
Dans le précédent tutoriel NLP nous avons introduit la notion d’encodage de texte, expliqué ce qu’était un pipeline NLP pour le nettoyage de notre dataset et avons construits un outil pour classifier des phrases non labélisées. D’ailleurs je vous conseille vivement de commencer par le lire avant d’aborder celui-là, beaucoup de notions sont complémentaires. Dans cette article il est question d’analyse de sentiments.

Avant de commencer, sachez que tous les codes et les données utilisées ici sont disponibles sur ma page GitHub.
Le NLP est la discipline du machine learning liée à la compréhension du langage par les machines. Les dernières avancées dans ce domaine ont permis l’émergence d’applications intéressantes (effrayantes aussi).
L’analyse de sentiments des textes en est une. Le principe est simple, en étudiant des millions de textes labellisés avec un certain sentiment, le système est capable d’associer un champ lexical précis pour chaque sentiment. En lui donnant un nouveau texte, il sera alors capable de prédire avec une bonne précision, l’état émotionnel de l’auteur au moment de l’écriture de ce texte.
Certaines organisations utilisent l’analyse de sentiments afin de pouvoir suivre en temps réel la satisfaction de leurs utilisateurs. Si un client vous envoi un mail et que votre système détecte que la personne est énervée, vous savez que vous risquez de perdre un client. Vous avez intérêt à offrir quelque chose !
L’analyse de sentiments des tweets est une des applications classiques du NLP, c’est le ‘Hello World‘ du NLP. Dans cet article, qui sera un peu plus ambitieux que le précédent, l’idée sera de pouvoir faire de l’analyse de sentiments d’un tweets à partir des mots utilisés en utilisant TextBlob. Ce qui constituera une métrique de l’angoisse globale liée au Covid-19 qui règne sur Twitter, en fonction de ce qui y est publié.
Avant d’avoir les résultats on s’attend à voir une courbe qui commence à croitre début février et qui ne décroit qu’aux alentours de fin avril.
Comme je vous l’ai expliqué dans le précédent tutoriel, en data science on traite essentiellement des vecteurs et des données numériques. Les machines ne savent pas ce qu’est un mot ou une phrase, d’où la nécessité d’encoder nos données. Pour des phrases standard l’encodage est assez facile en utilisant Word2vec ou BERT. Pour l’encodage de tweets c’est plus délicat.
La structure d’un tweet est moins organisée. Certains utilisent des emojis, l’utilisation de ponctuations est beaucoup plus présente, les fautes d’orthographes sont très courantes. Tout ceci complique le travail de nettoyage préalable, surtout lorsqu’il est question d’analyse de sentiments.
Pour contourner cela plutôt que d’encoder nous même les tweets, nous allons passer par TextBlob. Ce module a une option qui permet de mesurer le sentiment d’un texte donné. En sortie la fonction nous donne un coefficient de polarité et un coefficient de sensibilité.
C’est la polarité qui nous intéresse ici. C’est un coefficient compris entre -1 et 1. Plus la polarité est proche de -1 plus le tweet est négatif, à l’inverse une polarité proche de 1 signifie que le tweet est plutôt positif.
Extraction de tweets
Pour faire du machine learning sur des tweets il faut des tweets 😊 Pour cela deux options se présentent. La première est d’utiliser l’API que Twitter lui-même propose. Elle permet de récupérer des tweets en ajoutant certaines conditions sur le type de tweets que vous souhaitez.
La seconde option est l’utilisation du module Python Twitterscrapper. Vous pouvez extraire un grand nombre de tweets en spécifiant des critères de date, de langues et en vous limitant aux tweets qui contiennent certains mots-clés. Cette option est plus simple à utiliser mais ne fonctionne pas toujours, si ça marche pour vous tant mieux !
J’ai choisi de récupérer les tweets entre le 1er Janvier et le 1er Juin, qui contiennent les termes ‘Covid-19’, ‘Covid’, ‘Coronavirus’, ‘Pandémie’, ’épidémie’, ’corona’ ou ‘virus’. Les tweets doivent être en français. Pour cela le code est très simple.
