Le cerveau humain est si complexe, que même les plus grands neurologues ne savent pas le décrire complètement. Néanmoins, avec ce que l’on connait, on peut construire quelque chose de formidable. Une technologie sur laquelle les meilleurs intelligence artificielle d’aujourd’hui reposent : les réseaux de neurones artificiels.
Cette technologie est inspirée du fonctionnement du système nerveux de notre cerveau. Il faudrait des centaines de pages pour la comprendre en profondeur, mais comme vous êtes très fort, quelques mots suffiront pour comprendre ce que sont les réseaux de neurones !
Des neurones humains aux réseaux de neurones artificiels
Avant de pouvoir parler de neurones artificiels, décrivons le fonctionnement du neurone humain.
Un neurone biologique est une cellule caractérisée par plusieurs composants. Les synapses sont les points de connexion entre neurones. Les dendrites constituent les entrées du neurone et les axones leurs sorties vers d’autres neurones.
Le corps cellulaire se charge d’activer plus ou moins le neurone, en fonction des intensités électriques des signaux excitateurs. Cette activation se produit lorsque le potentiel d’action du neurone dépasse un certain seuil, que l’on appelle ‘’potentiel d’activation’’.

Pour modéliser simplement les neurones biologiques, des neurologues introduisirent dans les années 40, la notion mathématique de neurone formel.
Schématiquement, un neurone formel possède plusieurs entrées et une sortie. On distingue les synapses activatrices et les synapses inhibitrices.
Mathématiquement, les neurones proposés initialement sont des neurones binaires qui ont une sortie valant 0 ou 1. Cette sortie est calculée par le neurone, à l’aide d’une somme pondérée de ses entrées. Une fonction d’activation est ensuite appliquée à cette somme. Si le résultat est supérieur à un ‘’seuil d’activation’’, la sortie vaudra 1, sinon elle vaudra 0.
C’est quoi les réseaux de neurones ?
En intelligence artificielle, les réseaux de neurones sont des assemblages de plusieurs couches de neurones. Il existe des centaines de types de réseaux de neurones différents. Le principe est toujours le même, c’est l’architecture qui est différente à chaque fois.
L’architecture des réseaux de neurones diffère en fonction de l’application
De manière générale, les réseaux de neurones sont un ensemble de neurones, organisés en plusieurs couches et reliés entre eux.
La première couche est appelée input layer, la dernière output layer et les couches qui se situent entre les deux sont appelées hidden layers. Il peut y en avoir un très grand nombre, selon les domaines d’applications.
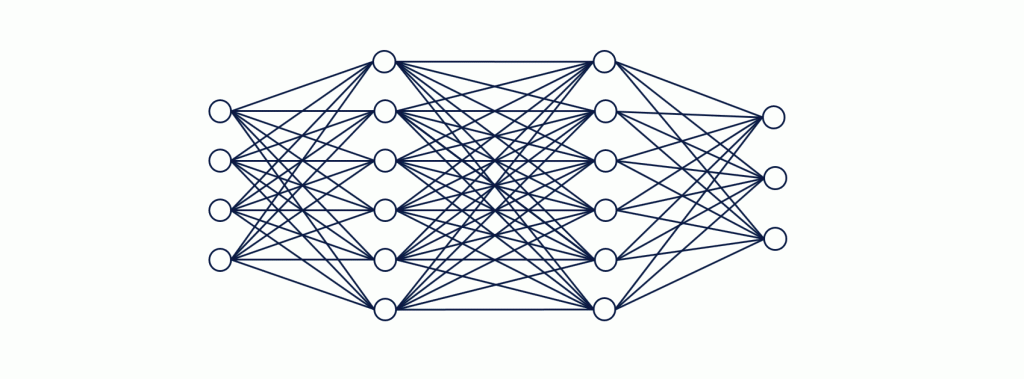
En pratique, les neurones de la première couche vont transmettre des informations simples aux neurones de la couche suivante. Ce qui aura une influence sur leur degré d’activation et ainsi de suite. La dernière couche nous fournira alors des informations sur le résultat.
Par exemple pour un système de reconnaissance de chiffre, les entrées seront les niveaux de gris des pixels de l’image. Le résultat sera la probabilité qu’en entrée on ait mis un chiffre en particulier. Si on a entré une image représentant le chiffre 5, on s’attend à ce que le chiffre 5 soit associé à une probabilité plus grande. Et que les autres chiffres soient associés à des probabilités proches de 0.
