
La prédiction d’événements futurs a toujours passionné les hommes. Aujourd’hui je vous explique l’algorithme de prédiction par excellence : random forest.
De nombreuses méthodes de prédictions ont vu le jour au travers de notre histoire, comme par exemple l’art divinatoire. Une de ces méthodes consistait à lire l’avenir sur les arbres. C’est la dendromancie, pour les plus avides de culture d’entre vous. Vestige d’un lointain passé me direz-vous ?
Et si je vous disais qu’aujourd’hui encore, on se sert d’arbres pour tenter de prédire l’avenir ?
L’arbre de décision : le composant principal de random forest
Bien évidemment, vous n’aurez pas besoin d’aller dans la nature pour prédire des tendances économiques ou des résultats informatiques. Il s’agit ici d’arbres de décision.
Ces derniers permettent en effet de représenter un ensemble de choix sous la forme d’un arbre. Le principal intérêt d’une telle structure en informatique décisionnelle est sa hiérarchisation des décisions.
Cette suite de choix permettra de prédire à quelle classe appartient l’individu testé. Les arbres décisionnels sont par exemple très utilisés dans le domaine du marketing téléphonique. Par exemple pour prédire quel produit un client sera le plus susceptible d’acheter. Pour cela on utilise des informations comme son âge, son métier, s’il est locataire ou propriétaire, etc.
Ils peuvent également être utilisés dans le cadre de l’apprentissage de modèles d’intelligence artificielle. Par exemple pour la reconnaissance d’image (pour lui apprendre à différencier une image de poisson de celle d’un oiseau, entre autres) même si pour ce genre de choses se sont les réseaux de convolutions qui sont utilisés.
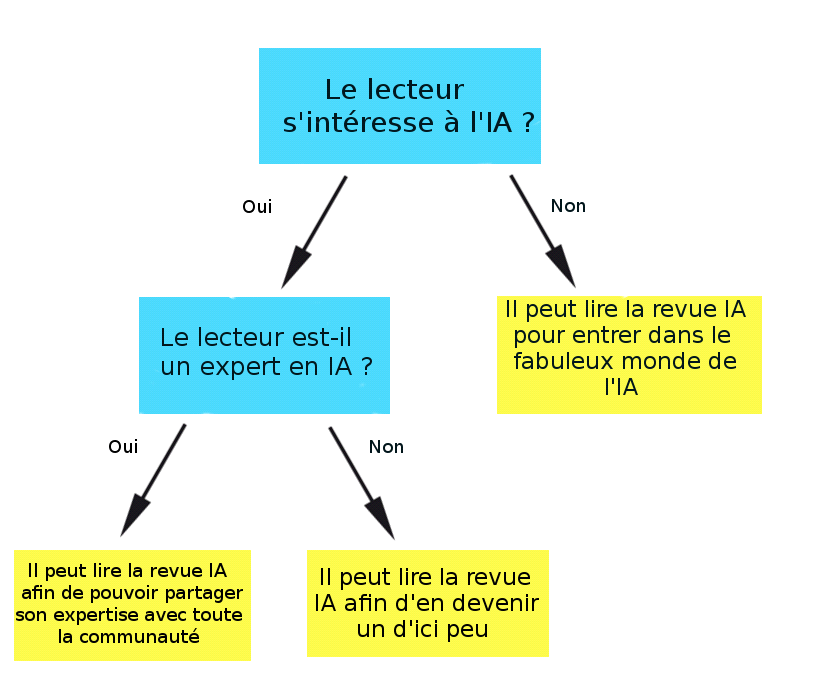
Vous l’aurez compris, le principal avantage de ces arbres est leur simplicité. Il suffit de prédéfinir les facteurs discriminants. Ceux-ci permettent de construire notre arbre.
Il aura pour nœuds les tests portant sur ces facteurs (« Le candidat a-t-il est des plumes ? », « De quelle couleur est-il ? ») et pour feuilles les classes/choix finaux (« Le candidat est un poisson », « Le candidat est un oiseau »).
Et si, encore mieux, vous n’aviez même pas à réfléchir vous-mêmes aux différents tests qui permettront de prédire la classe à laquelle appartient votre candidat ?
Il existe en effet des algorithmes qui à partir d’un ensemble de données initiales (qui servent d’exemples d’apprentissages) peuvent déduire les tests qui seront pertinents pour déterminer la classe de votre entrée.
