
Dans cet article on compare les algorithmes Random Forest et XGBoost, en travaillant sur un projet de prédictions.
L’objectif est de créer un modèle qui permet de prédire la gravité d’un accident, en fonction de plusieurs informations sur cet accident.

Avant de commencer, je précise que tous les codes ainsi que les ressources utilisées dans ce tutoriel sont disponibles sur mon GitHub.
Description des données
Ces données ont été tirées du site data.gouv.fr. C’est le site de référence de l’open data en France.
Pour ce projet nous avons 4 fichiers différents. Vous pouvez les télécharger ici :
- carac.csv nous donne des caractéristiques sur les accidents
- lieux.csv recense des données sur les lieux des accidents
- veh.csv donne des informations sur les véhicules impliqués
- vict.csv donne des informations sur les victimes
L’objectif de ce tutoriel est de voir ensemble quelles sont les différentes étapes de résolution d’un projet de ce genre. Nous ne chercherons pas à optimiser les scores obtenus.
Concrètement, pour chaque victime, la gravité de l’accident est donnée sur une échelle de 1 à 4 :
- 1 : Indemne
- 2 : Tué
- 3 : Hospitalisé
- 4 : Blessé léger
On doit donc résoudre un problème de clustering supervisé puisque les données sont labellisées.
Preprocessing
Comme à chaque fois, commençons par importer tous les outils dont nous auront besoin :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import normalize
from sklearn.cluster import KMeans
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.metrics import recall_score, f1_score
Vous connaissez déjà Pandas, Numpy et Matplotlib.
On aura aussi besoin de pas mal de fonctions de scikit-learn:
- Kmeans pour faire du clustering (vous comprendrez pourquoi 🙂 )
- random forest et XGBoost
- train_test_split permettra de séparer la base en train/test
- GridSearchCV sera utilisé pour l’optimisation des hyper-paramètres
- Plusieurs métriques pour la validation
La première étape est de construire une base d’apprentissage exploitable. Elle devra regrouper les données de tous les fichiers et ne sera composée que de variables numériques (il y aura donc un gros travail d’encodage).
On doit maintenant importer les données :
carac = pd.read_csv("carac.csv",sep=';')
lieux = pd.read_csv("lieux.csv",sep=';')
veh = pd.read_csv("veh.csv",sep=';')
vict = pd.read_csv("vict.csv",sep=';')On regroupe tous nos dataframes dans un même tableau :
victime = vict.merge(veh,on=['Num_Acc','num_veh'])
accident = carac.merge(lieux,on = 'Num_Acc')
victime = victime.merge(accident,on='Num_Acc')Traitement des valeurs manquantes
Nos données contiennent un très grand nombre de valeurs manquantes. La première idée était de supprimer les lignes pour lesquelles des informations sont manquantes. Le problème c’est qu’en faisant ça on se retrouve avec trop de lignes en moins, environ 30%.
Il est donc beaucoup plus judicieux de retirer les caractéristiques qui avaient trop de nan, pour ne pas predre beaucoup de données.
Regardons quelles sont les variables à supprimer. Pour cela rien de mieux qu’un joli diagramme en barres.
Le code ci-dessus n’est pas très important, c’est seulement pour avoir un plus joli rendu.
nan_values = victime.isna().sum()
nan_values = nan_values.sort_values(ascending=True)*100/127951
ax = nan_values.plot(kind='barh',
figsize=(8, 10),
color='#AF7AC5',
zorder=2,
width=0.85)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.tick_params(axis="both",
which="both",
bottom="off",
top="off",
labelbottom="on",
left="off",
right="off",
labelleft="on")
vals = ax.get_xticks()
for tick in vals:
ax.axvline(x=tick, linestyle='dashed', alpha=0.4, color='#eeeeee', zorder=1)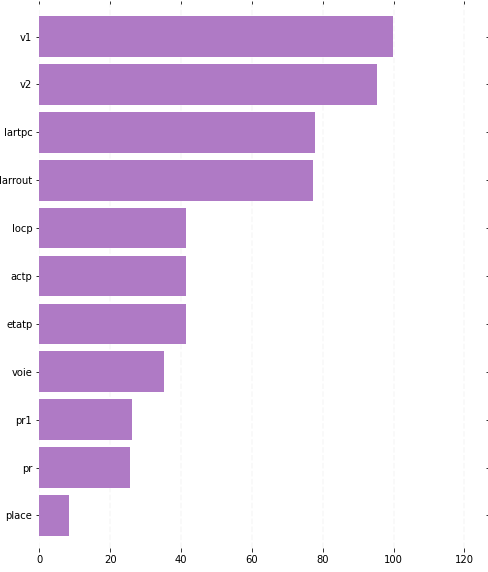
On voit que pour certaines variables, le pourcentage de valeurs manquantes dépasse les 40%. Je fixe une limite à 10% de valeurs manquantes par variable, on doit donc en retirer 11.