Théorème fondamental
Cette méthode, qui repose sur une suite d’opérations ‘’simples’’, permet d’approximer des fonctions très complexes. McCulloch et Pitts l’ont prouvé en montrant qu’un réseau de neurones formels a la même puissance de calcul qu’une machine de Turing. C’est en partie grâce à cela que cette technologie s’est imposée comme une méthode prépondérante en machine learning.
Les réseaux de neurones vérifient le théorème fondamental d’approximation universel. C’est ce qui nous assure l’existence d’un réseau de neurones qui, pour une fonction donnée, nous donne une approximation de cette fonction avec une erreur aussi petite que l’on veut. C’est un résultat très fort !
En pratique, chaque neurone a deux paramètres, le biais et le poids. L’idée est donc de trouver le paramétrage de tous les neurones du réseau qui minimise l’écart entre la fonction que l’on veut approximer et la fonction modélisée par le réseau. L’existence de ce paramétrage est déduite par le théorème précédent.
Malheureusement, pour beaucoup de fonctions il est impossible de trouver ses paramètres, on sait seulement qu’ils existent. Il faudrait des temps de calculs gigantesques pour pouvoir les trouver.
Entraîner un réseau de neurones est en pratique un exercice d’optimisation
Les réseaux de neurones sont des méthodes d’apprentissage supervisé. Nous disposons donc de données initiales, pour lesquelles on connait la sortie du réseau.
Le travail que l’on fait sur les paramètres de notre réseau a pour objectif de minimiser l’écart entre la sortie attendue et la sortie effective (celle fournit par le réseau de neurone). Cet écart peut-être calculé par l’erreur des moindres carrés ou d’autres métriques de l’erreur, on parle de loss function.
Et l’objectif de la phase d’entraînement est d’optimiser cette fonction de perte. L’entrainement du réseau est une recherche des biais et des poids qui minimisent la fonction de perte.
En mathématiques et plus spécifiquement en optimisation, il existe énormément de méthodes pour minimiser des fonctions. Celle qui est souvent utilisée, est la méthode de descente de gradient. Pour cette méthode, des calculs de dérivées partielles de la fonction de perte sont nécessaire.
Il faut comprendre que ces calculs sont faisables dans le cas des réseaux de neurones, mais pour une machine quelconque, ce calcul peut être très compliqué à réaliser. C’est la raison pour laquelle certains chercheurs expliquent l’efficacité des réseaux de neurones, par le fait que les gradients sont faciles à calculer.
D’où viennent les réseaux de neurones ?
Contrairement à ce que l’on pourrait croire, les réseaux de neurones datent des années 50. Sévèrement critiqués jusque dans les années 90, ce n’est qu’à partir de 2010 qu’ils deviennent incontournables.
Même si leurs forts potentiels étaient visibles, ils nécessitent beaucoup de données et les systèmes de stockage et de traitement de données n’étaient clairement pas adaptés.
Le perceptron multicouche
Le perceptron multicouche est un cas particulier de réseau de neurones, c’est le plus ancien. L’entrée du perceptron est un vecteur de dimension d, on place une composante du vecteur par neurone de l’input layer. L’objectif du réseau de neurones sera de séparer les entrées en fonction de la valeur du vecteur correspondant, afin de créer différentes classes.
C’est donc un réseaux de neurones de clustering. Par exemple, si notre réseau doit déterminer s’il y a un visage humain sur une photo, les deux issues possibles sont Vrai. Dans le cas où un visage humain est présent sur la photo. Ou Faux dans le cas contraire.
Cet exemple constitue le cas simple où l’on aurait uniquement deux classes. On peut généraliser la classification à plusieurs dimensions. Pour cela on a des techniques comme le One vs All ou One vs One.
Même si aujourd’hui le perceptron n’a qu’une vocation pédagogique, il a inspiré le développement de beaucoup de techniques d’apprentissage. Il est notamment à l’origine de l’avènement du deep learning.
Quelles sont les différents types de réseaux de neurones ?
Comme je vous l’ai expliqué, les architectures de réseaux de neurones différent selon les applications. Voici quelques exemples d’architectures et leurs applications.