Vous devez d’abord installer le module twitterscraper. Si vous codez sur Google Colab, Kaggle ou sur un notebook Jupyter n’oubliez pas le ‘!’ :
!pip install twitterscraperOn importe ensuite les modules que nous allons utiliser :
from twitterscraper import query_tweets
import datetime as dt
import pandas as pdLe module datetime va permettre de gérer les dates et les horaires de publications des tweets. Pandas (que nous avons déjà utilisé dans de précédents tutoriels) est le module Python le plus adapté pour la gestion de grandes base de données.
debut = dt.date(2020,1,1)
fin = dt.date(2020,6,1)
mots="Covid-19 OR Covid OR Corona OR Pandémie OR épidémie OR Coronavirus OR virus"
tweets = query_tweets(query=mots, begindate = debut,
enddate = fin, lang = "fr")
tweets = pd.DataFrame(t.__dict__ for t in tweets)
tweets.to_csv('tweet_covid.csv')On fixe la date de début pour l’extraction de tweets avec dt.date(2020,1,1) le format est YYYY/MM/DD. De même la ligne dt.date(2020,6,1) permet de fixer la date de fin d’extraction au 1er Juin.
On sélectionne les mots-clés qui doivent apparaître dans les tweets puis on commence l’extraction avec query_tweets. N’oubliez pas de préciser que l’on veut seulement les tweets en français.
La commande DataFrame permet d’organiser toutes nos données sur les tweets dans un tableau pandas. On exporte ensuite le dataframe au format csv. Si vous le souhaitez il est possible de l’enregistrer autre part que dans votre environnement de travail, vous n’avez qu’à spécifier le chemin.
L’extraction peut prendre du temps tout dépend de votre connexion internet. Pour vous faciliter la tache j’ai mis en ligne un fichier csv avec tous les tweets qui ont été extraits. Il y en a 13000 en tout. Il devrait y’en avoir beaucoup plus, mais il semblerait que Twitter limite l’extraction pour certains mots-clés. Néanmoins pour notre étude nous pouvons nous contenter de cette base.
Pour des raisons que j’ignore l’extraction avec Twitterscrapper a cessé de fonctionner pour moi. J’ai donc été contraint d’utiliser l’API. Elle est un peu moins évidente à comprendre, mais le code est plutôt simple. La grosse différence c’est qu’avec Tweepy vous avez besoin d’un accès à un compte Twitter.
Si vous voulez seulement utiliser les tweets déjà disponible vous n’avez qu’à télécharger le fichier CSV et sauter cette partie. Sinon, voici comment récupérer des tweets avec Tweepy. Cette méthode est laborieuse est beaucoup moins pratique que la précédente, mais je n’ai pas d’autres alternatives :
- D’abord vous aurez besoin d’un compte Twitter développeur. La demande est un peu laborieuse et lente (ça fait plus d’une semaine que j’attends mes accès 🙂 ). Pour cela rendez-vous sur cette page, renseignez les informations demandées et attendez que Twitter confirme votre demande.
- Une fois votre compte développeur crée, il vous faudra quelques informations : l’API key, l’API secret key, l’Access token, l’Access token secret. Ils sont faciles à trouver depuis votre compte.
- Enfin, voici le code qui permet d’extraire les tweets :
!pip install tweepy
import os
import tweepy as tw
consumer_key = "CF COMPTE TWITTER"
consumer_secret = "CF COMPTE TWITTER"
access_key = "CF COMPTE TWITTER"
access_secret = "CF COMPTE TWITTER"
# Authentification :
auth = tw.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tw.API(auth, wait_on_rate_limit=True)
requete = "Covid-19 OR Covid OR Corona OR Pandémie OR épidémie OR Coronavirus OR virus"
tweets = tw.Cursor(api.search,
q = requete,
lang = "fr",
since='2018-01-15').items(1000)
all_tweets = [tweet.text for tweet in tweets]Pour information une des caractéristiques de Twitter que je ne comprends pas bien, est que les commentaires sont aussi considérés comme des tweets. Donc notre base comportera les tweets et leurs réponses.
