
Les algorithmes de machine learning se classent généralement en deux grandes catégories : l’apprentissage non-supervisé et l’apprentissage supervisé. Aujourd’hui, nous nous focalisons sur une légende de la seconde catégorie : les Machines à Vecteurs de Support, ou SVM (Support Vector Machines).
Développés initialement dans les années 60, puis perfectionnés dans les années 90 par Vladimir Vapnik et ses collègues, les SVM sont restés l’état de l’art en classification avant l’avènement du Deep Learning. En français, on parle de « séparateurs à vastes marges », un terme qui trahit déjà leur fonctionnement.
Que vous soyez débutant ou que vous ayez besoin d’un rafraîchissement, voici tout ce qu’il faut savoir, de la théorie à la pratique avec Scikit-learn.
L’idée fondamentale derrière les SVM : le concept de frontière
Concrètement, qu’est-ce qu’un SVM ? Imaginez que vous avez des billes rouges et des billes bleues posées sur une table. Votre objectif est de séparer ces billes avec une baguette (une ligne droite) de manière à ce que les rouges soient d’un côté et les bleues de l’autre.
Les SVM sont des classificateurs qui cherchent, dans un espace de dimension N, l’hyperplan (la frontière) qui divise au mieux un jeu de données en deux classes.
Mais qu’entend-on par « au mieux » ? C’est là que réside le génie du SVM.
La notion de marge maximale
Il existe une infinité de lignes possibles pour séparer nos billes. Cependant, certaines sont meilleures que d’autres. Une ligne qui rase une bille rouge de très près est risquée : si la bille bouge un peu, elle change de camp (erreur de généralisation).
Le SVM cherche la frontière qui passe le plus loin possible des points de chaque classe pour minimiser le risque d’erreur future. C’est le principe de la marge maximale.
- La frontière : La ligne de décision au centre.
- La marge : La zone vide (le « no man’s land ») de chaque côté de la frontière.
- L’objectif : Avoir la route la plus large possible entre les deux classes.
Les vecteurs de support dans le SVM
Pourquoi l’algorithme s’appelle-t-il « Support Vectors Machines » ? Parce que la position de la frontière ne dépend que de quelques points spécifiques : ceux qui sont les plus proches de la frontière.
Ces points sont les piliers de la construction, les « poteaux » qui soutiennent la marge. On les appelle les Vecteurs de Support.
Tous les autres points, ceux qui sont loin derrière, n’ont aucune influence sur le modèle. Vous pouvez les bouger ou les supprimer, la frontière ne changera pas. C’est ce qui rend les SVM efficaces en mémoire.

Nous avons ci-dessus un exemple d’hyperplan séparateur pour N=2. H1 ne sépare pas correctement le jeu de donnée, H2 le sépare bien mais pas de façon optimale, H3 sépare le jeu de donnée avec la marge maximale. C’est H3 qui doit être trouvé grâce à la méthode SVM.
Dans l’exemple des billes sur la table, une ligne droite suffisait. On dit que le problème est linéairement séparable. Mais dans la vraie vie, les données sont souvent mélangées de façon complexe.
Imaginez que les billes bleues sont au centre de la table et les rouges tout autour, en cercle. Impossible de les séparer avec une baguette droite !
Comment les SVM interviennent dans les problèmes non linéaires ?

Dans le cas de la figure ci-dessus, la tâche est relativement facile puisque le problème est linéairement séparable, c’est-à-dire que l’on peut trouver une droite linéaire séparant les données en deux.
Ces problèmes là étant très simples et peu rencontrés en pratique, l’intérêt s’en trouve limité. Dans la majorité des cas, les données sont « mélangés » et le problème non linéairement séparable.
Il n’est alors pas possible de les séparer seulement avec une droite. Mais on avait dit que les Support vector machines sont des séparateurs linéaire, ils ne fonctionnent donc que dans les cas simples ? Un peu de patience, nous y venons…

La quasi totalité des cas que nous rencontrons en pratique sont non-linéairement séparable. Et c’est la qu’entre en jeu l’astuce du noyau.
C’est l’idée la plus puissante des SVM : si on ne peut pas séparer les données en 2D, projetons-les dans une dimension supérieure !
Cette manœuvre permet de passer d’un problème non linéairement séparable à un problème linéairement séparable. La fonction noyau joue un rôle primordiale. En effet, en passant d’un espace de dimension inférieur à un espace de dimension supérieur, les calculs deviennent également plus complexes et plus coûteux.

