Disclaimer, je ne vais pas parler la série américaine Transformers, même si ça ressemble.
A chaque nouvelle évolution en deep learning, on se dit toujours la même chose, cette fois c’est fini, on a atteint le sommet.
Mais à chaque fois on arrive à repousser encore un peu plus les limites.
Les transformers sont une architecture de réseaux de neurones proposés en 2017, par des chercheurs de Google en collaboration avec l’université de Toronto, dans un papier de recherche devenu mythique : Attention is all you need.
Ils ont permis d’atteindre des niveaux jamais égalés sur des sujets comme la compréhension du langage, avec des modèles de références comme BERT ou GPT.
Dans cet article on verra ce que sont les transformers, on parlera de leur fonctionnement et de leurs applications.
Des RNN aux transformers
Les réseaux de neurones sont des modèles statistiques très efficients pour analyser des données complexes et avec des formats variables.
Si des modèles comme les CNN ont émergé pour le traitement de données visuelles, le traitement du texte s’est longtemps appuyé sur les réseaux récurrents (RNN), et plus particulièrement sur les LSTM, capables de mieux gérer la mémoire à long terme.
À partir de ces briques, une classe d’architectures appelée Sequence-to-Sequence ou Seq2Seq est devenue centrale : elle utilise un encodeur pour transformer une séquence en représentation dense, puis un décodeur pour générer une nouvelle séquence en sortie. Ces modèles ont posé les bases des systèmes de traduction automatique, de résumé ou de dialogue, bien avant l’arrivée des Transformers.
Avant d’expliquer le fonctionnement des Transformers plus en détail, revenons à nos LSTM.
Ils permettent de résoudre une des grandes limites des réseaux de neurones classiques : ils permettent d’introduire une notion de contexte, et de prendre en compte la composante temporelle.
C’est ce qui les a rendu populaires pour le traitement du langage. Au lieu d’analyser les mots un par un, on pouvait analyser les phrases dans un contexte très précis.
Néanmoins, les LSTM, et les RNN en général, ne permettaient pas de résoudre tous les problèmes.
- D’abord, leur mémoire est trop courte pour pouvoir traiter des paragraphes trop longs
- Ensuite, les RNN traitent les données de façons séquentielle, et sont donc difficilement parallélisable. Sauf que les meilleurs modèles de langage d’aujourd’hui, se caractérisent tous par une quantité astronomique de données. Entraîner un modèle de LSTM en utilisant les données consommées par GPT-3 aurait pris des décennies.
C’est là que les Transformers entrent en scène, pour révolutionner le deep learning.
Ils avaient été proposé initialement pour des tâches de traduction.
Et leur particularité majeure est qu’ils sont facilement parallèlisables. Ce qui rend l’entraînement sur des bases de données immenses plus rapide.
Par exemple, GPT-3 a été entraîné sur une base de données de plus de 45TB de texte, quasiment tout internet.
Ils ont permis d’atteindre des niveaux de performances jamais égalés sur des tâches comme la traduction ou la génération d’images et sont la base de ce que l’on appelle aujourd’hui l’intelligence artificielle générative.
Les transformers et le principe de l’attention
Sur l’aspect technique, les transformers reposent sur 3 ingrédients fondamentaux :
- L’encodage de la position (position encoding)
- Le mécanisme d’attention
- Et la self-attention
Position encoding
Le position encoding est un composant clé dans les modèles de transformers. Il aide à améliorer leurs performances en comprenant l’ordre des mots dans une séquence de textes.
En pratique, le position encoding ajoute une représentation numérique de la position de chaque mot dans la séquence, ce qui permet au modèle de comprendre l’ordre des mots et d’améliorer ses prédictions.
Prenons l’exemple de la phrase suivante : « Le chat noir mange le poisson. »
Dans ce cas, le position encoding pourrait ajouter une représentation numérique à chaque mot de la phrase, indiquant sa position relative dans la séquence. Par exemple :
- Le : position 1
- chat : position 2
- noir : position 3
- mange : position 4
- le : position 5
- poisson : position 6
Ces informations de position sont incluses dans les entrées du réseau transformers, permettant ainsi au modèle de comprendre l’ordre des mots dans la phrase et de faire des prédictions plus précises.
J’ai demandé à ChatGPT quelle était la différence entre « Le chat noir mange le poisson. » et « Le chat mange le poisson noir. ». Il m’a répondu :
La différence entre « Le chat noir mange le poisson. » et « Le chat mange le poisson noir. » réside dans l’ordre des mots. Dans la première phrase, « noir » se réfère à la couleur du chat alors que dans la seconde phrase, « noir » se réfère à la couleur du poisson.
Lorsqu’on utilise un modèle de traitement du langage pour analyser ces phrases, l’ordre des mots peut avoir un impact important sur la signification et l’interprétation de la phrase. C’est pourquoi il est important d’utiliser des techniques telles que le position encoding pour informer le modèle de l’ordre des mots dans une séquence. Cela permet au modèle de comprendre l’importance relative de chaque mot dans la phrase et de faire des prédictions plus précises.
De l’attention à la self attention
Le principe d’attention utilisé par les transformers est un mécanisme qui permet de concentrer l’attention du modèle sur les mots les plus pertinents dans une séquence de textes. Il permet au modèle de faire une prédiction en fonction de l’ensemble de la séquence plutôt que de simplement considérer chaque mot séparément.
Le mécanisme d’attention utilise des poids pour chaque mot dans la séquence, qui indiquent leur importance relative pour faire une prédiction. Ces poids sont ensuite utilisés pour pondérer les représentations des mots dans la séquence.
