
Dans cet article on explique les bases du NLP avec Python en travaillant sur un exemple de classification de textes.
Chatbots, moteurs de recherches, assistants vocaux, les IA ont énormément de choses à nous dire. Néanmoins, la compréhension du langage, qui est une formalité pour les êtres humains, est un challenge quasiment insurmontable pour les machines. C’est d’ailleurs un domaine entier du machine learning, on le nomme NLP.
Ces dernières années ont été très riches en progrès pour le Natural Language Processing (NLP) et les résultats observés sont de plus en plus impressionnants. C’est vrai que dans mon article Personne n’aime parler à une IA, j’ai été assez sévère dans ma présentation des IA conversationnelles. Malgré que les systèmes qui existent sont loin d’être parfaits (et risquent de ne jamais le devenir), ils permettent déjà de faire des choses très intéressantes.
Du mot au vecteur
Pour comprendre le langage le système doit être en mesure de saisir les différences entre les mots. Pour cela, l’idéal est de pouvoir les représenter mathématiquement, on parle d’encodage. De la même manière qu’une image est représentée par une matrice de valeurs représentant les nuances de couleurs, un mot sera représenté par un vecteur de grande dimension, c’est ce que l’on appelle le word embedding.
Ces vecteurs sont construits pour chaque langue en traitant des bases de données de textes énormes (on parle de plusieurs centaines de Gb). En comptant les occurrences des mots dans les textes, l’algorithme peut établir des correspondance entre les mots.
Les modèles de ce type sont nombreux, les plus connus sont Word2vec, BERT ou encore ELMO. Leurs utilisations est rendue simple grâce à des modèles pré-entrainés que vous pouvez trouver facilement.
Rien ne nous empêche de dessiner les vecteurs (après les avoir projeter en dimension 2), je trouve ça assez joli !
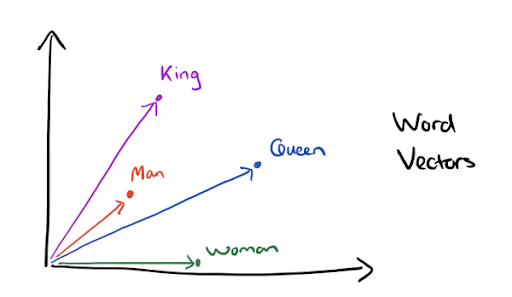
Cette représentation est très astucieuse puisqu’elle permet maintenant de définir une distance entre 2 mots. Vous pouvez même écrire des équations de mots comme : Roi – Homme = Reine – Femme
Application du NLP avec Python : classification de phrases
Pré-requis : Installation de Python
Maintenant que l’on a compris les concepts de bases du NLP, nous pouvons travailler sur un premier petit exemple. Prenons une liste de phrases incluant des fruits et légumes. Nous allons construire en quelques lignes un système qui va permettre de les classer suivant 2 catégories.
Nous verrons que faire du NLP avec Python peut être très efficace, mais il sera intéressant de voir que certaines subtilités de langages peuvent échapper au système !
Je vous conseille d’utiliser Google Collab, c’est l’environnement de codage que je préfère.
Voici nos données de départ :
phrases = ["J'ai acheté des tomates",
"La saison des oignons arrive",
'Cette mangue est très bonne',
'Ca sent les haricots',
'Je crois que je vais tomber dans les pommes',
'Penses à acheter des carottes',
"Un petit jus orange?",
"Ces fraises sont belles",
"Prend des aubergines aussi"]
Avant de commencer nous devons importer les bibliothèques qui vont nous servir :
# import des bibliothèques utiles
from gensim.models import Word2Vec
import nltk
from gensim.models import KeyedVectors
from nltk.cluster import KMeansClusterer
import numpy as np
from sklearn import cluster
from sklearn import metricsSi elles ne sont pas installées vous n’avez qu’à faire pip install gensim, pip install sklearn, …
Nettoyage des données
La première étape à chaque fois que l’on fait du NLP avec Python, est de construire une pipeline de nettoyage de nos données. L’exemple que je vous présente ici est assez basique mais vous pouvez être amenés à traiter des données beaucoup moins structurées que celles-ci.
Et d’ailleurs le plus gros travail du data scientist ne réside malheureusement pas dans la création de modèle. Le nettoyage du dataset représente une part énorme du processus.
Pour nettoyage des données textuelles on retire les chiffres ou les nombres, on enlève la ponctuation, les caractères spéciaux comme les @, /, -, :, … et on met tous les mots en minuscules.
