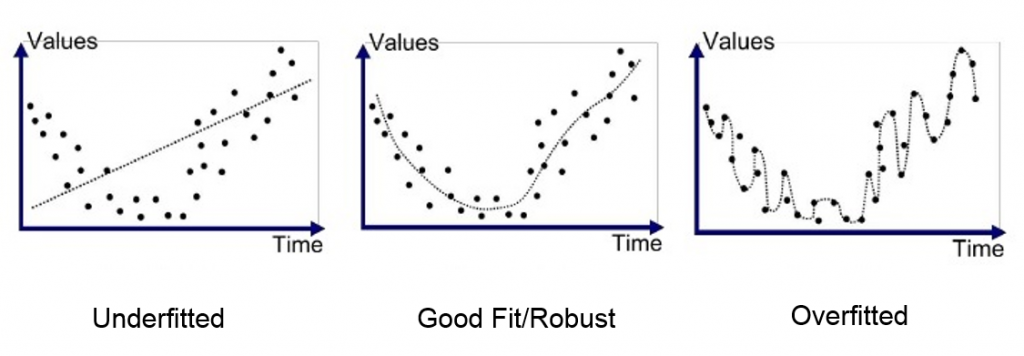
Avant de savoir comment l’éviter, nous devons apprendre à le détecter.
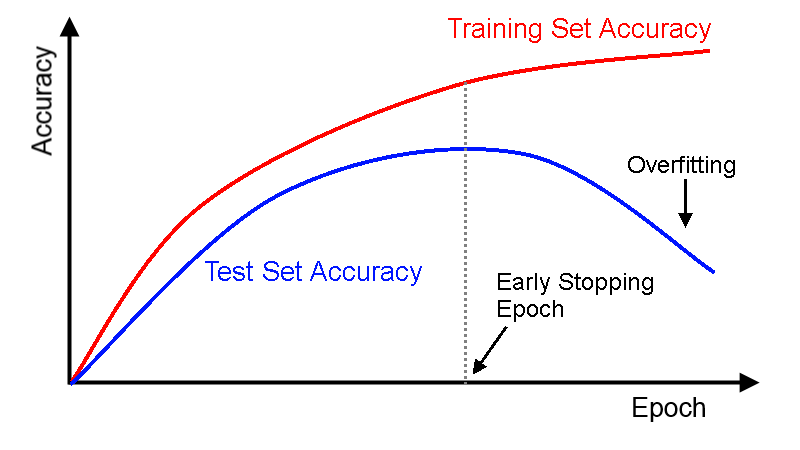
Sur cette courbe (que vous devrez toujours tracer pour vérifier les performances du modèle) on voit qu’à partir d’un certain point, notre précision sur les données de test chutent. Cela veut dire que le modèle commence à être de moins en moins efficace. On fait de l’overfitting.
Plusieurs méthodes existent pour éviter l’overfitting :
- Cross validation
- Ajouter plus de données pour l’entraînement
- Early stopping (arrêter l’entrainement avant qu’ils ne se terminent)
- Régularisation (par exemple le dropout pour les réseaux de neurones)
On a un article entier sur ce sujet 🙂
Quels sont les principaux outils utilisés en machine learning ?
Les outils qui interviennent en machine learning sont nombreux. Pour le développement de modèle on utilise des langages de programmation objets performants comme Python ou C.
Python reste le langage de référence. Il jouit d’une communauté open source très active ce qui permet d’avoir des modules très puissants comme Pandas, Tensorflow ou Scikit-learn. Ils rendent les modèles de machine learning plus facile à implémenter. Ça serait beaucoup trop longs de vous énumérer tous les outils utilisés en machine learning. Si je devais en garder que 3 (pour la partie construction de modèles), je prendrais ceux là.
Quelles sont les principales méthodes utilisées ?
Les modèles de machine learning sont nombreux. Ceux qui ont la côte aujourd’hui sont les algorithmes de deep learning, ils sont fiables faciles à entraîner et donnent d’assez bons résultats la plupart du temps.
Il y a un grand nombre de méthodes en fonction de ce que l’on veut faire.
Pour le clustering :
- k-nn
- k-means
- DBScan
- Régression logistique
- SVM
Réseaux de neurones :
- LSTM
- CNN
- GAN
- Auto Encoder
- Perceptron
Arbres de décisions :
- Random Forest
- XGBoost
- AdaBoost
- LightGBM
- CatBoost
Avec tous ces algorithmes on est en droit de se demander lequel choisir. La transition avec la prochaine question est parfaite 🙂
Comment choisir l’algorithme à utiliser ?
Le machine learning est une question de choix. Des données jusqu’à l’algorithme à utiliser, le data scientist a de nombreuses décisions à prendre. Le choix de l’algorithme à utiliser est sans doute le plus crucial.
Plusieurs critères sont à prendre en compte pour choisir un modèle :
- Quelle tâche souhaitez vous effectuer ? Prédiction ? Régression ? Clustering ?
- Les données sont elles labellisées ?
- De quel types sont les données ? Images ? Textes ? Audio ?
- Quelle est la taille de votre dataset ?
Quelles sont les limites du machine learning ?
L’intelligence artificielle est souvent vu comme une baguette magique capable de tout. En réalité ce n’est pas si simple. Les modèles ont souvent besoin d’énormément de données pour pouvoir donner de bons résultats.
Dans mon article Ce que l’IA n’est pas, j’explique comment le marketing a rendu l’intelligence artificielle plus impressionnante qu’elle ne l’est réellement. Les modèles d’aujourd’hui sont très limités, ils demandent beaucoup d’entraînement et sont assez peu généralisables.
Quelles compétences doit avoir un data scientist ?
Les data scientist sont aujourd’hui très recherchés. Un ingénieur en machine learning doit avoir des compétences aussi bien théoriques que pratiques. Il doit être un très bon statisticien, c’est indispensable pour comprendre correctement les différents algorithmes et leurs subtilités. D’un point de vu plus pratique, il doit être à l’aise avec les outils de programmation comme Python.

Merci pour cette minute de lecture. C’est excellent !
Heureux que l’article vous ai plu !
j’ai beaucoup appris en un laps de temps merci!!!!
Avec plaisir 🙂
Parfait, merci !
Merci pour votre retour 🙂