
L’un des avantages des modèles de machine learning et de deep learning, est qu’ils sont facilement adaptables à toutes les situations. C’est d’ailleurs cette flexibilité qui les rend aussi populaires.

La contre partie est qu’ils sont assez difficiles à paramétrer, tant le nombre de degrés de liberté est élevé pour certains modèles. Et même si un premier entraînement avec des paramètres arbitraires vous donne de bonnes performances, vous pourriez améliorer encore ces performances en optimisant les paramètres choisis.
Vocabulaire : les paramètres des modèles de machine learning que l’on peut modifier sont appelés des hyperparamètres. Attention à ne pas les confondre avec les paramètres du modèle qui eux sont calculés automatiquement pendant l’entraînement.
Exemple : le nombre de couches d’un réseau de neurones est un hyperparamètre, le biais d’un neurone donné est un paramètre du réseau.
Le nombre d’hyperparamètres à optimiser peut varier d’une méthode à l’autre. Si pour les SVM on en a 2 ou 3 (le C et le gamma, et le kernel peut être considéré comme un hyperparamètre dans certains cas), pour les méthodes avec des arbres de décisions on peut en avoir plus de 20. Et pour les méthodes de deep learning le nombre d’hyperparamètres à optimiser peut rapidement devenir très grand.
Il est donc clair que même le meilleur data scientist ne pourrait pas trouver instinctivement tous ces paramètres. Heureusement, on a plusieurs méthodes qui peuvent nous aider à faire ce travail. Dans cet article, je vous en présente 3.
Gridsearch
Si vous avez suivi mes précédents tutoriels, vous connaissez sans doute déjà cette méthode. Son fonctionnement est assez simple et très intuitif.
Comme son nom l’indique on va considérer le problème d’optimisation comme un problème de recherche dans une grille. En pratique, on va simplement fixer pour chaque hyperparamètres, un ensemble de valeurs qu’il peut prendre. Ensuite, pour chaque combinaison d’hyperparamètres, on va entraîner notre modèle et conserver les résultats de performances en mémoire. Il suffira ensuite de prendre les hyperparamètres pour lesquels les performances sont les meilleurs.
Dans le cas où on a uniquement 2 paramètres, on peut représenter la grille sous forme d’une matrice :
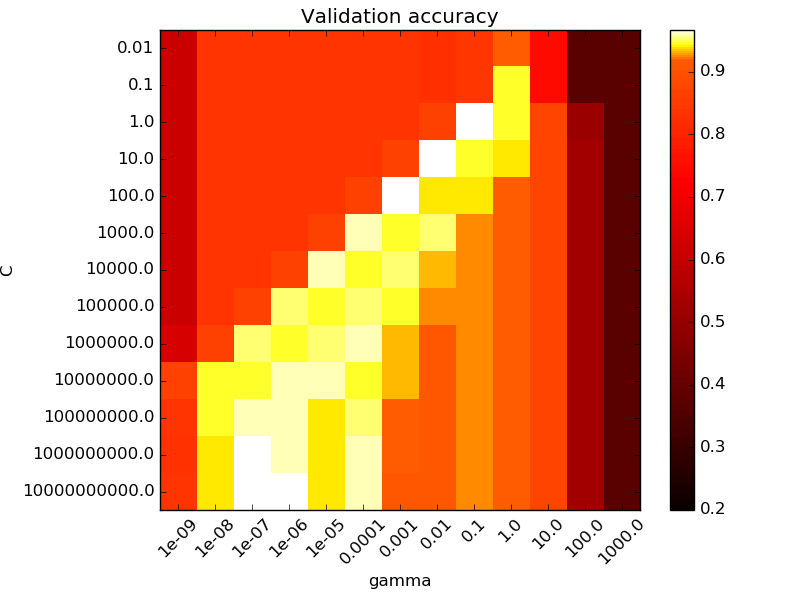
Je pense qu’à ce stade vous commencez à voir la grosse limitation de grid search. On va très vite être limités en termes de capacités de calculs. Si on a 5 hyperparamètres à optimiser avec 5 valeurs possibles pour chaque hyperparamètres, on doit entraîner notre modèle 3125 fois. Si l’entraînement du modèle prend 10 minutes à chaque fois, il vous faudra 3 semaines pour essayer toutes les combinaisons. Même si les méthodes par grilles on l’avantage d’être facilement parallélisable, cette méthode n’est clairement pas optimale.