On utilise pour cela la fonction drop :
nans = ['v1','v2','lartpc',
'larrout','locp','etatp',
'actp','voie','pr1',
'pr','place']
victime = victime.drop(columns = nans)Après cela on doit supprimer les lignes qui comportent encore des valeurs manquantes, il ne devrait pas en rester beaucoup :
victime = victime.dropna()Features selection et encodage des variables
Nous avons maintenant constitué un dataframe qui regroupe toutes les données des 4 fichiers. Le nettoyage des valeurs manquantes ne suffit pas. Nous devons maintenant encoder nos données pour qu’elles puissent être traitées par nos modèles.
Calcul des corrélations et des variances
Pour optimiser l’entrainement de notre modèle, nous devons choisir judicieusement les features à considérer. Pour cela, la première chose à faire est de calculer les matrices de corrélations et de variances.
L’idée est que si des variables sont corrélées, on peut en garder seulement une. Cela simplifie les données mais peut aussi rendre notre modèle plus robuste puisque ça permet de réduire l’impact de certaines variables.
Concernant la variance, elle est un indicateur de la dispersion des valeurs d’une certaine variable. Si elle est faible pour une variable donnée, cela voudra dire que l’impact de cette variable est négligeable. La supprimer nous permet de gagner en efficacité.
Les calculs de variances et de corrélations se font très facilement :
victime.corr()
victime.var()Le calcul de la matrice de corrélation ne donne rien. Les valeurs des corrélations étaient très loin de 1 ou -1.
En revanche, le calcul de la variance m’a permis de voir que la variable an ne variait quasiment pas. Comme elle n’apporte aucune information nous pouvons la retirer.
victime = victime.drop(columns=['an'])Maintenant que le nettoyage des données est terminé, on doit transformer toutes les variables en variables numériques.
La majorité des variables que l’on a sont des variables catégoriques. Néanmoins, l’heure de l’accident, le mois et les coordonnées GPS ne sont pas des variables numériques contrairement à ce que l’on pourrait penser. C’est pour cela que nous allons traiter ces deux variables séparément du reste.
Pour être plus précis concernant les coordonnées GPS, c’est une variable divisée en deux variables numériques, la latitude et la longitude. Nous pourrions les considérer comme variables numériques mais on perdrait le lien entre les deux variables.
Encodage de hrmn, du mois et de la position GPS
L’encodage de la variable hrmn, qui correspond à l’heure de l’accident, est un peu moins évident que celui des variables catégoriques. Pour le faire, j’ai considéré 24 catégories correspondants à chaque heure de la journée. Par exemple, 00h15 correspond à la catégorie 0. L’horaire 15h27 correspond à la catégorie 15.
On commence par créer une serie pandas dans laquelle chaque horaire est associée à la catégorie qui lui correspond.
hrmn=pd.cut(victime['hrmn'],24,labels=[str(i) for i in range(0,24)])
Si vous souhaitez être plus précis encore, vous pouvez encoder l’heure sur 48 (toutes les 30 minutes) ou même 96 catégories (toutes les 15 minutes). Pour l’application qui nous intéresse je ne pense pas que cela soit utile.
On remplace maintenant la colonne des horaires des accidents par la colonne des catégories d’horaires :
victime['hrmn']=hrmn.valuesPour l’encodage des variables latitude et longitude nous allons utiliser une autre astuce beaucoup plus coûteuse. J’ai regroupé ces deux variables dans une colonne de tuples. Avec la méthodes des k-means, j’ai découpé la zone géographique couverte en 15 zones différentes que j’ai numérotées de 1 à 15.