Reprenons la phrase « Le chat noir mange le poisson ». Le modèle utilise le mécanisme d’attention pour attribuer des poids aux mots suivants :
- Le : 0.2
- chat : 0.7
- noir : 0.5
- mange : 0.9
- le : 0.3
- poisson : 0.6
Les représentations numériques de chaque mot dans la phrase sont ensuite pondérées en fonction de ces poids. Par exemple, la représentation de « chat » serait multipliée par 0.7, tandis que la représentation de « le » serait multipliée par 0.3. Les représentations pondérées sont ensuite utilisées pour faire une prédiction, permettant au modèle de se concentrer sur les mots les plus pertinents pour la tâche.
De cette façon, le modèle prend des décision basées sur tous les mots présents dans la séquence, plutôt que mot à mot. Ce qui le rend très puissant sur des tâches de traduction par exemple. Surtout dans les langues comme le français dans laquelle on a une dépendance grammaticale forte entre les mots.
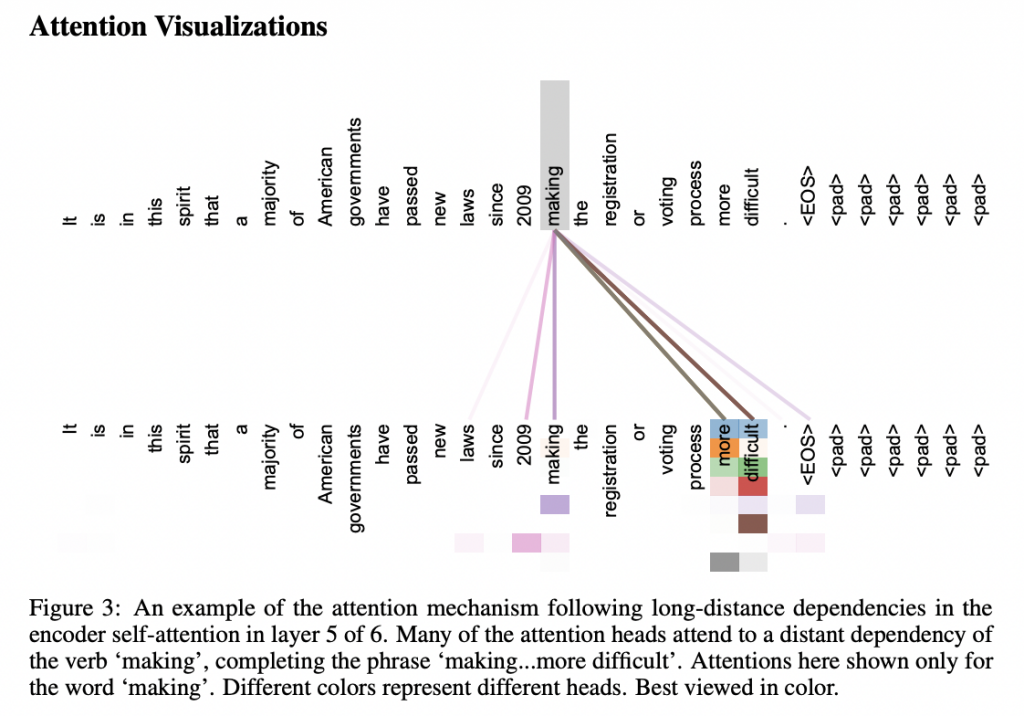
Le mécanisme d’attention, bien qu’important pour les transformers, n’est pas une innovation, il existait depuis longtemps.
Par contre, les inventeurs des transformers, ont apporté une nouvelle innovation : la self-attention.
Ici, on peut ajouter une pondération différente pour chacun des mots de la séquence, là où l’attention proposait une pondération à l’échelle de toute la phrase.
Par exemple, prenons la phrase suivante: « Le chat mange du poisson sur la table ».
Dans un modèle de self-attention, chaque mot de la phrase peut peser l’importance des autres mots pour comprendre le contexte global de la phrase. Le mot « chat » peut donner plus d’importance aux mots « mange » et « poisson » pour comprendre l’action qui se déroule, tandis que le mot « table » peut donner plus d’importance aux mots « sur » et « mange » pour comprendre où cette action se déroule.
Cela permet au modèle d’obtenir une représentation plus complète et plus significative de la phrase.
Quelles sont les applications des transformers ?
Même si à l’origine les Transformers ont été designés pour le traitement du langage, leurs performances les ont rendus utiles dans de nombreux domaines.
Ils ont largement été introduits pour de nombreuses tâches comme :
- Traitement du langage naturel (NLP): Les transformers sont souvent utilisés pour les tâches NLP telles que la classification de texte, la génération de texte, la traduction automatique, etc.
- Recommandation: Les modèles de transformers peuvent être utilisés pour recommander des produits ou des contenus à des utilisateurs en fonction de leur historique d’achats ou de navigation.
- Vision par ordinateur: Les transformers peuvent être utilisés pour les tâches de vision par ordinateur, telles que la reconnaissance d’objets, la génération d’images et la segmentation d’images.
- Jeux: Les transformers peuvent être utilisés pour les jeux, tels que les jeux d’aventure textuels, en fournissant des réponses contextuelles à des joueurs.
- Finance: Les transformers peuvent être utilisés pour les applications financières telles que la classification de données financières et la prédiction des tendances du marché.
Conclusion
En conclusion, les transformers sont devenus un outil indispensable pour de nombreux domaines grâce à leur capacité à gérer efficacement les dépendances à longue portée dans les entrées.
Leur scalabilité permet de les entraîner sur d’immenses bases de données, et leurs donnent un avantage considérable sur les modèles de LSTM.



Laisser un commentaire