
Le deep learning, littéralement apprentissage profond, est une branche de l’intelligence artificielle qui donne aux machines la capacité d’apprendre à réaliser certaines tâches, à partir d’une grande quantité de données. Les dernières prouesses réalisées par des modèles de deep learning font couler beaucoup d’encres.

Certains y voient même de la magie… D’autres l’associent à Terminator et ses collègues. Désolé de vous l’apprendre, mais la réalité est beaucoup moins cool que ça…
Point sur le vocabulaire utilisé
Comme tous les domaines sur lesquels une grande attention est portée, le deep learning est sujet à des confusions énormes quant au vocabulaire que l’on utilise. Beaucoup de gens confondent encore deep learning, machine learning et intelligence artificielle.
En réalité, le deep learning est un sous domaine du machine learning qui lui-même est un sous domaine de l’intelligence artificielle. Pour simplifier on parle souvent d’IA bien que ce soit de l’abus de langage.
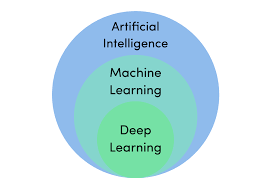
Le problème est que ce qui semble n’être qu’un manque de rigueur dans l’appellation, entraîne de grandes confusions. Ainsi, beaucoup voient les systèmes de machine learning comme la modélisation mathématique de l’intelligence humaine, même lorsqu’il s’agit simplement de faire de l’analyse de données.
Applications du deep learning
Evidemment le deep learning n’est pas seulement de l’analyse de données au sens habituel. Avant d’aborder ce point, revenons sur quelques-unes des nombreuses applications du deep learning.
Deep learning pour le traitement d’images
La première application du deep learning qui me vient à l’esprit est la computer vision. De façon surprenante des tâches qui sont simples pour le cerveau humain, comme la reconnaissance de formes ou la reconnaissance faciale, constituent de vrais défis pour les machines. Pendant longtemps les systèmes disponibles étaient peu performants pour ce genre d’activités.
L’émergence du deep learning et les travaux de chercheurs comme Yann Le Cun sur des modèles de réseaux de neurones à convolutions (les CNN), ont propulsé la computer vision dans une autre dimension.
Aujourd’hui on arrive même à concevoir des systèmes de traitements de radiographies qui aident les médecins. Ils sont utilisés pour la détection de cancers, le calcul de l’âge osseux ou lors de coloscopies.
Deep learning pour le traitement de données textuelles
Ces dernières années ont vu un ralentissement des progrès faits en computer vision, mais ce ralentissement profite à d’autres domaines comme le NLP, ou Natural Language Processing.
Comme son nom l’indique, le NLP est le domaine du machine learning qui offre à la machine la possibilité de traiter le langage humain. Les applications du NLP sont nombreuses : détection automatique de spams, traducteurs automatiques, analyse de sentiments des utilisateurs, etc.
Le dernier système de NLP en date est un peu troublant et très effrayant lorsque l’on ne connaît pas la technologie utilisée. Il s’agit de GPT-3. C’est un modèle de NLP conçu par Open AI pour générer des textes. Même si l’application en elle-même n’est pas nouvelle puisqu’Open AI avait déjà rendu des travaux de ce genre, GPT-3 constitue une nouvelle étape de franchie. Il est quasiment impossible de faire la distinction entre un texte généré par GPT-3 et un texte écrit par un humain (cette phrase aussi aurait pu être générée automatiquement haha).
Impressionnant non ? La technique est clairement maîtrisée, mais pour l’éthique je pense qu’il faudra repasser…
Deep learning pour la reconnaissance vocale
Bon celle-là vous la connaissez bien. Siri, Alexa, Google Home, ils ont tous un point commun. Ils reposent sur la reconnaissance vocale. La reconnaissance vocale semble être une interface beaucoup plus naturelle pour nos interactions avec les machines. C’est pour cela qu’ils sont en train de s’imposer comme une norme.