Les réseaux LSTM pour le traitement de textes
Le NLP est le domaine du machine learning qui s’intéresse au traitement des données textuelles. Ses applications sont nombreuses. Classification de requêtes dans les moteurs de recherches. Clustering d’articles de presse. Compréhension du langage pour les chatbots et les assistants vocaux. Pour analyser des sentiments d’auteurs de textes. Les applications sont quasiment infinies.
Pour pouvoir traiter efficacement les textes, il faut que le réseau puisse comprendre les mots de façon séparées, mais aussi le contexte global. Les systèmes de NLP se sont longtemps contentés de traiter les mots séparément. Il est évident que cette approche n’est pas viable. Les réseaux de neurones de types LSTM, Long-Short Term Memory, permettent de donner de l’importance aux liens entre les mots. Le réseau se « souvient » des mots qu’il a traité plusieurs étapes après.
Les réseaux de neurones de types CNN pour la reconnaissance d’images
Les réseaux à convolution, aussi appelés CNN ou ConvNets, sont des réseaux avec une architecture adaptée à l’analyse d’images. Cette architecture est utilisée essentiellement pour de la classification, ou de la reconnaissance d’objets, ou de formes. Ils sont souvent utilisés pour la reconnaissance faciale.
Pour faire de la classification d’images, la méthode naïve consisterait à comparer deux images en parcourant tous les pixels de cette image. Cette approche a une limitation majeure.
Les capacités de calcul de nos ordinateurs sont encore limitées, même si l’informatique quantique pourrait changer cela de manière considérable. Or, les images dont on dispose sont de l’ordre du mégapixel. Ainsi, pour un smartphone bas de gamme, on a des résolutions de l’ordre d’une dizaine de millions de pixels.
Pour étudier ce genre d’images, il faudrait un réseau de neurones avec une couche d’entrée constituée de 30 millions de pixels. Inutile de préciser que la méthode de gradient ne fonctionnera pas.
Surtout que l’on traite souvent des bases de données énormes constituées de centaines de milliers d’images. Par exemple, ImageNet est une plateforme avec 14 millions d’images labellisées. Pour les systèmes de reconnaissance d’objets ces images sont souvent utilisées.
Fonctionnement des réseaux de convolutions
En pratique, les algorithmes de convolution, sont plusieurs répétitions de deux étapes : la convolution, puis le pooling.
- Convolution :
Pour contrer la limitation de l’approche naïve, les chercheurs en IA ont trouvé une solution. C’est là qu’interviennent les réseaux de neurones à convolution. Les CNN traitent les images par zones de plusieurs pixels et non pixel par pixel. On appelle ces petites zones des « caractéristiques ».
Concrètement, les caractéristiques sont de minuscules images. C’est l’opérateur qui choisit leurs tailles. Leur avantage principal est qu’elles sont faciles à étudier avec des algorithmes simples. Ceci est lié au fait qu’elles sont composées d’un faible nombre de pixels. Dès qu’on lui donne une certaine image, l’algorithme essayera de trouver les caractéristiques (que l’on aura prédéfinies). Elles sont une sorte de résumé de chaque zone de l’image.
La recherche de ces caractéristiques se fait sur toute l’image : si on veut reconnaître un objet, on doit pouvoir le reconnaître quelque soit sa position sur l’image. On dit que l’on utilise les propriétés d’invariances par translation de certains objets. Mathématiquement, cette technique est une méthode de filtrage. Elle repose sur l’opération de convolution discrète, d’où le nom réseau à convolution.