Maintenant que nous avons notre base de tweets, nous pouvons commencer l’analyse à proprement parler.
Update !
Entre temps j’ai trouvé sur Medium une méthode encore plus facile !
Le module Twint permet de se passer de l’API de Twitter, le code est très simple. La plupart des exemples que vous trouverez sur internet sont écrits en lignes de commandes. Pour rendre l’extraction plus simple, je vous ai écrit le code Python.
Vous devez d’abord installer Twint :
!pip install twintEncore une fois, n’oubliez pas ‘!’ si vous êtes sur Google Colab ou sur un Notebook Jupyter.
Ensuite vous pouvez commencer l’extraction des tweets :
import twint
tw = twint.Config()
tw.Search = "Covid-19 OR Corona OR Covid OR Virus OR pandémie OR épidémie OR Coronavirus"
tw.Since = "2020-02-01 12:00:00"
tw.Custom["tweet"] = ["id"]
tw.Pandas = True
tw.Lang = "fr"
twint.run.Search(tw)
tweet = twint.storage.panda.Tweets_dfOn commence par importer twint. La syntaxe utilisée par ce module est un peu différente mais reste très simple à comprendre.
Dans search on définit la requête que l’on recherche, à savoir les mots clés qui nous intéressent.
Since permet de définir une date de début d’extraction. J’ai choisi le 1er Février à midi, rien ne vous empêche de commencer encore plus tôt.
On spécifie le français comme langue. Nous aurions aussi pu considérer tous les tweets et les traduire.
Enfin on définit un nom pour l’enregistrement de notre dataframe pandas.
En pratique, Twint est très lent pour extraire les tweets. J’ai donc fixé à 1000 le nombres maximale de tweets à extraire et j’ai fait l’extraction sur 13 périodes de 10 jours de Février à Juin 2020.
On se retrouve avec un fichier constitué de 13 000 tweets en tout. Vous pouvez le télécharger ici.
Si vous utilisez twint sur Jupyter ou Colab vous pourriez avoir cette erreur au moment de l’exécution : ‘this event loopis already runing‘.
Pour résoudre ce problème, vous n’avez qu’à installer ce module :
pip install nest_asyncioPuis exécuter ce code :
import nest_asyncio
nest_asyncio.apply()Nettoyage et construction du pipeline NLP
Une rapide inspection de la base nous permet de voir que la compréhension de certains tweets est difficile même pour des êtres-humains haha. Le nettoyage sera d’autant plus important.
Je ne vous le répéterai jamais assez, la préparation de votre dataset est l’aspect le plus important du processus, toute la construction du modèle en dépend. Une préparation faite de manière hâtive peut conduire à des résultats faux et biaisés, ce qui n’est pas souhaitable. Surtout dans le cadre d’un business ou pour le traitement de problématiques de société importantes, sans parler des catastrophes que cela peut engendrer dans des domaines comme le juridique ou la santé…
En NLP, on commence toujours par construire un pipeline de nettoyage des données. Personnellement j’utilise les Reg-ex avec le module Python re qui permettent de faire cela facilement.
Le nettoyage des tweets comprendra plusieurs choses :
- Enlever les emojis : pour cela il faut un module Python spécial (si vous connaissez des approches plus simples mettez-les en commentaire ça m’intéresse)
- Retirer la ponctuation : très facile avec les reg-ex
- Retirer les caractères spéciaux : très facile avec les reg-ex mais tous les caractères ne seront pas retirés dans un premier temps. Les tweets sont des objets très sales !
- Retirer les chiffres : avec une Reg-ex aussi
- Changer les lettres majuscules en minuscules
Comme d’habitude pour ne pas se tromper il vaut mieux aller du plus restrictif au moins restrictif.
