
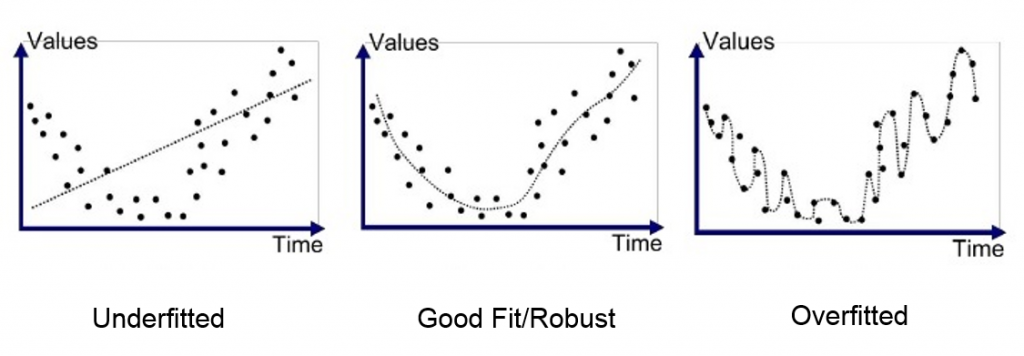
L’overfitting est un problème qui est souvent rencontrés en machine learning. Il survient lorsque notre modèle essaye de trop coller aux données d’entraînements. Dans cet article je vous explique comment éviter l’overfitting.

L’overfitting constitue la hantise des data scientist. Avant d’expliquer quelles sont les méthodes qui permettent de pallier ce problème, voyons comment le détecter.
Comment savoir si un modèle fait de l’overfitting ?
En data science les données parfaites n’existent pas. Vous avez toujours du bruit et des imprécisions. Un modèle fait de l’overfitting lorsqu’il commence à apprendre ce bruit. Il en résulte un modèle biaisé qui est impossible à généraliser.
En pratique, un modèle qui overfit est souvent très facile à détecter. L’overfitting intervient lorsque l’erreur sur les données de test devient croissante. Typiquement, si l’erreur sur les données d’entraînements est beaucoup plus faible que celle sur les données de test, c’est sans doute que votre modèle a trop appris les données.
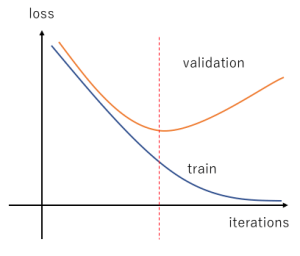
Comment éviter l’overfitting ?
Heureusement plusieurs techniques existent pour éviter l’overfitting. Dans cette partie je vous présente les méthodes les plus utilisées.
Cross-validation
Une des méthodes les plus efficaces pour éviter l’overfitting est la cross validation (validation croisée en français).
Contrairement à la validation classique, ou l’on divise les données en deux, en cross validation on divise les données d’entraînements en plusieurs groupes. L’idée est ensuite d’entraîner le modèle sur tous les groupes sauf un. Si on a k groupes, on entraînera le modèle k fois avec à chaque fois un nouveau groupe de test. Cette technique de validation croisée est appelée k-fold.

Bon j’avoue je vous vends du rêve avec la validation croisée 🙂
k-fold est surtout utilisée pour évaluer les performances d’un modèles. Cette technique permet de sélectionner les bons modèles de machine learning. Lorsqu’il s’agit d’éviter l’overfitting, cette méthode interviendra surtout pour le détecter plus efficacement. Notamment lorsque les métriques de bases ne suffisent pas.
Ajouter des données d’entraînements
Evidemment la solution idéale serait d’augmenter la taille des données d’entraînements. Plus le modèle verra d’exemples, plus il sera généralisable. A l’inverse si le modèle est entraîné avec une faible quantité de données, il aura de grandes chances d’être biaisé.
Malheureusement, la plupart du temps toutes nos données disponibles sont déjà mobilisées. Pour contrer cela des techniques d’augmentation de données existent.
Par exemple en computer vision, lorsque nos données sont des images, on peut créer des filtres pour modifier légèrement les couleurs. On peut pivoter les images ou étirer certains traits. Cela permet de réduire les risques d’overfitting. En plus, cette technique peut être mise en place très facilement, la plupart des outils et des librairies de machine learning proposent l’option nativement.