Pour cela on utiliser ce que l’on appelle les expressions régulières ou regex. Sur Python leur utilisation est assez simple, vous devez importer la bibliothèque ‘re’. Puis construire vos regex. Attention à l’ordre dans lequel vous écrivez les instructions.
Il n’y a malheureusement aucune pipeline NLP qui fonctionne à tous les coups, elles doivent être construites au cas par cas. Dans le cas qui nous importe cette fonction fera l’affaire :
import re
def nlp_pipeline(text):
text = text.lower() # mettre les mots en minuscule
# Retirons les caractères spéciaux :
text = re.sub(r"[,\!\?\%\(\)\/\"]", "", text)
text = re.sub(r"\&\S*\s", "", text)
text = re.sub(r"\-", "", text)
return text
Installation d’un modèle Word2vec pré-entrainé :
Pour gagner du temps et pouvoir créer un système efficace facilement il est préférable d’utiliser des modèles déjà entraînés.
Pour cet exemple j’ai choisi un modèle Word2vec que vous pouvez importer rapidement via la bibliothèque Gensim. Voici le code à écrire sur Google Collab. Rien ne vous empêche de télécharger la base et de travailler en local.
# Import d'une base word2vec en francais deja entrainee
w2v = KeyedVectors.load_word2vec_format(
https://s3.us-east 2.amazonaws.com/embeddings.net/embeddings/frWac_non_lem_no_postag_no_phrase_200_cbow_cut100.bin,
binary=True)
Encodage : la transformation des mots en vecteurs est la base du NLP avec Python
C’est l’étape cruciale du processus. Nous devons transformer nos phrases en vecteurs.
Pour cela, word2vec nous permet de transformer des mots et vecteurs. Je vais ensuite faire simplement la moyenne de chaque phrase. Sachez que pour des phrases longues cette approche ne fonctionnera pas, la moyenne n’est pas assez robuste. Si vous avez des phrases plus longues ou des textes il vaut mieux choisir une approche qui utilise TF-IDF.
# On commence par utiliser notre pipeline définie plus haut
phrases_propres = []
for phrase in phrases:
phrases_propres.append(nlp_pipeline(phrase))
# Nous devons séparer les phrases en liste de mots
phrases_split = []
for phrase in phrases_propres:
phrases_split.append(phrase.split(" "))
# C'est là que Word2vec intervient
X = []
for phrase in phrases_split:
vec_phrase = []
for mot in phrase:
vec_phrase.append(w2v.wv[mot])
X.append(np.mean(vec_phrase,0))
Classification par la méthode des k-means :
Maintenant que nous avons nos vecteurs, nous pouvons commencer la classification.
En classification il n’y a pas de consensus concernant la méthode a utiliser. Vous pouvez lire l’article 3 méthodes de clustering à connaitre.
Ici nous aller utiliser la méthode des k moyennes, ou k-means. Elle est d’autant plus intéressante dans notre situation puisque l’on sait déjà que nos données sont réparties suivant deux catégories.
Le code pour le k-means avec Scikit learn est assez simple :
kclusterer = KMeansClusterer(2, distance=nltk.cluster.util.cosine_distance, repeats=25)
clusters = kclusterer.cluster(X, assign_clusters=True)
print (clusters)
for index, phrase in enumerate(phrases):
print (str(clusters[index]) + ":" + str(phrase))
kmeans = cluster.KMeans(n_clusters=2)
kmeans.fit(X)
labels = kmeans.labels_
centroids = kmeans.cluster_centers_Voici les résultats que l’on obtient :
1 : J'ai acheté des tomates
1 : La saison des oignons arrive
0 : Cette mangue est très bonne
1 : Ca sent les haricots
1 : Je crois que je vais tomber dans les pommes
1 : Penses à acheter des carottes
0 : Un petit jus orange?
0 : Ces fraises sont belles
1 : Prend des aubergines aussiA part pour les pommes chaque phrase est rangée dans la bonne catégorie. Pour les pommes on a peut-être un problème dans la taille de la phrase. Comme je l’ai expliqué plus la taille de la phrase sera grande moins la moyenne sera pertinente.
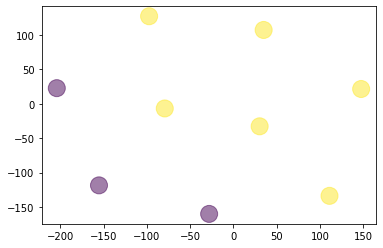
Il peut être intéressant de projeter les vecteurs en dimension 2 et visualiser à quoi nos catégories ressemblent sur un nuage de points.