Le choix de 15 est arbitraire. On pourrait néanmoins l’optimiser pour trouver les cluster les plus pertinents.
L’idée est encore une fois de transformer cette variable en une variable catégorique.
# On extrait du tableau la latitude et la longitude
X_lat = victime['lat']
X_long = victime['long']
# On définit tous nos points à classifier
X_cluster = np.array((list(zip(X_lat, X_long))))
# Kmeans nous donne pour chaque point la catégorie associée
clustering = KMeans(n_clusters=15, random_state=0)
clustering.fit(X_cluster)
# Enfin on ajoute les catégories dans la base d'entraînement
geo = pd.Series(clustering.labels_)
victime['geo'] = geoEncodage One-Hot des variables catégoriques (indispensable pour XGBoost et Random Forest)
Une fois que nous avons sélectionnés les features, on doit encoder les variables catégoriques. C’est-à-dire transformer les colonnes avec des noms de catégories (qui sont dans notre cas pour la plupart des nombres, il faut donc les convertir en chaînes de caractères pour éviter la confusion) en matrices de 0 et de 1.
Pour cela on utilise l’encodage One-Hot. Le principe de ce type d’encodage est assez simple. Si la variable X possède n modalités (1,…,n) et si l’observation Y prend la valeur i pour X, alors on représente cette variable par un vecteur composé de 0 partout et d’un 1 à la i -ème modalité.
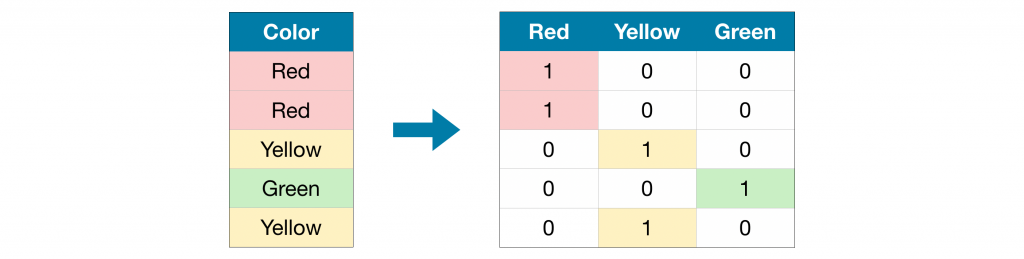
Pour faire ce travail il suffit d’utiliser la fonction get_dummies de Pandas. Encore une fois, dans notre cas il ne faut pas oublier de convertir les noms des variables en chaînes de caractères. Sinon get_dummies les considérera comme des variables numériques et n’effectuera pas l’encodage.
On regroupe toutes les variables catégoriques que l’on souhaite conserver dans la liste features.
y = victime['grav']
features = ['catu','sexe','trajet','secu',
'catv','an_nais','mois',
'occutc','obs','obsm','choc','manv',
'lum','agg','int','atm','col','gps',
'catr','circ','vosp','prof','plan',
'surf','infra','situ','hrmn','geo']L’encodage se fait maintenant très simplement :
X_train_data = pd.get_dummies(victime[features].astype(str))
Constructions des modèles : XGBoost vs Random Forest
Nous entrons maintenant dans l’étape que j’apprécie le plus, à savoir la construction du modèle.
Pour ce projet j’ai décidé de me servir de méthodes utilisant des arbres de décisions. Les réseaux de neurones ne donnant pas de résultats satisfaisants sur ce type de bases de données. De plus, les autres méthodes de clustering supervisés ne sont pas aussi précises.
Les méthodes Random Forest (littéralement forêts d’arbres aléatoires) et XGBoost semblent être les plus adaptées pour la résolution de ce problème.
Avant d’expliquer le fonctionnement des modèles que j’ai utilisé, il faut comprendre le concept d’arbre de décision.