Pour que ces systèmes fonctionnent, on doit traiter un grand nombre de données. Le but est d’établir une correspondance entre le signal audio que la machine reçoit et ce que la personne dit. C’est typiquement le genre de choses que le deep learning permet de faire très facilement.
Introduction aux réseaux de neurones
Le deep learning repose sur des modèles mathématiques, apparus dans les années 50, les réseaux de neurones. Pour alimenter encore un peu plus la confusion, il se trouve que les neurones formels (les objets qui composent les réseaux de neurones donc), sont très inspirés du comportement des neurones de notre cerveau. Mais rassurez-vous, le neurone formel n’est rien de plus qu’une modélisation très simpliste et loin du fonctionnement d’un vrai neurone.
Même s’ils sont à la mode aujourd’hui, les réseaux de neurones ont longtemps été négligés par la communauté scientifique. D’abord car il n’y voyait pas un grand intérêt. Mais aussi à cause de la disponibilité des données, très faible à l’époque, et à cause des faibles capacités de traitement et de stockage des données.
Le neurone formel
Avant de définir ce qu’est un réseau de neurones, il faut expliquer ce qu’est un neurone au sens mathématique du terme. Ce modèle a été introduit par McCulloch et Pitts en 1943. Ils ont construit un neurone binaire très simple qui prenait plusieurs entrées et faisait la moyenne pondérée de ces entrées. Ensuite, si cette moyenne est supérieure à un certain seuil le neurone renvoie 1, sinon il renvoie 0. Les coefficients pour la moyenne pondérée sont ce que l’on appelle les poids.
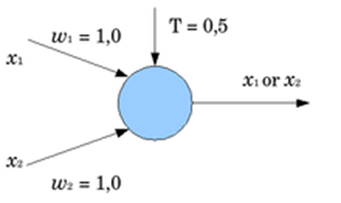
D’un neurone simple à un réseau complet
Croyez-le ou non, c’est cet objet tout simple qui donne au deep learning des capacités presque infinies. Evidemment d’un point de vue théorique, les choses sont un peu plus complexes que cela. Je ne rentrerai pas dans les détails, mais sachez qu’il y a de nombreux autres paramètres à considérer.
Une fois que l’on a construit un premier neurone formel, l’idée est de les assembler pour construire un réseau de neurones. C’est à partir de ce moment que l’on fait du deep learning !
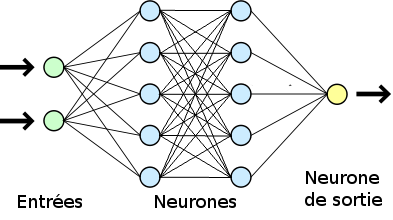
Les neurones sont séparés en couches et les neurones de deux couches différentes peuvent être connectés entre eux. Le nombre de neurones et l’architecture dépendent beaucoup de l’application. Par exemple pour le traitement de texte on privilégie les structures de type LSTM (long short term memory). Elles permettent d’introduire des liens entre les mots et de ne pas les traiter mot à mot.
L’idée du réseau de neurones est qu’on va lui donner un grand nombre de données d’entrées en lui indiquant la sortie qu’il est censé obtenir. Grâce à ces exemples le réseau va mettre à jour ces paramètres, grâce à des techniques mathématiques d’optimisation. On dit que le réseau s’entraîne. Une fois l’entraînement terminé, le modèle doit pouvoir donner un résultat correct à partir de données qui n’étaient pas présentes dans les données d’entraînement.
Tout ça pour dire que le deep learning et les réseaux de neurones ne sont pas aussi magiques qu’on ne le pense. La peur et l’engouement qu’ils suscitent ne sont que les produits d’une mauvaise communication autour de l’intelligence artificielle.
Même si le deep learning impressionne avec les performances qu’il permet d’obtenir, la conception de modèle peut encore être améliorée. Beaucoup de sujets de recherches vont dans ce sens. Par exemple, un des objectifs est de pouvoir concevoir des modèles moins gourmands en données et mieux explicables tout en conservant les mêmes performances.
Voilà vous connaissez les bases du deep learning !


Laisser un commentaire