
Le Natural Language Processing (NLP) est un domaine de l’intelligence artificielle qui permet à la machine de comprendre les données textuelles.
Contrairement à nous, la machine communique via des données numériques, elle n’est pas capable de comprendre les données textuelles de manière brute.
Par exemple, une machine ne comprend pas le mot « pluie ». Pour réussir à le lui faire comprendre, il faudrait d’abord transformer cette donnée textuelle en donnée numérique. Pour ce faire, plusieurs approches sont possibles, nous en verrons certaines dans la suite.
Dans tous les cas, un modèle de NLP pourra comprendre le mot « pluie » relativement aux autres mots du vocabulaire, mais il ne pourra jamais comprendre de façon consciente le concept de « pluie ».
A l’heure de l’IA générative, notamment avec l’arrivée des LLM, le NLP a pris beaucoup d’importance. Les dernières performances obtenues, comme avec ChatGPT, on ouverts des possibilités infinies dans toutes les industries.
Quelles sont les applications du NLP ?
Le NLP permet de résoudre de nombreux problèmes et trouve son utilité dans de nombreux secteurs et domaines.
De même, le NLP englobe un grand nombre de techniques différentes qui permettent de traiter des sujets variés, en voici quelques-unes :
- La traduction de texte : l’époque des traducteurs en ligne qui faisaient une traduction mot-à-mot des textes est loin. Aujourd’hui, les outils de traduction utilisent tous des approches basées sur le NLP pour comprendre le texte de manière optimale et le traduire suivant son contexte.
- La reconnaissance vocale : la reconnaissance vocale ou speech recognition est une type de technique qui donne aux machines la capacité d’extraire de la données textuelle depuis un audio. Ce type d’utilisation est de plus en plus répandu, avec des assistants comme Alexa de Amazon ou encore le modèle whisper d’OpenAI. Intégrés à des interfaces intelligentes, ces outils permettent de contrôler certaines fonctionnalités de notre maison (allumer/éteindre la lumière par exemple), nous suggérer le meilleur itinéraire pour aller d’un point A à un point B, nous indiquer les prévisions météorologiques, mais également « discuter » avec nous.
- La synthèse vocale : cette technique permet de faire le chemin inverse. Passer d’un texte à un audio. Aujourd’hui on maitrise très bien cette technique, à tel point qu’on peut cloner la voix d’une personne avec quelques secondes de vocal de la personne. Inquiétant ! L’outil de référence pour la synthèse vocale est ElevenLabs.
- Les modèles de langages : les LLM, ou large language models, sont les ambassadeurs du NLP dans sa version moderne. Ceux sont des modèles d’intelligence artificielle capables d’interagir avec un utilisateur de manière naturelle, avec du texte ou de la voix.
- La génération d’images : contrairement à ce que l’on pourrait penser, la génération d’images par intelligence artificielle est une technique qui utilise beaucoup de NLP. La capacité du modèle à générer une image qui se rapproche de la requête de l’utilisateur, dépend beaucoup de la capacité du modèle à comprendre cette requête.
Le NLP pour la classification automatique de textes
Un des exemples classique d’utilisation du NLP, utilisé par Google, est la détection de spam dans les mails. Ces algorithmes analysent les emails qui passent à travers leurs serveurs et signalent et arrêtent les spam avant même qu’ils atteignent votre boite mail.
Pour ce faire, il est nécessaire de faire comprendre à la machine quels sont les mots, phrases, tournures de phrases qui sont synonymes de spam.
Les modèles sont entraînés sur des grandes quantité de données pour réaliser ce travail.
La classification de textes sert aussi en e-commerce, lorsque l’on a une grande quantité de produits à classer de manière automatique en se basant sur leurs descriptions.
Résumé des réunions
Personne n’aime passer du temps en réunion et en visio-conférence, mais elles font partie intégrante de notre quotidien.
Quitte à en faire, autant optimiser le temps passé en capitalisant dessus après la réunion. Les derniers modèles de NLP permettent de faire des transcriptions automatiques des réunions. Ils découpent les transcripts par personne et sont même capables de résumer les points importants et donner une liste d’action concrètes à réaliser après la réunion pour chaque participant.
Si ce genre d’outils vous intéressent vous devriez aimer Fireflies AI.
Encore plus impressionnant que les deux précédents exemples, le NLP est même utilisé afin de prédire si une personne est malade ou non (maladie cardiovasculaire, dépression, schizophrénie) à partir des dossiers médicaux et du discours du patient lui-même (voir https://www.thenewsminute.com/article/tech-giants-india-join-ai-bandwagon-focus-healthcare-93833 pour plus d’informations) !