Un arbre de décision est un objet mathématique qui permet de représenter un ensemble de choix. A chaque nœud on choisit le résultat qui correspond à nos données. Cela nous donne le résultat de la classification. Un arbre de décision est défini par ses facteurs discriminants.
Random Forest
Comme son nom l’indique, l’algorithme random forest met en jeu un grand nombre d’arbres aléatoires.
On comprend bien que le choix des facteurs discriminants est primordial. Random Forest le fait pour nous. L’idée est de maximiser le nombre d’éléments à éliminer après chaque question. On crée les questions de haut en bas. Pour faire cela, l’algorithme calcul ce que l’on appelle l’entropie.
L’entropie est une mesure de dispersion des données. Si on peut les séparer en deux classes bien éloignées, l’entropie est faible. Sinon l’entropie sera élevée. Pour trouver les questions optimales, Random Forest cherchera les questions qui engendrent l’entropie la plus faible.
Une fois que l’on a construit l’arbre, on réitère le procédé pour d’autres features. Le principe de Random Forest est qu’il construit un grand nombre d’arbres et fonctionne par vote majoritaire pour trouver la classe de chaque instance.
Si vous souhaitez en savoir plus sur les détails techniques, référez vous à notre article sur ce sujet.
# On commence par normaliser les données :
X_train = normalize(X_train.values)
# On divise la base en bases d'entraînements et de test :
X_train_rf, X_test_rf, y_train_rf, y_test_rf = train_test_split(X_train,y)
# On construit le modèle :
model_rf = RandomForestClassifier(n_estimators=100,
max_depth=8
)
# L'entrînement commence :
model_rf.fit(X_train_rf, y_train_rf)
# On a maintenant les prédictions pour la base de test
predictions_test = model_rf.predict(X_test_rf)
# On calcul de même les prédictions pour la base train
predictions_train = model_rf1.predict(X_trainrf)
# Les résultats sont calculés de cette manière :
train_acc = accuracy_score(y_trainrf, predictions_train)
print(train_acc)
test_acc = accuracy_score(y_testrf, predictions_test)
print(test_acc)Il est important de calculer les predictions pour les bases d’entraînements aussi, cela permet de voir à quel point le modèle colle avec les données. Cela permet notamment de détecter s’il y a overfitting.
XGBoost
Le principe derrière les algorithmes de gradient boosting est le même que pour random forest. Il y a tout de même deux différences notables :
- La construction des arbres se fait l’un après l’autre. Les arbres dépendent les uns des autres. J’ai d’ailleurs remarqué une différence significative dans le temps d’exécution entre les deux méthodes, random forest est beaucoup plus rapide.
- Random Forest fonctionne par vote majoritaire et combine les résultats à la fin du processus. XGBoost combine les résultats au fur et à mesure.
XGBoost me paraissait donc globalement plus intéressant que random forest. Le seul problème que j’ai remarqué est que XGBoost est plus difficile à paramétrer, notamment en ce qui concerne l’overfitting. Par exemple, il m’a semblait que les méthodes de Gradient Boosting soient très sensibles aux profondeurs des arbres.
# On redécoupe la base en train/test
X_train, X_test, y_train, y_test = train_test_split(X_train,y)
# On crée le modèle :
model_boosting = GradientBoostingClassifier(loss="deviance",
learning_rate=0.2,
max_depth=5,
max_features="sqrt",
subsample=0.95,
n_estimators=200)
# L'entraînement débute :
model_boosting.fit(X_train, y_train)
# On calcul les prédictions
predictions_test_xgb = model_boosting.predict(X_test)
predictions_train_xgb = model_boosting.predict(X_train)
# On affiche les résultats :
train_acc = accuracy_score(y_train, predictions_train_xgb)
print(train_acc)
test_acc = accuracy_score(y_test, predictions_test_xgb)
print(test_acc)Résultats finaux : XGBoost ou Random Forest ?
La dernière étape est celle ou on fait le bilan des deux méthodes. Et vous verrez que pour un problème de classification comme le notre, cette étape est loin d’être évidente.
La première métrique que l’on peut définir est la précision (accuracy). C’est simplement le pourcentage de bonnes prédictions par rapport au nombre total de prédictions.

