
Dans de précédents articles, nous avons parlé des méthodes d’apprentissages supervisé et non supervisé. Aujourd’hui je vous présente une autre méthode d’apprentissage, appelée apprentissage par renforcement ou reinforcement learning en anglais.
Comme en apprentissage non supervisé, dans le cadre d’un apprentissage par renforcement l’IA apprend toute seule. Mais le mode d’apprentissage est différent de celui observé en non supervisé.

Cette technique commence à faire ses preuves pour de nombreuses applications. Et c’est surtout dans les jeux vidéos que l’apprentissage par renforcement impressionne.
Principe de l’apprentissage par renforcement et analogie avec l’apprentissage humain
L’apprentissage par renforcement, est un mode d’apprentissage statistique, inspiré de l’apprentissage humain et animal. En tant qu’humain, nous expérimentons certaines choses (pas très intelligente parfois haha).
Lorsqu’elles ont un résultat positif et induisent des récompenses, on conclut que ces expériences sont positives et qu’elles doivent être réitérées. Inversement, si le résultat de l’expérience n’est pas concluant, on le mémorise pour ne plus faire la même erreur.
Ainsi, dans le cadre d’un apprentissage par renforcement, l’IA veut maximiser ses récompenses. Exactement de la même façon qu’un étudiant veut maximiser ses notes, par exemple.
Cette notion de ‘’récompenses’’ dépend du contexte. L’IA de YouTube ou celle de Facebook, voudra maximiser le temps que vous passez sur sa plateforme. L’IA d’Amazon voudra vous faire dépenser le maximum d’argent. La récompense est illustrée par une fonction qui dépend de ce que l’on souhaite faire avec notre modèle.