Voilà à quoi ressemble notre pipeline :
import re
def nlp_pipeline(text):
text = text.lower()
text = text.replace('\n', ' ').replace('\r', '')
text = ' '.join(text.split())
text = re.sub(r"[A-Za-z\.]*[0-9]+[A-Za-z%°\.]*", "", text)
text = re.sub(r"(\s\-\s|-$)", "", text)
text = re.sub(r"[,\!\?\%\(\)\/\"]", "", text)
text = re.sub(r"\&\S*\s", "", text)
text = re.sub(r"\&", "", text)
text = re.sub(r"\+", "", text)
text = re.sub(r"\#", "", text)
text = re.sub(r"\$", "", text)
text = re.sub(r"\£", "", text)
text = re.sub(r"\%", "", text)
text = re.sub(r"\:", "", text)
text = re.sub(r"\@", "", text)
text = re.sub(r"\-", "", text)
return textCe pipeline nous permet d’avoir des tweets à peu prés propres. Cela permet a TextBlob d’analyser le sentiment du tweet plus efficacement.
Le module NLP TextBlob pour l’analyse de sentiments
TextBlob est un module NLP sur Python utilisé pour l’analyse de sentiment. La fonction de TextBlob qui nous intéresse permet pour un texte donné de déterminer le ton du texte et le sentiment de la personne qui l’a écrit.
Pour chaque tweet nous aurons une métrique qui donne la polarité de ce tweet. Nous allons regrouper les tweets par jours et faire une moyenne de la polarité sur chaque jour. Nous tracerons ensuite la courbe d’évolution de la polarité ambiante.
D’abord ouvrons le fichier csv que nous avons enregistrer plus haut. Si vous avez utilisé twitterscraper ou twint vous n’avez pas à le faire vos tweets sont déjà stockés dans la variable df.
tweet = pd.read_csv("tweet_covid.csv")
corpus = df['tweet']
corpus_clean = corpus.apply(nlp_pipeline)L’instruction corpus.apply(nlp_pipeline) permet d’appliquer les règles de nettoyage à chaque tweet du corpus.
Il faut maintenant installer le module TextBlob :
!pip install textblob
!pip install textblob-frVous devez installer les deux modules car textblob dans sa version de base n’est pas disponible pour la langue française. Si vous travaillez avec un corpus en anglais ce ne sera pas nécessaire.
On peut maintenant calculer facilement la polarité d’un tweet. Avant de le faire sur nos données, voici deux exemples :

from textblob import TextBlob
from textblob_fr import PatternTagger, PatternAnalyzer
polarity = []
for tweet in corpus_clean:
polarity.append(TextBlob(tweet,pos_tagger=PatternTagger(),analyzer=PatternAnalyzer()).sentiment[0])Visualisation des résultats
La partie que je préfère dans tous les projets data science c’est la visualisation des résultats. Il est bon de pouvoir construire des modèles complexes, mais ils ne servent à rien si on ne peut pas les résumé de manière simple et élégante.
Maintenant que nous avons une liste avec toutes les polarités des tweets du corpus, nous pouvons tracer une première courbe pour voir à quoi l’évolution ressemble.
Pour cela on utilise matplotlib.pyplot, c’est la librairie de référence pour le tracé de courbes sur Python :
import matplotlib.pyplot as plt
plt.plot(polarity)
Avec cette commande, on obtient le tracé de l’évolution de la polarité des tweets. Comme on a 13000 tweets, cette méthode ne permet pas de voir grand chose :
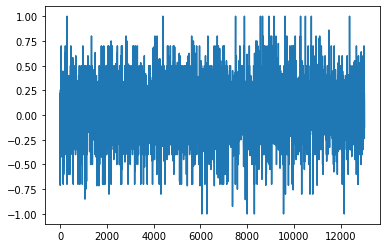
Comme vous le voyez on ne peut rien tirer de ce graphe, on a plusieurs milliers de valeurs. Il faudra être moins bourrin.