La fonction noyau permet alors d’effectuer les calculs dans l’espace d’origine en lieu et place de l’espace de dimension supérieur. Le gain en coût et en facilité est colossal. Cette méthode est appelé kernel trick (astuce du noyau en français).
La méthode ne porte pas ce nom par hasard. Nous avons besoin de très peu d’informations concernant l’espace de dimension supérieur pour arriver à nos fins.
Les différentes fonctions de noyaux utilisées
Les SVM reposent sur différents noyaux, chacun adapté à une forme particulière de séparation des données.
Le noyau linéaire est le plus simple : il trace un hyperplan plat sans transformer l’espace, ce qui en fait un excellent choix lorsque l’on dispose d’un très grand nombre de caractéristiques, comme en classification de texte, ou lorsque les données semblent déjà linéairement séparables. Il est aussi le plus rapide à entraîner.
Le noyau polynomial, lui, examine non seulement les variables mais aussi leurs combinaisons et puissances, ce qui permet d’obtenir des frontières courbes plus flexibles.
Il peut être utile dans des contextes où des relations non linéaires évidentes existent, par exemple en traitement d’image, mais il devient vite coûteux et peut sur-apprendre si le degré du polynôme est trop élevé.
Le noyau RBF (Radial Basis Function) est généralement considéré comme le plus polyvalent : il place une « cloche » gaussienne autour de chaque point de données, ce qui revient à projeter les observations dans un espace de dimension infinie. C’est le choix par défaut lorsqu’on ne sait pas quel noyau privilégier, car il excelle pour modéliser des structures complexes où les données se regroupent en îlots plutôt qu’en lignes.
Enfin, le noyau sigmoïde utilise une fonction en forme de S, proche de celle employée dans les perceptrons multicouches. Bien qu’il soit historiquement intéressant pour son lien avec les réseaux de neurones, il est aujourd’hui beaucoup moins utilisé, le noyau RBF offrant généralement de meilleures performances dans la plupart des cas pratiques.

Comment les SVM gère les cas ou on a plus de 2 classes ?
Tous les problèmes que nous avons vu plus haut considéraient seulement deux ensembles distincts à séparer. C’est normal : les Support Vector Machines ont initialement été construit pour séparer seulement deux catégories.
En reprenant la définition des SVM, on se trouve face à une limitation : un hyperplan qui sépare l’espace en trois ou plus ça n’existe pas.
Fort heureusement, des chercheurs se sont penchés sur la question et on trouver des solutions. Je vais vous présenter l’une d’entre elles : one vs all.
Cette approche consister à créer autant de SVM que de catégories présentes. Prenons un exemple. Supposons que nous avons des pions rouges, des pions bleues et des pions verts. On souhaite séparer les pions en fonction de leurs couleurs.
Avec l’approche one vs all, on utilise un SVM pour trouver une frontière entre les groupes {pions rouges} et {pions bleues, pions verts}; puis un autre SVM pour trouver une frontière entre {pions bleus} et {pions rouges, pions verts}; et enfin une troisième SVM pour une frontière entre {pions verts} et {pions bleus, pions rouges}. On extrait alors une frontière (non linéaire) de ces trois frontières.