En biologie comportementale, le concept de ‘’conditionnement opérant’’, étudié par Skinner notamment, s’intéresse à cette notion d’apprentissage par renforcement chez les êtres vivants.
Un comportement récompensé aura tendance à être plus adopté qu’un comportement punit. Skinner a expérimenté cela sur des pigeons. Lorsque le pigeon exécute ce qui lui a été demandé, il reçoit une récompense.
L’objectif de l’expérience était d’apprendre au pigeon la signification du mot ‘’Turn’’. Si le pigeon tourne lorsque ce mot lui est montré, on lui donne une récompense. On observe une amélioration des résultats au fur et à mesure des récompenses.
Applications de l’apprentissage par renforcement
On a longtemps sous-estimés les techniques d’apprentissage par renforcement. Si bien qu’elles sont aujourd’hui encore, dans l’ombre des réseaux de neurones et d’autres méthodes de machine learning.
D’ailleurs, en dehors des IA dans les jeux vidéos, on a pas énormément de cas d’usages de l’apprentissage par renforcement. Voici ceux que je connais.
Contrôle automatisé des feux tricolores
Source : Towards Data Science
La smart city est un des sujets à la mode dans la tech. Et parmi les choses à prendre en compte il y a la circulation.
L’apprentissage par renforcement semble offrir de belles opportunités pour une gestion plus intelligente des feux tricolores. Néanmoins, cette utilisation n’a été testée que sur des simulations. Elle pourrait tout de même donner de bons résultats dans un environnement réel.
Robotique : saisie d’objets par des robots
Une autre application de l’apprentissage par renforcement est la saisie automatique d’objets. Longtemps les limites des robots que l’on utilisait dans l’industrie étaient principalement industrielle. Néanmoins, aujourd’hui nous sommes capables de construire des robots qui sont impressionnant d’un point de vue physique et qui peuvent faire différents types de mouvements.
Le nouveau challenge auquel nous faisons fasse concerne plutôt la partie software. Dans ce domaine l’apprentissage par renforcement semble être une excellente solution.
L’apprentissage par renforcement pour les systèmes de recommandations
Une des particularités des systèmes de recommandations est qu’ils doivent flexibles et s’adapter aux changements des préférences des utilisateurs. On ne peut pas entrainer un système de deep learning en continue pour pallier ce problème.
C’est là qu’intervient l’apprentissage par renforcement. Le système va récupérer en temps réel des informations à la fois sur les utilisateur et sur le contenu, et va calculer des prédictions à partir de ça. La récompense sera alors donnée par la réaction de l’utilisateur. Les métriques de réussite dépendent du système.
Par exemple dans les réseaux sociaux ce sont les likes ou les commentaires qui vont être pris en compte. L’IA de Netflix regardera plutôt le temps passé par un utilisateur sur le contenu proposé. Celle d’un site de e-commerce verra si le client a acheté le produit ou non.
Fonctionnement de l’apprentissage par renforcement sur des machines
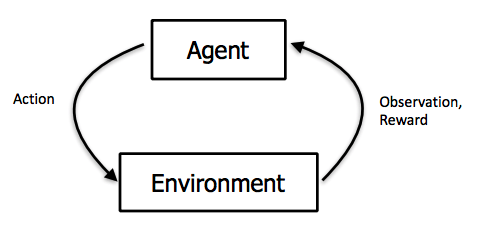
Contrairement à l’apprentissage supervisé, en apprentissage par renforcement on ne fournit pas de données d’entrainement à l’algorithme. Il acquiert ces données directement au contact de son environnement et il les mémorise.
A chaque pas de temps, l’algorithme fait certaines actions qui vont modifier son état. Cela lui apportera une récompense locale. La fonction de valeur correspond au cumul des récompenses. C’est cette fonction que l’algorithme doit maximiser.
Ainsi, lorsque l’on met en place un algorithme d’apprentissage par renforcement, il faut que cet algorithme agisse conformément à ce qu’il a mémorisé, tout en changeant parfois de stratégie pour améliorer son score. On parle de dilemme exploration- exploitation.
Q-Learning
L’algorithme d’apprentissage par renforcement qui est le plus utilisé est le Q-Learning. Son fonctionnement repose sur le calcul de l’action optimale. C’est celle qui maximise l’espérance des récompenses des prochains états, en prenant en compte un facteur d’actualisation.
Brièvement, le facteur d’actualisation est une constante comprise entre 0 et 1 qui donne une idée de l’importance des états futurs dans notre étude. S’il vaut 0, on ne considère que les états présents. S’il vaut 1 on donne plus d’importance à des étapes futurs.
Le facteur d’apprentissage (learning rate) est un indicateur de la vitesse d’apprentissage. Un facteur d’apprentissage élevé signifie que l’état est très modifié entre deux étapes.
Les méthodes d’apprentissages par renforcement sont terriblement efficaces. En effet, c’est grâce à ce type d’algorithmes (amélioré avec du deep learning), qu’une machine a battu au jeu de Go le champion du monde, Lee Sedol. On lui a seulement fourni les règles du jeu. L’algorithme a appris les stratégies en simulant des millions de parties. En quelques heures il a atteint le niveau du champion du monde.
Les notions mathématiques sous-jacentes, reposent principalement sur les processus de décisions Markovien, qui font intervenir des méthodes de calculs de probabilités et de calcul stochastique.
L’apprentissage par renforcement pour réduire le nombre de données
Il ne vous aura pas échappé que les modèles de deep learning d’aujourd’hui sont très gourmands en données. Pour construire un modèle de computer vision assez performant, vous devrez passer plusieurs heures à collecter et labelliser manuellement des images. C’est d’ailleurs une des raisons pour lesquelles je n’aime pas trop la comparaison entre l’apprentissage des machines et l’apprentissage des enfants.
Un enfant n’a pas besoin de milliers d’images de girafes pour comprendre le concept de girafe. Pour apprendre une nouvelle langue vous ne lisez pas tous les livres disponibles dans cette langue.
D’ailleurs, selon Yann Le Cun, pour faire passer l’intelligence artificielle dans une nouvelle dimension il faudra construire des modes d’apprentissage qui sont moins basés sur les données. Il décrit 3 types d’apprentissage chez les enfants qui pourraient être adaptés pour les machines :
- L’apprentissage par l’observation : on voit quelqu’un réalise une tâche, on copie la personne
- L’apprentissage supervisé (parents, professeurs pour les enfants ou data en ce qui concerne les machines)
- L’apprentissage par renforcement : l’enfant se brûle en touchant une casserole, il comprend la douleur lui fait apprendre la notion de chaleur
L’apprentissage par renforcement semble donc être une solution intéressante pour réduire la quantité de données nécessaires.
L’autre solution envisageable, et dont Yann Le Cun est un grand adepte, est le self-supervised learning, mais ça sera le sujet d’un prochain article.
L’analogie faite avec l’apprentissage est a relativiser. En effet, en tant qu’humain, on se base aussi sur le travail des autres pour réussir. Pas seulement sur ce que l’on vit au quotidien. C’est le principe de la théorie d’Adam Smith, pour qui « les ambitions individuelles servent la communauté ».
L’apprentissage humain semble plus se rapprocher d’un mélange entre apprentissage supervisé et apprentissage par renforcement.



Laisser un commentaire