La première chose que l’on peut faire est de regrouper les tweets en paquets suivant l’ordre chronologique. On conservera ensuite pour chaque groupe uniquement sa moyenne. Je décide de les regrouper par paquet de 100 tweets.
group = lambda liste, size : [liste[i:i+size] for i in range(0, len(liste), size)]
polarity_par_paquet = group(polarity,100)
liste_moyennes = []
for l in polarity_par_paquet :
liste_moyennes.append(np.mean(l))
plt.plot(liste_moyennes)On obtient la courbe suivante :
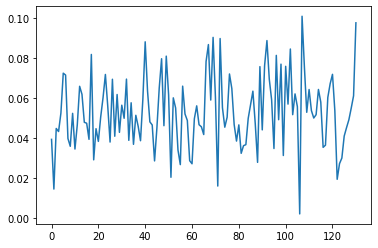
Une fois de plus les résultats ne sont pas ceux attendus. Je suis un peu déçu. Je m’attendais à voir une tendance d’évolution se dégageait sur nos résultats. Il peut y avoir plusieurs raisons à cela.
D’abord, tout au long de l’épidémie, les gens étaient assez partagés sur le danger du virus. De plus, les réactions des gens face au danger ne sont pas toutes identiques. Certains préfèrent plutôt prendre les choses à la rigolade. Ces réactions contribuent à augmenter la polarité.
Des problèmes dans le modèle peuvent aussi exister. Textblob est un module très généraliste entraîné sur des tweets couvrants de nombreux sujets, il est difficilement applicable à un sujet précis.
Ces résultats peuvent être considérablement améliorés. Il suffit pour cela de construire une base de données labellisée propre à notre contexte. Si voulez savoir comment faire contactez-moi. Le travail de labellisation est assez long mais permet d’avoir de bien meilleurs performances.
Comme souvent dans les problèmes de NLP le plus difficile est de constituer une base de données propres et utilisables. C’est la plus grande partie du travail d’un ingénieur NLP. Pour cela les reg-ex sont de très bons outils qu’il est important de maîtriser (des alternatives intéressantes existent évidemment).
Même si nous n’avons pas obtenu les résultats espérés, ce tutoriel permet d’avoir une méthodologie claire pour la réalisation de ce type de projet. Le schéma sera souvent similaire :
1. Constitution de la base
2. Nettoyage
3. Conception du modèle
4. Interprétation des résultats
La communauté Python est très active concernant les problématiques de NLP. C’est pour cela qu’avec des connaissances simples vous pouvez faire de très belles choses. A l’image de TextBlob, qui nous a été utile dans ce tutoriel (nous auront l’occasion de l’utiliser encore), de nombreux packages Python vous permette de réaliser vos projets : NLTK, Gensim, SpaCy et d’autres.
Malgré tous ces outils dont on dispose et malgré tous les efforts de milliers de chercheurs, les défis liés au NLP sont encore difficile à résoudre. La construction de sémantiques fiables et flexibles n’est pas encore parfaitement maîtrisée. Et nous sommes encore très loin d’une vraie compréhension du langage par les IA, c’est d’ailleurs pour cela que ‘Personne n’aime parler à une IA’.



Bonjour, j’ai fais pareil que vous mais le fichier csv qu’il ma généré est vide!!!!!
Hello!
C’est avec quelle méthode que le fichier généré est vide ? La méthode qui devrait toujours fonctionner est celle avec twint, les autres sont assez limitées, surtout twitterscrapper. Sinon si c’est plutôt la partie analyse des tweets qui vous intéresse, vous pouvez télécharger directement la base 🙂
merci pour le cour !
Merci. Heureux que l’article vous plaise !
Bonjour, svp dites moi pourquoi quand j’essaye le code tweepy avec google colab, il arrive a me télecharger le csv mais vide, et j’ai essayé l’autre avec twitter developper j’ai rien eu; le 2 eme je l’ai essayé avec jupyter. Merci, si vous pouvez me donner une solution svp j’ai besoin en urgences mais pour une autre thématique
Bonjour,
Avec Tweepy il vous faut une clé API donnée par Twitter. Il faut donc un compte Twitter développeur, il faut plusieurs jours aux agents Twitter pour valider votre compte donc ce n’est pas la solution la plus rapide.