Il serait réducteur de dire que cette liste de trois cas d’usages du NLP est exhaustive : aujourd’hui, une très grande partie des solutions l’IA reposent sur du NLP.
Comment fonctionne le NLP en pratique ?
La question qui se pose à présent est plus technique : Concrètement, comment on fait pour transformer des données textuelles en données numériques compréhensibles par la machine ?
Cette étape de transformation s’appelle l’encodage de texte, et la version numérique des données textuelles sont appelés les embeddings. Il y a plusieurs approches différentes, nous allons ici en citer quelques-unes dans cet article.
L’approche NLP classique : Tf-IDF (term frequency-inverse document frequency)
Cette approche est l’une des plus anciennes et des plus simples. Elle repose simplement sur les fréquences d’apparence d’un mot dans des document.
Pour les matheux je vous laisse quelques détails mathématiques qui pourraient vous inspirer. Sinon vous pouvez sauter cette partie/
Etant donné un corpus composé de plusieurs documents (Di)i , on calcule, pour chaque mot distinct w les matrices suivantes :


La première matrice TF représente tout simplement la fréquence brute de chaque mot dans chaque document. Il en existe plusieurs variantes, comme par exemple considérer log(1+TF(i,w)) en lieu et place de TF(i,w). Cela n’a pas vraiment d’importance tant qu’on saisit le concept général.
La deuxième matrice, IDF, représente la fréquence inverse de document (inverse document frequency), elle mesure l’importance d’un mot dans l’ensemble du corpus. Elle vise à donner un poids plus important aux termes les moins fréquents, car ils sont considérés comme plus discriminants.
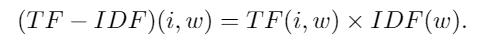
La matrice finale (TF-IDF) est la matrice qui nous intéresse, les deux autres étant des matrices intermédiaire pour l’obtenir. Cette matrice a autant de colonnes qu’il y a de mots (distincts et) différents dans le corpus, et autant de lignes qu’il y a de documents.
Chaque coefficient (i,w) correspond à l’importance (en terme de fréquence) du mot w dans le document Di : c’est ce qu’on appelle son « score TF-IDF ». Les mots qui interviennent trop souvent dans trop de documents différents auront un score faible, alors que les mots qui ont une importance dans le document auront un grand score.
Cette approche a l’avantage d’être simple et de bien fonctionner pour les cas simples. Mais c’est une approche trop simpliste qui ne prend pas en compte la sémantique. Le contexte d’un mot dans la phrase n’est pas pris en compte alors que c’est un point crucial en NLP.
La 2ème approche, word2vec, est plus moderne et contribue en partie à remédier à ce problème.
Word2vec
L’approche word2vec est une méthode d’embedding qui prend en compte la sémantique et le contexte de chaque mot dans la phrase pour le vectoriser (i.e. le transformer en vecteur).
En réalité, c’est un abus de langage de parler de l’approche word2vec puisqu’il existe plusieurs variantes. Nous allons présenter ici la méthode dites « Skip-gram ». Les autres variantes reposent sur le même système mais diffèrent dans certains points moins importants.
La représentation word2vec est faite de telle sorte que deux mots qui aient un sens proche soient également proches en termes de distance vectorielle (par exemple, « chat » sera plus proche de « chien » que de « maison »). Cet algorithme fonctionne sur le principe de distributional semantics (linguistique distributionnelle) qui se base sur l’idée que nous pouvons comprendre le sens d’un mot en regardant le contexte dans lequel il a l’habitude d’apparaitre dans des contextes similaires.
Par exemple, le mot « roi » et « prince » ont plus de chance d’apparaitre ensemble que le mot « roi » et « laverie ». Ainsi, pour connaitre la représentation vectorielle d’un mot, il suffit d’apprendre le contexte dans lequel il a tendance à apparaître.
Comme pour tf-idf je vous mets les détails mathématiques pour les plus courageux 🙂
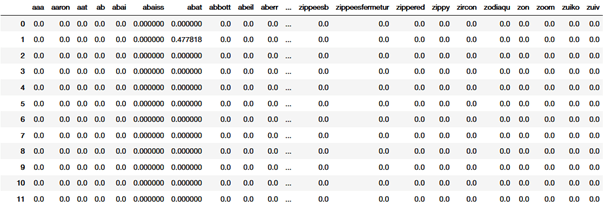
La première étape est de choisir la dimension de la représentation vectorielle (plus elle est élevée plus on est précis, mais plus le modèle est complexe). Notons d cette valeur. Pour chaque phrase du corpus, on parcourt chacun de ses mots ; considérons le mot à la position t, wt, qui sera alors notre mot central (noté c pour context) avec son contexte (noté o, pour outside).