Retirer des features
Une des techniques pour améliorer les performances d’un modèle de machine learning est de sélectionner correctement les features (les variables que l’on considère pour l’entraînement du modèle).
L’idée est de retirer toutes les features qui n’apportent rien. Si deux variables sont corrélées par exemple, mieux vaut en retirer une. Si une variable a une variance trop faible, elle n’impacte pas le phénomène étudié mais peut fausser les résultats.
De cette façon on simplifie au maximum nos données, on améliore les performances du modèle et on réduit au passage les risques d’overfitting.
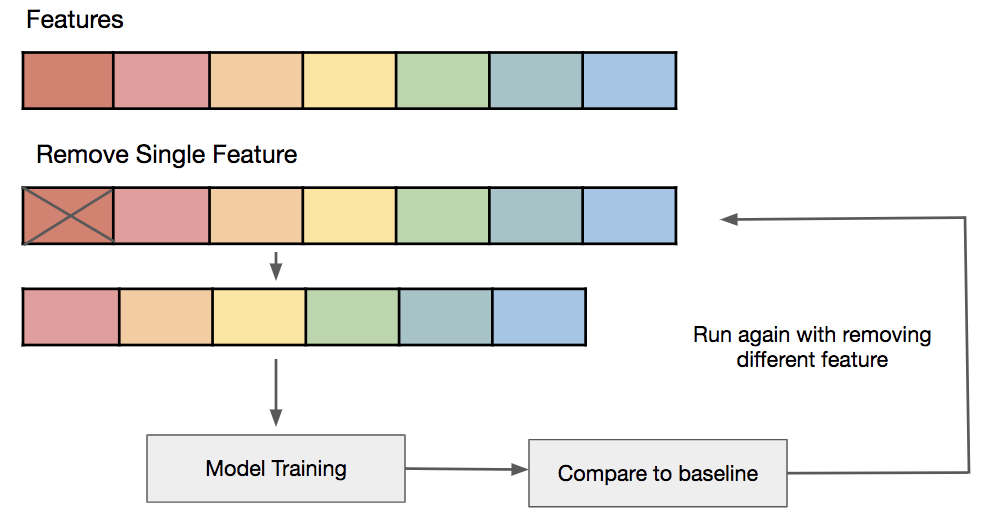
Une des façons de faire ça est d’entraîner le modèle plusieurs fois. A chaque fois on retire une des features et on étudie l’impact sur l’entraînement du modèle. Cette technique ne peut être utilisée que sur des données avec un nombre de features plutôt faible.
Méthodes de régularisations
Les méthodes de régularisations sont des techniques qui permettent de réduire la complexité globale d’un modèle de machine learning. Elles permettent de réduire la variance et ainsi réduisent les risques d’overfitting.
Voyez cette exemple pour une régression logistique. On voit qu’avant régularisation le modèle faisait de l’overfitting. La régularisation résout le problème dans ce cas.
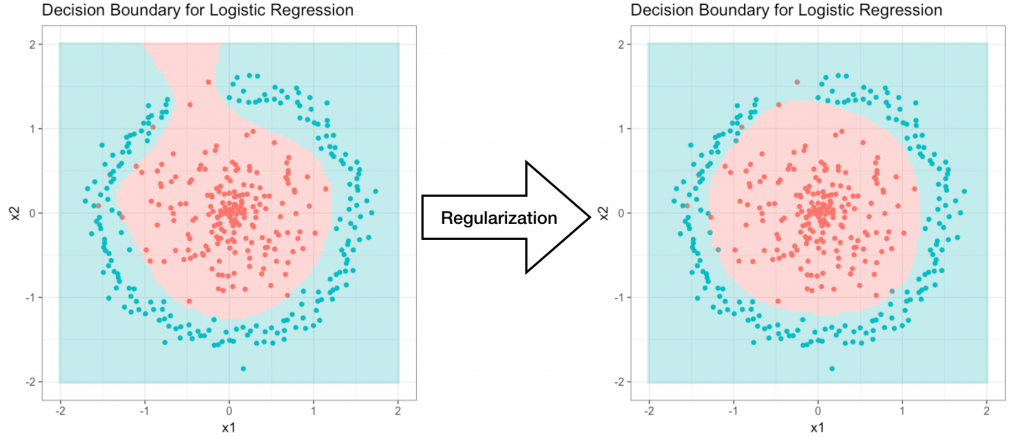
Les méthodes de régularisations permettent de réduire considérablement la variance du modèle sans que le biais n’augmente beaucoup. Nous reparlerons du dilemme biais/variance dans la dernière partie.
De nombreuses techniques de régularisations existent :
- Régularisation L1
- Ridge
- Régularisation L2
- Lasso
Cet article sur Medium en parle de façon très détaillée.
Commencer par concevoir des modèles simples
Plus votre modèle est simple, plus vous éviterez l’overfitting. La majorité des applications peuvent être résolues de façon satisfaisante avec des modèles simples.
C’est d’ailleurs un conseil que je vous donne, commencez toujours par construire des modèles simples. Il est inutile d’entraîner un réseau de neurones à plusieurs couches, lorsqu’un modèle statistique simple donne de bons résultats.
L’early stopping
L’early stopping est une technique très intuitive. Elle consiste simplement à arrêter l’entraînement avant que le modèle ne commence à overfitter.
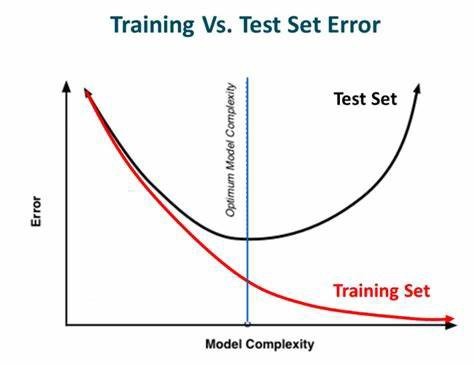
Cela exige de trouver la durée d’entraînement optimale et permet d’avoir le meilleur compromis : un modèle assez performant qui n’overfit pas.
L’early stopping permet aussi de détecter lorsque le modèle utilisé n’est pas adaptée, si on voit que le modèle commence à overfitter alors que les performances sont trop faibles, c’est qu’on doit changer de méthode.
L’early stopping est souvent associé au fameux dilemme biais/variance en statistiques. En machine learning on parle de dilemme underfitting/overfitting.
Cette technique est surtout utilisée en deep learning pour l’entraînement de réseaux de neurones. Pour d’autres modèles de machine learning comme Random Forest ou les SVM, les techniques de régularisations sont souvent plus adaptées.
Pour conclure, éviter l’overfitting est un art qu’un bon data scientist doit maîtriser. Ces différentes techniques fonctionnent plutôt bien. Néanmoins, avoir une bonne compréhension du fonctionnement théorique des modèles utilisés reste le moyen le plus sur, même s’il nécessite de plonger assez profondément dans la théorie du machine learning…


Leave a Comment