Twint devrait fonctionner. Vous avez un message d’erreur ou un avertissement ?
ça fonctionne malgré l’erreur qu’il m’affiche, merci bcp pour cet ariticle
Ok je comprends. Il te mets ‘this event loop is already runing’.
Sur un Notebook Jupyter ou sur Colab cette erreur est fréquente. Pour régler le problème il y a une solution très simple. Il faut installer le module nest_asynco. Voici un fichier Colab ou je l’ai écris : https://cutt.ly/QfR4q0Z
Je corrige l’article, merci de m’avoir rapporter cette erreur ! J’espère que ça résout ton problème 🙂
Bonjours , pouvez vous me filer la partie restante du tuto: la construction de la base de données et le reste du tuto. Merci pour ces tutoriels si interessants
Bonjour, pour ma part j’ai essayé avec twint ça a fonctionné ; mais j’arrive toujours pas avec le code du nettoyage, je ne sais pas c’est quoi le souci.
Bonsoir. Est-ce qu’un message d’erreur s’affiche ? Si tu peux me transmettre ton code, je regarde ça demain et je te tiens au courant 🙂
Merci
Je vous en prie 🙂
« Ces résultats peuvent être considérablement améliorés. Il suffit pour cela de construire une base de données labellisée propre à notre contexte. Si voulez savoir comment faire contactez-moi. Le travail de labellisation est assez long mais permet d’avoir de bien meilleurs performances. »
Bonjour j’aimerai bien savoir comment faire la base données labellisée pour mieux construire mon modèle. J’ai appliqué votre méthode ci dessus et j’ai obtenue une courbe évolutive mais le seul truc ce que mes tweets sont pas dans l’odre chronologique
Bonjour.
Alors la labellisation doit se faire à la main. Ca sera à toi de fixer les labels (par ex : humour, peur, etc). L’idée ensuite sera d’entrainer un réseau de neurones (de type LSTM pour le traitement du langage) qui à partir d’un texte qu’il a jamais vu, pourra prédire le sentiment. Le travail le plus dur sera le nettoyage des données. Tu peux reprendre la pipeline que j’ai utilisé dans cet article mais ensuite tu devras encoder les tweets. On peut en parler au besoin.
Bonjour, j’ai fais pareil que vous avec la librairie Twint mais le fichier csv qu’il ma généré est vide!!!!! avec un message d’avertissement (CRITICAL:root:twint.run:Twint:Feed:noDataExpecting value: line 1 column 1 (char 0)sleeping for 1.0 secs).
Merci, si vous pouvez me donner une solution svp
Bonjour. Effectivement c’est un problème qui est apparu récemment… Essaye cette solution https://github.com/twintproject/twint/pull/917
C’est pas le seul scrapper qui a ce problème. Je vais m’y intéresser de près. Merci pour cette info !
Bonjour, je ne pense pas avoir une réponse étant donné que la revue date de 2020 mais sait-on jamais.
dans la ligne « corpus = df[« tweet »] il y a une erreur indiquant que « df » n’est pas définit, c’est peut-être quelque chose de basique mais je ne vois pas comment régler le problème. Pourriez-vous y apporter une solution ? Merci si vous prenez le temps de me répondre !
Bonjour Mateo, je compte rester disponible plusieurs années encore haha 🙂
Est-ce que vous pouvez me montrer votre code ? L’erreur « df is not defined » veut dire que le chargement du dataset ne s’est pas déroulé comme prévu. Est-ce que vous avez bien fait df = pd.read_csv(…) ?
Bonjour, merci de votre réponse, j’avais effectivement oublié cette ligne. Maintenant un nouveau problème apparait sur la même ligne, « corpus = df[« tweet »] », l’erreur KeyError : ‘tweet’ apparait. Si vous avez une solution je suis preneur haha.