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
model = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y = model.fit_transform(X)
plt.scatter(Y[:, 0], Y[:, 1], c=clusters, s=290,alpha=.5)
plt.show()Voilà ce que l’on obtient :
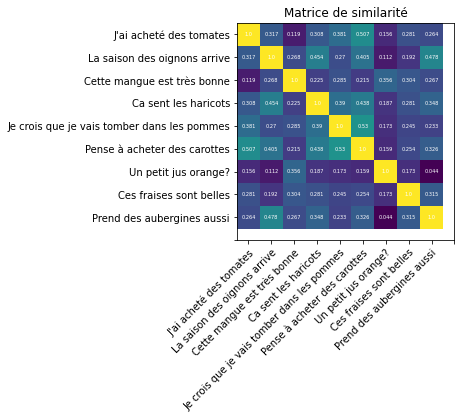
Je suis fan de beaux graphiques sur Python, c’est pour cela que j’aimerais aussi construire une matrice de similarité. Elle nous permettra de voir rapidement quelles sont les phrases les plus similaires.
size = 10
# Construction de la matrice des distances
S = np.zeros((size,size))
for i in range(len(X)):
for j in range(len(X)):
S[i][j] = np.dot(X[i],X[j])/(np.linalg.norm(X[i])*np.linalg.norm(X[j]))
fig, ax = plt.subplots()
img = ax.imshow(S)
# Pour afficher les phrases
x_label_list = phrases
y_label_list = phrases
# Imposons qu'ils soient tous afficher, sinon par défaut vous n'en verrez #que la moitié
ax.set_xticks(np.arange(10))
ax.set_yticks(np.arange(10))
# Afficher les labels et le titre principal
ax.set_xticklabels(x_label_list,rotation='vertical',verticalalignment='top')
ax.set_yticklabels(y_label_list)
ax.set_title("Matrice de similarité")
# Ecrire la valeur de la similarité dans chaque case de la matrice
for i in range(len(x_label_list)):
for j in range(len(y_label_list)):
text = ax.text(j, i, round(S[j,i],3),fontsize=5,
ha="center", va="center", color="w")
# Imposer un angle de rotation pour faciliter la lecture des #labels en abscisses
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
plt.show()Voilà le résultat !
A l’échelle d’un mot ou de phrases courtes la compréhension pour une machine est aujourd’hui assez facile (même si certaines subtilités de langages restent difficiles à saisir). Néanmoins, pour des phrases plus longues ou pour un paragraphe, les choses sont beaucoup moins évidentes. Et on utilise souvent des modèles de réseaux de neurones comme les LSTM.
L’algorithme doit être capable de prendre en compte les liens entre les différents mots. Il se trouve que le passage de la sémantique des mots obtenue grâce aux modèles comme Word2vec, à une compréhension syntaxique est difficile à surmonter pour un algorithme simple. Les chatbots qui nous entourent sont très souvent rien d’autre qu’une succession d’instructions empilées de façon astucieuse.
Néanmoins, le fait que le NLP soit l’un des domaines de recherches les plus actifs en machine learning, laisse penser que les modèles ne cesseront de s’améliorer. Peut-être que nous aurons un jour un chatbot capable de comprendre réellement le langage.



Bonjour,
Je voulais tester l’exemple et je suis bloquée sur la base word2vec en français, avez-vous un autre lien pour le remplacer et tester votre exemple d’analyse de sentiment ?
« http://embeddings.net/frWac_non_lem_no_postag_no_phrase_200_cbow_cut100.bin »
Je vous remercie
Bonnejournée
Bonjour,
J’ai eu le même problème que vous. Si vous n’avez toujours pas trouvé de lien équivalent, utilisez celui-ci qui fonctionne de mon côté :
https://s3.us-east-2.amazonaws.com/embeddings.net/embeddings/frWac_non_lem_no_postag_no_phrase_200_cbow_cut100.bin
Bien cordialement,
Axel RACAMIER
Bonjour,
Merci beaucoup pour votre aide Axel, je modifie l’article 🙂
Ilyes
Bonjour,
Lorsque j’exécute l’instruction : vec_phrase.append(model_w2v.wv[mot])
J’obtiens l’erreur : AttributeError: ‘KeyedVectors’ object has no attribute ‘wv’
Quelqu’un aurait une idée de comment remédier à cela ?
Merci d’avance !
Ne penses tu pas que le modèle a classifié les phrases en fonction de ce qu’elles décrivent et non en fonction du fruit ou du légume. Pour les phrases dans le cluster 0 on voit que ce sont des phrases descriptives avec des adjectifs qualitatifs comme ‘petit’ ‘belle’ ou ‘bonne’. Tandis que les autres phrases sont plus actifs avec des verbes comme ‘prends’ ‘achetes’