
Si vous vous intéressez aux modèles de traitement automatique du langage naturel (NLP), vous avez surement entendu parler de GPT 3, malheureusement peut-être à travers leurs échecs éthiques.
Dans cet article on présente le modèle GPT 3 et on parle de quelques-unes de ses applications.

De GPT 2 à GPT 3
Sous ce sigle à la prononciation potache se cache un des modèles les plus perfectionnés à l’heure actuelle dans le domaine des modèles de langage.
La version sortie en 2019, GPT-2, comptait 1.5 milliard de paramètres, tandis que la dernière version à ce jour (juillet 2020), GPT 3, en compte 175 milliards, ce qui en fait le plus large modèle non-sparsifié1, permettant ainsi sa stupéfiante efficacité.
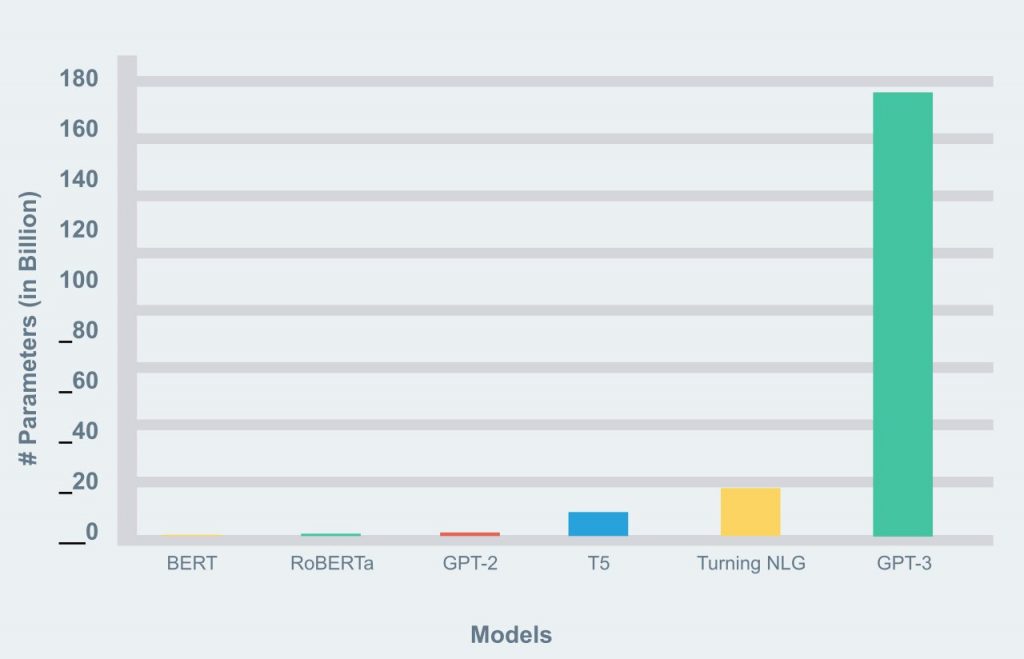
Ce modèle crée par OpenAI a comme objectif de comprendre les relations qu’ont les mots entre eux, et a pour cela scruté des milliers de textes : Plus de 500 milliards de mots ont ainsi été lus par le modèle durant son apprentissage.
Au vu de la puissance de GPT 3 et des implications éthiques, les concepteurs n’ont pas rendu le code open-source et freinent leur rythme de publication. Ainsi, un des risques qu’ils craignent et la création de textes faussement attribués à des personnalités publiques.
1De manière simplifiée, le sparsifying consiste à alléger un modèle de deep learning en supprimant judicieusement des neurones. Il est ainsi plus léger, ce qui est mieux pour un déploiement sur des plateformes à mémoire faible, et permet une exécution plus rapide.
Quelles applications ?
Le modèle est bien trop lourd pour être déployable en local sur un ordinateur personnel (en effet, les 175 milliards de paramètre nécessite 175 Go de RAM) et cela ne correspond pas au business model d’OpenAI. À la place, l’utilisation du modèle se fait via leur API et est facturée suivant la longueur du texte.
On trouve de nombreux usages de ce modèle : Il y a des taches classiques de classification textuelle, de recherche dans une base de données, de chatbot, de traduction, mais aussi des applications plus ludiques comme de la complétion de texte.
GPT 3 peut créer des textes sensés à partir de peu de choses : des règles ou un court préambule suffisent pour inventer du texte qui est souvent difficilement différentiable de ce qu’un humain aurait pu écrire (vous pouvez faire le test ici https://beta.openai.com, la création d’un compte donne droit à un crédit gratuit de 18$, largement suffisant pour essayer GPT 3).
Mais les possibilités sont infinies : on peut trouver un convertisseur de langage de programmation vers un autre langage de programmation ou vers du langage humain, une application de résumé de texte, ou encore une qui à partir d’un texte décrivant une émotion ou un décor associe une couleur. Bref, les exemples sont variés et intéressants, je vous laisse regarder ce qu’OpenAI propose sur leur site et vous amuser avec la multitude d’exemples proposés (https://beta.openai.com/examples).

Mon envie d’écrire sur GPT 3 viens de la découverte d’un site (https://play.aidungeon.io/main/home) se basant sur ce modèle pour proposer des jeux de rôles.
Le principe du jeu est simple : on choisit un cadre (Fantaisie, Mystère, Zombies, Apocalyptique, Cyberpunk, Personnalisé) et un archétype de personnage, et le modèle va nous faire interagir avec un univers crée de toute part, relativement cohérent.
On pourra même modifier ce que le modèle nous propose. Si par exemple un des PNJ (Personnage Non Joueur) de l’univers fait une action qui nous semble absurde ou qui nous déplait, libre à nous de modifier cette action, le modèle saura prendre en compte ce qu’on lui a dit. Des univers ou des scénarios ont aussi été plus construit si on est à la recherche de plus de cohérence dans notre aventure.
Les limites du modèle
Malheureusement, la base d’entrainement provient de documents écrits par l’homme et vu sa taille, personne n’a pu filtrer les aspects négatifs, ce qui aboutit à ce que le modèle comporte les mêmes biais que l’humanité : racisme, sexisme, homophobie.
Je vous renvoie à l’article sur les fails de l’intelligence artificielle pour plus d’informations sur ce sujet.
Cela ne se ressent pas particulièrement pour des taches classiques, mais lorsqu’on lui demande de compléter un texte parlant de personne de certaines ethnies ou croyances religieuses, le modèle risque de ressortir des stéréotypes de manière spontanée.
De plus, le risque de création de fake news est réel, bien que moins dangereux que les vidéos deep fake car plus facilement réfutables.


Laisser un commentaire