Cette métrique n’est pas assez précise, elle ne donne pas d’informations sur le type d’erreurs que l’on fait.
Pour corriger ça, on introduit le recall (le rappel en français). Cette métrique correspond, pour une classification binaire, au nombre de prédictions positives du modèle sur le total des prédictions qui devraient être positives.
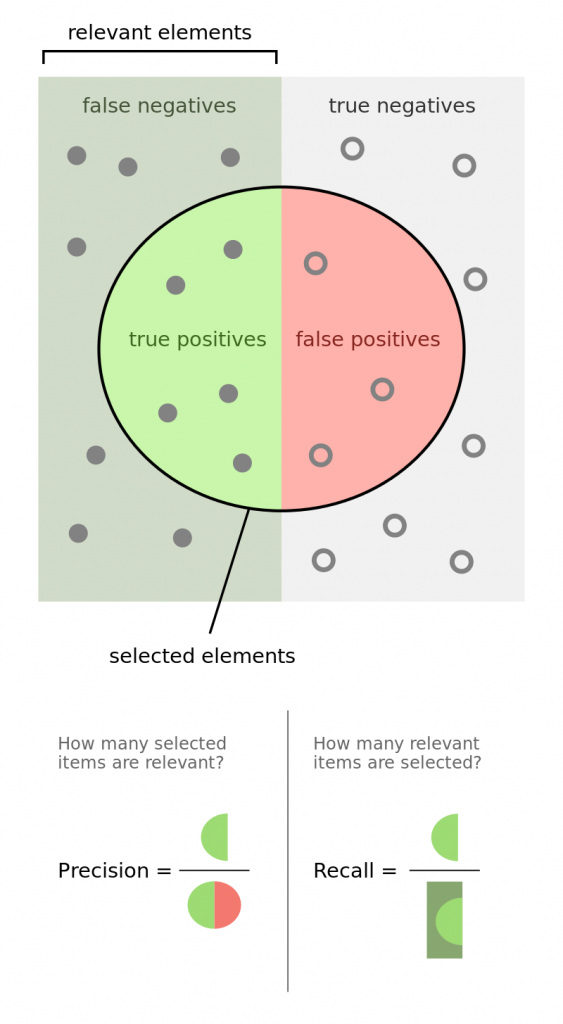
Pour un problème multiclasses comme le notre, le recall est un mix entre tous les recall de chacune des catégories.
# Calcul du recall pour Random Forest
recall = recall_score(y_test_rf, predictions_test, average='macro')
print('Recall: %.3f' % recall)
# Calcul du recall pour XGBoost
recall = recall_score(y_test, predictions_test_xgb, average='macro')
print('Recall: %.3f' % recall)
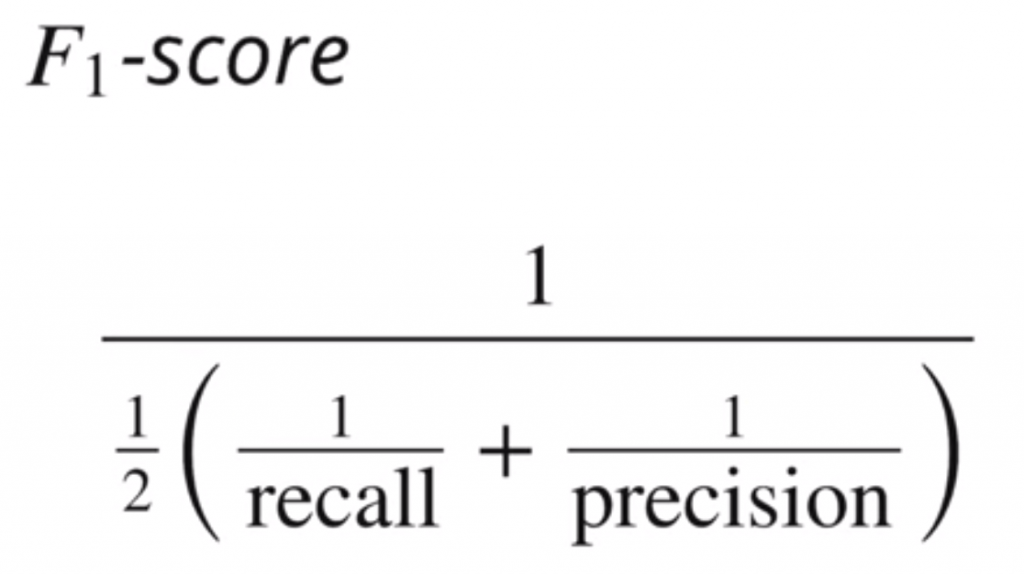
Pour combiner toutes ces informations, on introduit souvent une métrique que l’on appelle le F1-Score. Il est calculé de cette manière :
# Calcul du F1-Score pour Random Forest
f1 = f1_score(y_test_rf, predictions_test, average='macro')
print('F1-Score: %.3f' % f1)
# Calcul du F1-Score pour XGBoost
f1 = f1_score(y_test, predictions_test_xgb, average='macro')
print('F1-Score: %.3f' % f1)Les résultats obtenus sont les suivants :

Il semblerait donc que XGBoost soit meilleur que Random Forest pour cette base de données.