On définit le contexte d’un mot comme suit : on définit une fenêtre de taille m (paramètre que l’on choisit comme on le veut : plus on le prend élevé plus le modèle est susceptible d’être précis, mais plus il est complexe) ce qui signifie que les mots de la position t-m à t+m constituent le contexte de notre mot. Il faut alors maximiser la probabilité d’observer o selon qu’on ait c (et vice-versa). Nous allons noter la probabilité d’observer le mot t+j en connaissant le mot t : P (wt+j | wt).
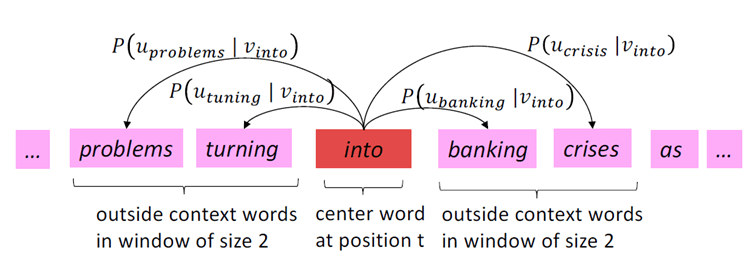
Ainsi, sous l’hypothèse que les observations sont indépendantes, il faut maximiser la vraisemblance suivante :
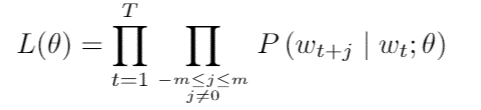
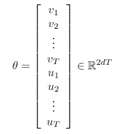
où T représente le nombre total de mots et theta l’ensemble des paramètres du modèles (grosso modo la représentation vectorielle de chaque mots). A chaque mot w on associe deux vecteurs : uw pour le cas où w est considéré comme un mot de contexte et vw pour le cas où w est considéré comme un mot central. Le paramètre theta est donc de la forme :
Une maximisation de la vraisemblance L(theta) conduit donc à trouver la « meilleure » représentation vectorielles de chaque mots.
Cette approche se révèle très efficace mais elle présente le problème de devoir considérer un nombre très élevé de paramètres ( 2 x la dimension x le nombre de mots, ce qui peut atteindre des centaines de milliers voire plus) et donc engendré un coût de calcul très élevé. En pratique, on utilise des modèles qui ont été pré-entrainés par Google sur des millions (voire des milliards) de données et cela fonctionne très bien.
Il n’est cependant pas nécessaire de comprendre toute la théorie pour pouvoir utiliser word2vec (et heureusement !) et nous avons nous même volontairement omis certains détails techniques moins importants dans cet article afin qu’il reste accessible à tout le monde.
NLP et réseaux de neurones
Dans l’approche actuelle du NLP, on utilise surtout les réseaux de neurones.
Les réseaux de neurones sont un type de modèles d’intelligence artificielle qui permettent de faire de l’apprentissage supervisé.
L’idée est de constituer un dataset labélisés avec des valeurs d’entrées et des valeurs de sorties. On utilise ces données là pour « paramétrer » le réseau.
J’explique en détail le fonctionnement des reseaux de neurones dans un de mes articles.
Comme la quantité de données qui peut-être lue par un réseaux de neurones est grande, ils ont facilité la compréhension du contexte dans des données textuelles par les modèles d’intelligence artificielle.
Pendant longtemps, le standard pour le NLP étaient les modèles de réseaux de neurones dit LSTM (Long-Short Term Memory). Ils ont une architecture qui permet de prendre en compte la structure temporelle d’une phrase ou d’un paragraphe. De manière vulgarisée, on peut imaginer que le LSTM construit des liens entre les mots d’une phrase quelque soit leur position dans la phrase.
Néanmoins, le grand défaut des LSTM est leur scalabilité, ils sont difficilement entrainable sur des corpus de données géants et donc moins intéressants. Pour pallier cette limitation, Google et l’université de Toronto ont proposé en 2017 une nouvelle architecture : les Transformers (rien à voir avec le film ahah).
Je parle des Transformers dans l’article suivant.



Laisser un commentaire