- Pooling
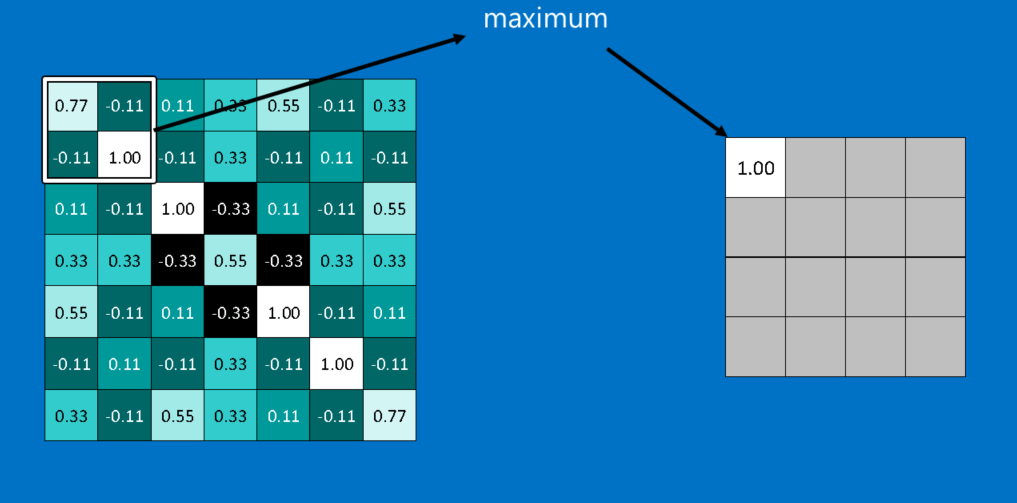
La seconde étape est celle de pooling est une méthode mathématique qui permet de réduire la taille d’une image, tout en conservant les informations principales qu’elle nous donne. Personnellement, cette méthode me fait penser aux méthodes projectives en algèbre linéaire (néanmoins il n’y a pas de bijection, donc la comparaison s’arrête là).
De façon schématique, on fait coulisser une fenêtre d’une certaine taille sur notre image, et la fenêtre sélectionne le pixel avec la plus grande valeur. Dans l’image ci-dessous, on sélectionne le pixel 1.00 et on résume l’information contenue dans ces 4 pixels par un nouveau pixel avec une valeur 1.00.
Ensuite, on réitère le procédé sur toute l’image. Cette méthode permet de diviser considérablement le nombre de pixels de l’image que l’on souhaite traiter. Cette étape n’est pas obligatoire : elle engendre des pertes d’informations et certains préfèrent s’en passer.
Voici une application, pas très utile mais qui permet de comprendre le fonctionnement d’un réseau à convolution. Google a créée le site Quickdraw pour montrer ce que l’on peut faire avec ce type d’algorithmes.
Pendant que vous dessinez l’objet demandé par l’interface, l’algorithme essaye de trouver des caractéristiques pour deviner ce que vous êtes en train de dessiner (en revanche, si vous êtes vraiment nul en dessin, laissez tomber…même l’algorithme de Google ne peut rien pour vous hahaa). Je vous laisse vous amuser !
Les réseaux de neurones de types Transformers
AUjourd’hui, lorsque l’on parle d’IA ou de deep learning, on fait souvent référence à l’architecture de réseaux de neurones de type Transformers.
Proposée en 2017 par Google et l’université de Toronto, dans un papier de recherche devenu mythique : « Attention is all need », les Transformers ont permis de résoudre un problème important dans la compréhension du langage et de la données visuelle : le problème du scale.
Contrairement aux LSTM, les Transformers peuvent être entraînés avec une quantité de données astronomique et un nombre immense de paramètres ce qui offre de nouvelles possibilités.
C’est sur cette technique que repose un outil comme ChatGPT.
Il existe de nombreux autres modèles de réseaux de neurones qui reposent sur les réseaux de neurones. Mes préférés sont les GAN !
Des réseaux de neurones simples aux deep learning
Depuis 2016 avec LeCun, Bengio et Hinton, le machine learning semble avoir franchit un cap. Les techniques de deep learning ont permis de faire des progrès impressionnant dans le traitement d’images, de données sonores ou de vidéos.
Dans les réseaux classiques, on a souvent pas plus d’une couche cachée (hidden layer). Le mot deep dans deep learning renvoi au fait que les modèles d’aujourd’hui sont construits avec beaucoup plus de hidden layers. Le principe de base est le même, c’est l’architecture des réseaux de neurones qui évolue.
Les réseaux de neurones sont en train de faire des exploits considérable. En effet, ils défient de plus en plus les humains et sont en train de nous surpasser dans plusieurs tâches qui nous étaient jusque là réservées. Néanmoins, à un réseau de neurones correspond une seule tâche. C’est ce qui constitue leur limite principale. Pour apprendre une tâche simple à une IA, des bases de données immenses combinées à des heures de travail sont nécessaires.
Serons-nous capable un jour de concevoir des réseaux de neurones généralistes ?


Laisser un commentaire