C’est d’ailleurs ce qui explique la tendance qui se dégage ces dernières années. XGBoost est devenu la star des algorithmes de machine learning. C’est dû principalement à son efficacité et sa facilité d’utilisation.
Perspectives d’améliorations
Comme on le voit les résultats obtenus sont assez décevant. Comme je l’ai expliqué en introduction, l’objectif n’était pas d’optimiser nos modèles mais seulement de comparer les deux approches proposées.
Néanmoins, on peut tout de même se demander comment améliorer ces résultats.
Optimisation des hyperparamètres pour XGBoost et Random Forest
Une information que j’ai passé sous silence est le fait que Random Forest et XGBoost sont des algorithmes très flexibles. Cela implique une grande minutie au moment des choix des paramètres.
Deux méthodes peuvent aider à optimiser les paramètres :
- Grid Search
- SMBO
Rééquilibrer les catégories
Nous avons une autre source importante d’erreurs. Nos données sont très biaisées. Les catégories sont représentées de manières très inégales.
On peut le voir très facilement en construisant un diagramme.
y = victime['grav']
values = np.unique(y,return_counts=True)[1]
labels = ['Classe 1','Classe 2','Classe 3','Classe 4']
sizes = values
# Choix des couleurs
colors =['#fff100','#ff8c00','#e81123','#ec008c']
# Construction du diagramme et affichage des labels et des #fréquences en pourcentage
fig1, ax1 = plt.subplots()
ax1.pie(sizes, colors = colors, labels=labels, autopct='%1.1f%%', startangle=90)
# Tracé du cercle au milieu
centre_circle = plt.Circle((0,0),0.70,fc='white')
fig = plt.gcf()
fig.gca().add_artist(centre_circle)
# Affichage du diagramme
ax1.axis('equal')
plt.tight_layout()
plt.show()On obtient le résultat suivant :
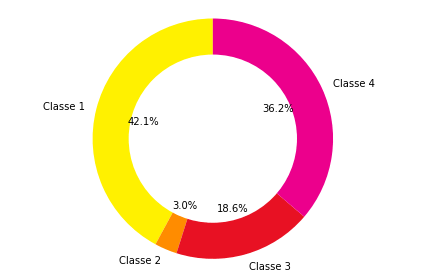
Le résultat est que le modèle prédira plus souvent la classe 1 et 4 au détriment des classes 2 et 3. Des techniques existent pour rééquilibrer les catégories. Sous Scikit-learn on peut facilement ajouter des poids pour Random Forest. L’implémentation pour XGBoost est un peu plus compliquée.
Une autre option serait d’entraîner le modèle en regroupant les classes 2 (tué) et 3 (hospitalisé) dans un premier temps. Il faudra ensuite construire un autre modèle ne faisant intervenir que les classes 2 et 3, qui soit capable de les séparer. Cela pourrait fonctionner vue la proximité que l’on a entre les 2 classes. Faites moi signe si vous essayez cette méthode !
Voilà pour ce projet, j’espère qu’il vous a plu. Vous avez d’autres idées pour améliorer nos modèles ?


Laisser un commentaire