Désolé de vous prendre de votre temps.
Hello! Cette erreur signifie que la colonne ‘tweet’ n’existe pas dans ton tableau. C’est étrange, il devrait la trouver. Essaye de faire df.head(), ça va te permettre de voir la forme de ton dataframe avec les noms de colonnes pour vérifier.
Hello ! (désolé si j’envois le message en double mais le premier que j’ai écris n’apparaît pas) J’ai vérifié et la colonne « tweet » semble bel et bien exister. Je me permets de contextualiser le pourquoi je suis votre article. Je suis en Terminal et j’ai une de mes spécialités qui est de l’informatique (NSI), et je dois faire un projet de fin d’année, projet de fin d’année que je dois rendre la lundi qui arrive.
Je vous colle mon code ici, si vous pouvez y jeter un oeil et me dire ce qui ne vas pas je vous en serez très reconnaissant ! Désolé encore une fois de vous prendre votre temps haha.
!pip install twitterscraper
!pip install textblob
!pip install textblob-fr
!pip install twint
!pip install nest_asyncio
from twitterscraper import query_tweets
import datetime as dt
import pandas as pd
import re
import nest_asyncio
nest_asyncio.apply()
import twint
from textblob import TextBlob
from textblob_fr import PatternTagger, PatternAnalyzer
import matplotlib.pyplot as plt
debut = dt.date(2020,1,1)
fin = dt.date(2020,6,1)
mots= »Covid-19 OR Covid OR Corona OR Pandémie OR épidémie OR Coronavirus OR virus »
tweets = query_tweets(query=mots, begindate = debut, enddate = fin, lang = « fr »)
tweets = pd.DataFrame(t.__dict__ for t in tweets)
tweets.to_csv(‘tweet_covid.csv’)
tw = twint.Config()
tw.Search = « Covid-19 OR Corona OR Covid OR Virus OR pandémie OR épidémie OR Coronavirus »
tw.Since = « 2020-02-01 12:00:00 »
tw.Custom[« tweet »] = [« id »]
tw.Pandas = True
tw.Lang = « fr »
« » »twint.run.Search(tw) » » »
tweet = twint.storage.panda.Tweets_df
def nlp_pipeline(text):
text = text.lower()
text = text.replace(‘\n’, ‘ ‘).replace(‘\r’, »)
text = ‘ ‘.join(text.split())
text = re.sub(r »[A-Za-z\.]*[0-9]+[A-Za-z%°\.]* », « », text)
text = re.sub(r »(\s\-\s|-$) », « », text)
text = re.sub(r »[,\!\?\%\(\)\/\ »] », « », text)
text = re.sub(r »\&\S*\s », « », text)
text = re.sub(r »\& », « », text)
text = re.sub(r »\+ », « », text)
text = re.sub(r »\# », « », text)
text = re.sub(r »\$ », « », text)
text = re.sub(r »\£ », « », text)
text = re.sub(r »\% », « », text)
text = re.sub(r »\: », « », text)
text = re.sub(r »\@ », « », text)
text = re.sub(r »\-« , « », text)
return text
« » »twint.run.Search(tw) » » »
tweet = twint.storage.panda.Tweets_df
tweet = pd.read_csv(« tweet_covid.csv »)
df = pd.read_csv(« tweet_covid.csv »)
corpus = df[« tweet »]
corpus_clean = corpus.apply(nlp_pipeline)
polarity = []
for tweet in corpus_clean:
polarity.append(TextBlob(tweet,pos_tagger=PatternTagger(),analyzer=PatternAnalyzer()).sentiment[0])
plt.plot(polarity)
Merci pour le cours
Heureux que ça vous plaise! 🙂
Bonjour, le module snscrape permet de scraper facilement et est compatible avec plusieurs réseaux (Facebook, Instagram, Reddit, Twitter…). Je vous le recommande.
https://github.com/JustAnotherArchivist/snscrape