Les auto-encodeurs sont un type de réseaux de neurones avec une architecture particulière, qui les rend utiles pour de nombreuses tâches.

Architecture des auto-encodeurs
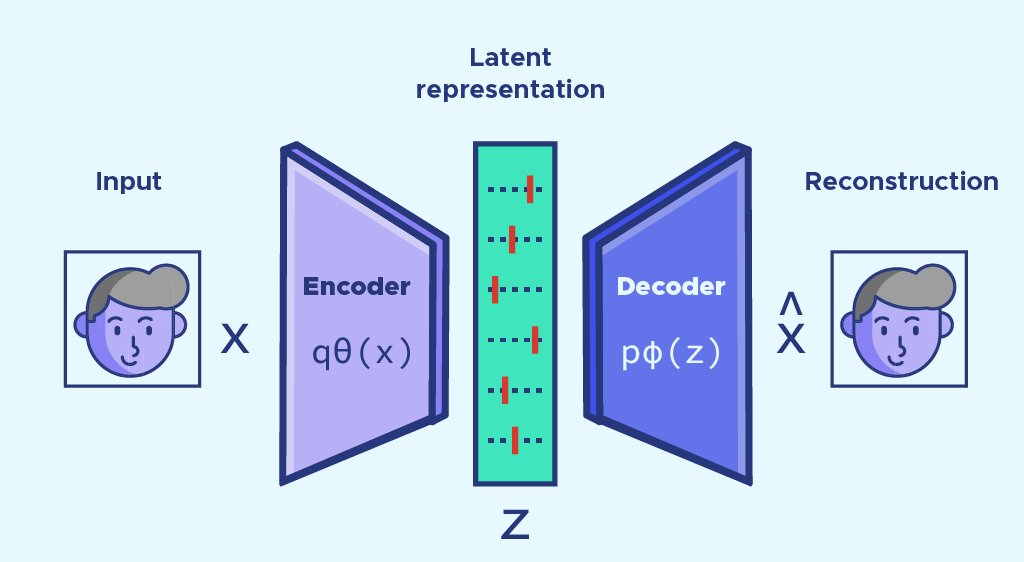
En pratique, un auto-encodeur se décompose en deux parties. La première partie constitue l’encodeur. L’encodeur va permettre de condenser l’information disponible initialement (image, texte, audio, etc.) en extrayant des features qui caractérisent du mieux possible l’information initiale. Le vecteur qui résulte de l’encodeur est de taille beaucoup plus petite que le vecteur initial.
Le décodeur constitue la deuxième partie d’un auto-encodeur. Il se charge de reconstruire l’information de départ, à partir du vecteur condensé. Par exemple lorsque l’on travaille sur des images, quand il est bien entraîné, un auto-encodeur est capable de prendre une image en entrée, de la condenser dans un vecteur de petite taille via l’encodeur, puis de la recréer uniquement grâce à ce vecteur de petite taille, via le décodeur.

Les auto-encodeurs ont une architecture sous forme d’entonnoir avec l’encodeur à gauche, le décodeur à droite. Ils sont utilisés pour la compression de données, pour l’extraction de features ou encore pour générer ou débruiter des images.
Espace latent
Une fois les données d’entrée encodées, elles sont présentes sous une nouvelle forme dans un espace particulier appelé espace latent.
L’espace latent correspond à une nouvelle représentation de nos données d’entraînement. Dans cette nouvelle représentation on condense uniquement les informations les plus importantes qui sont contenues dans nos données d’entraînement, tout en filtrant le bruit, c’est le principe de la features extraction.
Lorsque l’espace latent est bien construit, il préserve les éventuelles similarités entre les données et permet d’avoir une structure continue de nos data. Par exemple avec la base d’images de chiffres manuscrits MNIST, voici la visualisation d’un espace latent de taille 2 :

Vous devez voir cette image comme un repère en dimension 2. On voit que les classes de chiffres sont bien séparées, et que les chiffres similaires sont proches.
Entraînement d’un auto-encodeur
Pour entraîner un auto-encodeur, on lui fournit des données en entrée qu’il doit être capable d’encoder dans un espace d’une dimension fixée, puis de décoder à partir de l’encodage obtenu. Pendant l’entraînement on s’attend à ce que le modèle nous donne en sortie ce qu’on lui a fournit en entrée.
Pour suivre l’entraînement on fixe une loss qui repose sur le calcul de la distance entre la donnée fournie en entrée et celle reçue en sortie, on parle de reconstruction loss.
Les autres étapes de l’entraînement des auto-encodeurs sont similaires à ceux des architectures de réseaux de neurones classiques. On a une fonction d’optimisation et des paramètres à calibrer.
Si on arrive à reconstruire la donnée d’entrée uniquement grâce à l’encodage, c’est qu’il contient assez d’informations, dans le cas contraire c’est peut être dû à la trop petite taille de l’espace latent.
Applications des auto-encodeurs
Comme je l’ai mentionné en introduction, les applications des auto-encodeurs sont nombreuses. Je vous en présente quelques-unes dans cette partie.
Utilisation des auto-encodeurs pour générer des images
Avant que les GAN ne deviennent incontournables pour générer de nouvelles images, les auto-encodeurs permettaient déjà de le faire. Pour cela on n’a qu’à utiliser le décodeur pour décoder des vecteurs de l’espace latent qui ne sont pas présents dans notre dataset initialement.
On peut faire des opérations sur nos données ou même de l’interpolation entre deux observations, comme avec les chaises ci dessous :

On part de la première version de notre chaise en bas à gauche qui a un certain encodage dans l’espace latent, si on est en 2D on peut noter cet encodage (x0, y0) par exemple, à la deuxième version de la chaise en bas à droite dont l’encodage peut-être noté (x1, y1).
On va ensuite se déplacer progressivement entre (x0, y0) et (x1, y1), décoder ces vecteurs à chaque fois, et observer le passage en temps réel d’un type de chaise à l’autre.
Auto-encodeurs pour le débruitage d’images
Les auto-encodeurs peuvent aussi servir à débruiter des images. Le bruit dans les images englobe toutes les imperfections et les pixels mal positionnés qui peuvent être corrigés.
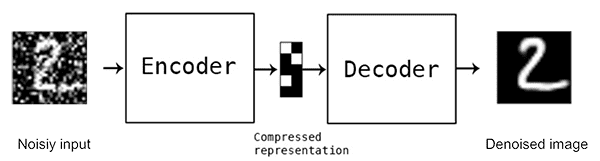
Pour entraîner un auto-encodeurs de ce genre une option possible est de simuler un bruitage de données sur les données d’entraînement, de fournir les données bruitées en entrée de l’auto-encodeur et d’avoir les images débruitées en sortie.
En pratique, les meilleures solutions pour générer ou débruiter des images qui reposent sur des auto-encodeurs fonctionnent avec des auto-encodeurs variationnels (VAE). Les VAE apprennent la distribution de probabilité des données et permettent donc d’assurer la continuité des encodages obtenus. Mais ça, ce sera le sujet d’un prochain article 🙂


Félicitations!!! Mais j’avais une question, est-il possible d’utiliser les auto-encodeurs pour analyser les sentiments?
Oui on pourrait les utiliser pour de la features extraction mais ce n’est pas trop l’usage, même si je pense que ça pourrait bien fonctionner. Si tu veux on a un article d’introduction à l’analyse de sentiments.