L’intérêt de l’arbre étant sa simplicité, il paraît naturel de limiter le nombre de nœuds. Cela permet de trouver le plus rapidement possible à quelle classe appartient le candidat.
La construction de l’arbre se fait alors pas à pas, en cherchant toujours à répondre à cette question : quel attribut permet de maximiser le gain d’information lors de cette étape ?
Construction de l’arbre, introduction de la notion d’entropie
Pour répondre à cette question, il convient d’introduire la notion d’entropie. Pour les plus physiciens d’entre vous, ce terme vous est familier : l’entropie est un indicateur de désordre. Plus celle-ci est élevée, plus c’est le ‘’bazar’’. Elle est ici donnée par le nombre de candidats appartenant à différentes classes suite au test.
Par exemple, un test qui divise une classe en deux classes non finales de même taille possède une entropie élevée, car il y aura encore beaucoup de tests à conduire. Au contraire, si tous les objets appartiennent finalement à la même classe, il n’y a aucun désordre : nous sommes arrivés à une feuille, chaque chose est à sa place.*
La construction se fait de manière récursive (on appelle cela « a top-down induction »). Initialement, notre arbre est vide. Puis, l’algorithme sélectionne le test qui engendre l’entropie minimale, et en fait sa racine.
L’algorithme s’intéresse alors à l’un des fils de cette racine, et réitère le procédé pour choisir quel test se fera à ce nœud, et ainsi de suite. Enfin, si tous les exemples qu’il reste à traiter appartiennent à la même classe (on a donc une entropie nulle), ou s’il n’y a plus de test à effectuer, c’est que nous sommes arrivés à une feuille, et l’algorithme termine : votre arbre de décision est prêt, à vous l’art de la divination.
L’arbre qui cache la forêt : l’algorithme random forest
Bon, tout cette verdure, c’est bien joli, mais moi, je vous ai promis une forêt toute entière. Après vous avoir vanté les vertus des arbres de décisions, vous êtes en droit de vous demander quel est l’intérêt de disposer d’une forêt entière. Le principal souci de ces arbres est en réalité leur optimalité.
Comme vous l’avez constaté, nous les construisons pas à pas, prenant le test le plus judicieux à chaque étape. Une telle démarche est courante en informatique et est appelée « algorithme glouton ».
Cependant, si cette méthode est considérée comme une première approche naïve satisfaisante, il n’en demeure pas moins qu’elle peut être très (très !) loin du résultat optimal. Ceci est dû au fait que chaque test n’apparaît qu’une fois dans l’arbre. **
Pour pallier ce problème, Leo Breiman et Adèle Cutler ont proposé en 2001 la notion de forêts aléatoires ou random forest. L’idée est de créer un grand nombre d’arbres de décisions de façon aléatoires, à partir de différents sous-ensembles de données de l’ensemble de données initial.
Le fait de considérer différents sous-ensembles est important : cela réduit les risques d’erreur, puisque nos arbres seront peu corrélés. On évite alors également le problème du surapprentissage, qui intervient lorsque l’arbre construit s’est trop adapté à l’échantillon considéré.
Il aura considéré tous les tests possibles, chaque feuille ne représentant qu’un unique candidat. Cet arbre sera donc fiable à 100% pour l’échantillon ayant permis sa construction (puisqu’il prend en compte tous les tests possibles), mais ne sera pas généralisable à d’autres échantillons.
Le candidat est alors testé sur chacun de ces arbres (qui peuvent être plus d’une centaine). L’intérêt de la forêt est de procéder par vote majoritaire quant aux résultats obtenus. On réduit ainsi la marge d’erreur que peut avoir un arbre seul. Plus l’on dispose d’arbres, plus la forêt sera fiable.