Les hyperparamètres : C et Gamma
Pour maîtriser les SVM, il faut comprendre deux manettes de réglage essentielles. Si vous ne les réglez pas, votre modèle sera probablement sous-optimal.
Comment régler le paramètre C pour un SVM ?
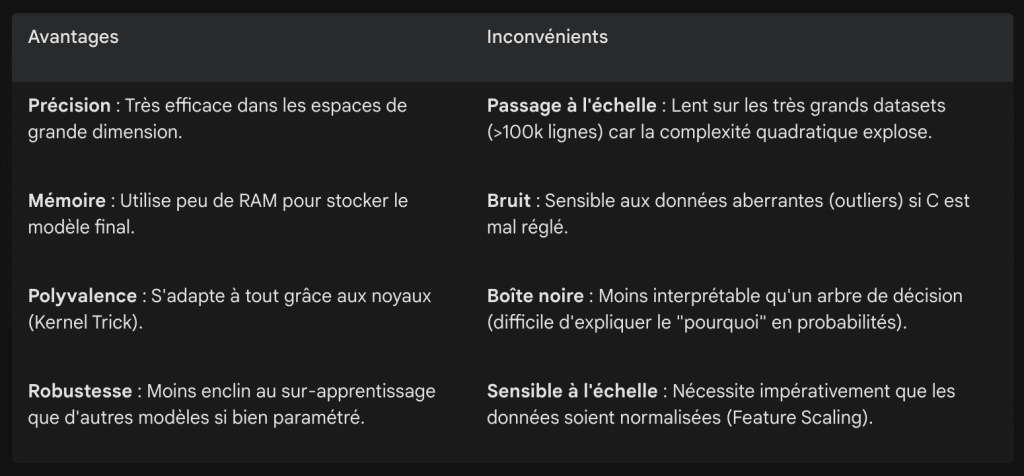
Le paramètre C joue un rôle crucial dans l’équilibre entre la largeur de la marge et la précision du classement des points d’entraînement.
Lorsqu’il est faible, le modèle adopte un comportement plus tolérant : il accepte de mal classer quelques observations afin de conserver une marge large.
Cette approche, souvent appelée soft margin, rend le SVM plus robuste et limite le risque de sur-apprentissage.
À l’inverse, lorsqu’on augmente fortement C, le modèle devient beaucoup plus strict et cherche à classer correctement chaque point, y compris les valeurs aberrantes.
Cela conduit généralement à une marge plus étroite et expose davantage au risque d’overfitting.
Comment régler le paramètre Gamma pour un SVM ?
Le paramètre gamma, propre aux noyaux non linéaires comme le RBF, contrôle la portée de l’influence de chaque point d’entraînement. Lorsqu’il est faible, cette influence s’étend loin autour du point, produisant une frontière de décision plus douce et couvrant de larges zones.
À l’inverse, un gamma élevé crée une influence très locale : la frontière se déforme fortement pour épouser uniquement les points proches. Pousser gamma trop haut conduit presque inévitablement à un sur-apprentissage, car le modèle se met à suivre les moindres irrégularités du dataset.
Quelles sont les applications des SVM ?
Bien que le deep learning domine désormais pour les tâches très complexes, les SVM restent des outils incontournables et performants dans de nombreux domaines critiques.
Ils excellent particulièrement pour l’OCR (reconnaissance optique de caractères) pour distinguer les écritures manuscrites, ainsi que dans la classification de textes, où ils sont très efficaces pour détecter les spams ou analyser les sentiments grâce à leur capacité à gérer des espaces à très haute dimension (comme le vocabulaire d’une langue).
En bio-informatique, ils sont précieux pour la classification des protéines et l’analyse de gènes, un secteur où les échantillons sont souvent rares mais les variables très nombreuses. Enfin, le secteur de la finance les utilise régulièrement pour la prédiction de séries temporelles et le scoring de crédit.
Exemple d’implémentation en Python
Un point crucial mentionné dans la documentation de scikit-learn : les SVM sont très sensibles à l’échelle des données. Si une variable varie entre 0 et 1 et une autre entre 0 et 1000, le SVM sera biaisé. Il faut toujours utiliser un StandardScaler.
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.metrics import classification_report
# 1. Chargement des données (Cancer du sein - binaire)
cancer = datasets.load_breast_cancer()
X = cancer.data
y = cancer.target
# 2. Séparation train/test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. Création du Pipeline (Mise à l'échelle + SVM)
# C'est la bonne pratique : on scale, puis on entraîne.
# On utilise ici un noyau RBF par défaut.
model = make_pipeline(StandardScaler(), svm.SVC(kernel='rbf', C=1.0, gamma='scale'))
# 4. Entraînement
model.fit(X_train, y_train)
# 5. Prédiction et rapport
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=cancer.target_names))Conclusion
Les SVM sont des outils parmi tant d’autres pour faire de la classification.
Ils sont particulièrement efficace lorsque le nombre de données d’entrainement est faible. Par conséquent, dans ce type de cas on les privilégiera aux réseau de neurones qu’on utilise classiquement. Ces derniers sont très performant mais ont besoin d’une très grande quantité de données d’entrainement.



merci pour votre commision