C’est pour cela que la méthode gridsearch doit être utilisée lorsque le nombre d’hyperparamètres à optimiser est assez faible. Dans ce cas elle donne de bons résultats et elle est très facile à implémenter avec scikit learn.
Random search
Une des options pour pallier cette grosse limitation de gridsearch, est d’utiliser la méthode random search. On garde le système de grille mais on change notre façon de sélectionner les combinaisons de paramètres à chaque étape.
Cette fois, plutôt que de fixer un ensemble de valeurs prises par un hyperparamètre donné, on va fixer un intervalle de valeurs et on va associer à chaque hyperparamètre une distribution de probabilités. Ensuite, à chaque itération, on entraîne le modèle et on garde les résultats de performances en mémoire.
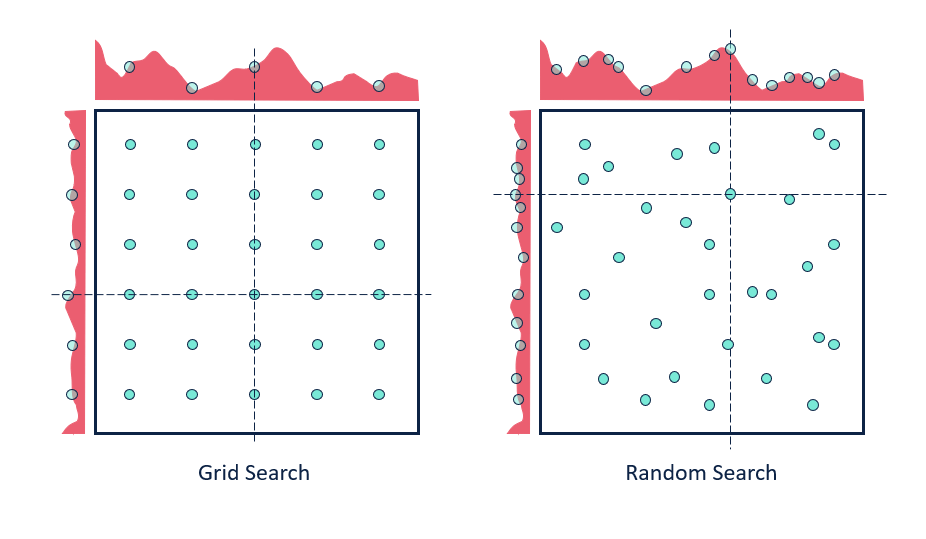
L’avantage de la méthode random search est qu’elle permet de couvrir des zones non visitées par gridsearch et donc d’avoir plus d’informations. Et cela sera d’autant plus vrai lorsque le nombre d’itérations sera assez élevé.
Approches bayésiennes
La méthode random search est déjà un peu plus intéressante que gridsearch en pratique, mais son coût en temps de calcul reste encore élevé. On peut encore faire un peu mieux.
Que ce soit pour grid search ou pour random search, les itérations sont faites indépendamment les unes des autres. Pour random search, même si on a une zone pour laquelle les performances sont faibles, on peut continuer à tirer des combinaisons d’hyperparamètres dans la même zone. On aimerait que l’algorithme « détecte » les zones dans lesquelles les performances sont trop faibles et s’en éloigne lorsqu’il fait le prochain tirage aléatoire.
Plutôt que d’oublier toute l’information récupérée, on voudrait l’utiliser et la mettre à jour au fil des itérations. C’est là qu’interviennent les méthodes bayésiennes. Exactement comme en statistiques bayésiennes, on va fournir une information a priori à l’algorithme pour qu’il puisse faire ses recherches en laissant de côté les zones avec des performances trop faibles.
On observe qu’en pratique les méthodes bayésiennes sont plus optimales et tout aussi efficaces que les méthodes par grilles.
Bien que ces méthodes soient d’une grande aide lorsque l’on entraîne un modèle de machine learning, il faut garder en tête que rien ne vaut une compréhension théorique poussée des algorithmes utilisés. En combinant cette connaissance théorique aux a priori que l’on a sur le problème étudié, on peut éviter de faire des erreurs d’une part, mais aussi tirer un meilleur parti des méthodes présentées ici.


Laisser un commentaire