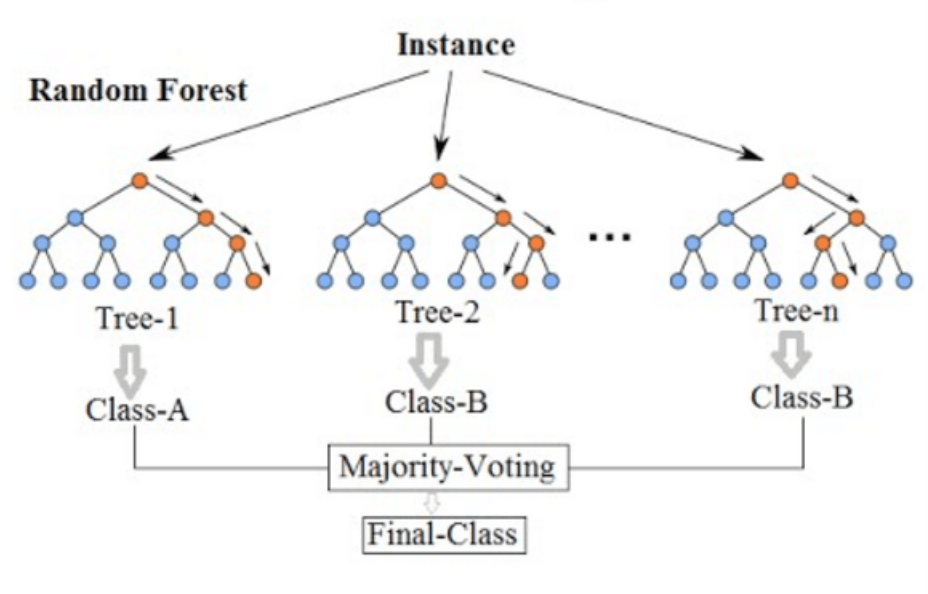
Eviter l’overfitting
Une autre raison pour laquelle random forest est si efficace, est qu’il permet de réduire l’overfitting. Et c’est aussi une des raisons qui a motivée l’utilisation de plusieurs arbres.
Les arbres de décisions ont une architecture qui leur permet de coller parfaitement aux données d’entrainement. C’est ce que l’on demande à un algorithme d’apprentissage supervisé. Néanmoins, à partir d’un certain point, le modèle devient beaucoup trop influencé par les données d’entraînements, ce qui peut engendrer des biais.
L’utilisation de plusieurs arbres offre une meilleure flexibilité et permet de réduire ce problème. C’est le même principe que pour une foule de personnes. La psychologie des foules montre qu’une intelligence plus forte que l’intelligence humaine se dégage d’un ensemble de personne.
C’est par exemple ce qui fait que lors d’un concert, le public chante toujours juste alors que la majorité des gens chantent faux. Chaque personne corrige les erreurs de ses voisins, comme pour les arbres.
Attention quand même, il est encore très facile de tomber dans l’overfitting avec Random forest. Plus qu’avec d’autres méthodes comme XGBoost.
Random forest est un algorithme avec une forte interprétabilité
Un des grands défis du machine learning ces dernières années est l’explicabilité (ou interprétabilité) des modèles.
On a d’ailleurs un dilemme entre efficacité et explicabilité des modèles. Souvent les modèles les plus efficaces, comme les réseaux de neurones avec le deep learning, sont les moins explicables.
Random Forest est une solution plus que crédible pour ce dilemme. Son efficacité est assez bonne et on a des techniques pour interpréter les résultats. On peut par exemple déterminer quelles sont les features qui ont été déterminantes pour l’obtention d’une prédiction. Random forest offre une meilleur transparence sur l’utilisation faites des données d’entrainement.
Finalement, random forest présente l’avantage d’utiliser plus intelligemment l’ensemble de ses données initiales, afin de limiter ses erreurs. Toutefois, l’algorithme ne pourra jamais être à 100% fiable (il faudrait disposer d’une infinité d’arbres) et perd de la simplicité de notre arbre de décision seul.
Malgré tout, cela reste l’un des classifieurs les plus efficaces et les plus utilisés de nos jours (en témoigne son utilisation pour la classification d’images de la Kinect ou son utilisation dans le tutoriel Kaggle pour prédire qui sont les survivants du naufrage du Titanic, par exemple).
Amis indécis et voyants en herbe, n’hésitez plus : la réponse à tous vos problèmes (ou presque) se trouve dans les random forest !
* Si le concept d’entropie pour ces tests vous intéresse, je vous conseille de jeter un œil à la définition de Shannon en 1948 ainsi qu’à l’algorithme ID3 qui explicitent plus formellement tout ce que je viens de vous raconter, à l’aide de jolies formules.
** Vous pouvez aussi voir un petit exemple qui montre que l’algorithme glouton n’est pas optimal, dans le cas du problème du voyageur de commerce.

Laisser un commentaire