
Les données manquantes sont un des nombreux problèmes que vous êtes amenés à gérer lorsque vous travaillez sur des projets concrets de machine learning. C’est assez rare d’avoir des datasets propres sur lesquels vous pouvez entraîner un modèle sans pré-traitements.

Heureusement, je vous ai préparé quelques techniques simples à mettre en place, qui peuvent vous aider à gérer vos données manquantes dans la majorité des cas.
Si vous utilisez Pandas vous pourrez récupérer les codes que je mets dans cet article 🙂
Les retirer lorsque leur quantité est raisonnable
C’est un peu radicale comme approche mais c’est la meilleure façon de traiter vos données manquantes. Evidemment il ne sera pas toujours possible de mettre en oeuvre cette méthode, il arrive que vous ayez de grandes quantités de valeurs manquantes (c’est subjectif mais personnellement je considère qu’on a beaucoup de données manquantes au delà de 30%).
Evidemment, avant de faire ça vous devrez regarder le pourcentage de données manquantes pour chaque variables. Si vous travaillez avec Pandas j’ai un code pour vous :
size = df.shape
nan_values = df.isna().sum()
nan_values = nan_values.sort_values(ascending=True)*100/size[0]
ax = nan_values.plot(kind='barh',
figsize=(8, 10),
color='#0000FF',
zorder=2,
width=0.85)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.tick_params(axis="both",
which="both",
bottom="off",
top="off",
labelbottom="on",
left="off",
right="off",
labelleft="on")
ax.set_title("Taux de valeurs manquantes pour chaque variable du dataframe df")
vals = ax.get_xticks()
for tick in vals:
ax.axvline(x=tick, linestyle='dashed', alpha=0.4, color='#eeeeee', zorder=1)Voilà le résultat que vous obtiendrai :
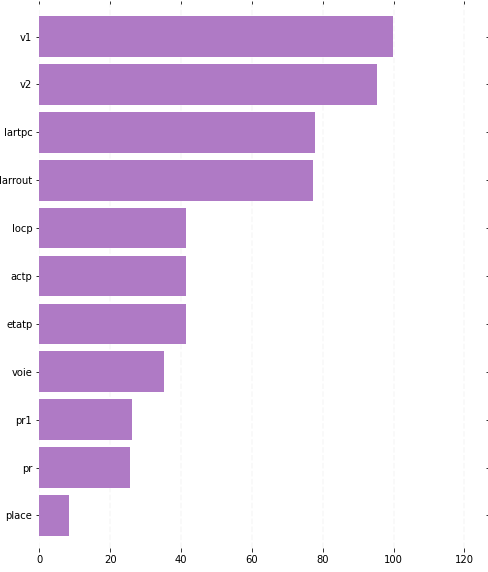
Après avoir fixé un seuil arbitraire de valeurs manquantes vous devrez retirer les variables qui dépassent ce seuil. Si le seuil est de 50%, vous devrez retirer les variables v1, v2, lartpc et larrout. Voici comment faire ça :
df.drop(columns=['v1', 'v2', 'lartpc', 'larrout'])Compléter les données manquantes par interpolation
Pour des variables continues, il peut être assez facile de faire de l’interpolation. L’interpolation consiste à compléter une valeur en regardant la valeur précédente, la valeur suivante ou les deux en même temps.
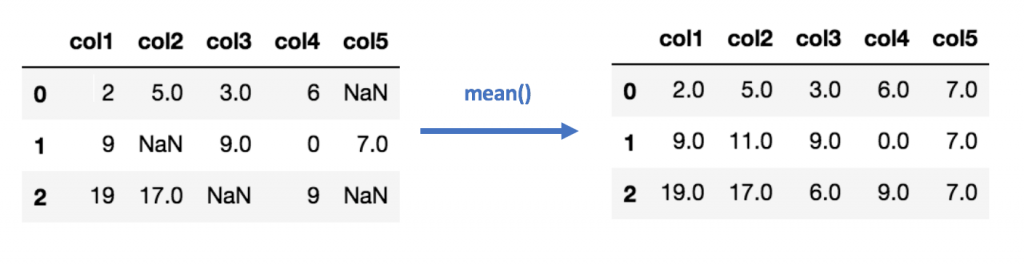
Les méthodes d’interpolation sont nombreuses. Une des approches possibles pourrait être de remplacer les données manquantes par la moyenne entre la valeur précédente et la valeur suivante. Cette technique permet de remplacer quelques lignes mais il est évident que ce n’est pas la méthode la plus robuste.
Avec Pandas on peut faire d’autres types d’interpolations un peu plus intéressants. Les méthodes sont nombreuses, on peut faire une interpolation linéaire ou polynômiale avec différents ordres par exemple :
# Interpolation linéaire :
df.interpolate(method='linear',
limit=None)
# Interpolation polynômiale d'ordre 3 :
df.interpolate(method='polynomial',
order=3,
limit=None)L’inconvénients de ces approches est que vous pouvez interpoler uniquement les variables qui présentent des valeurs manquantes bien réparties. L’interpolation donne de très mauvais résultats lorsque le gap de valeurs manquantes est élevé. C’est tout l’intérêt de l’argument limit dans df.interpolate. Il va vous permettre de fixer une limite de lignes à interpoler, je suggère de ne pas aller au delà de 2 car vous pourriez avoir de mauvaise surprises…
Voici deux exemples d’interpolation :
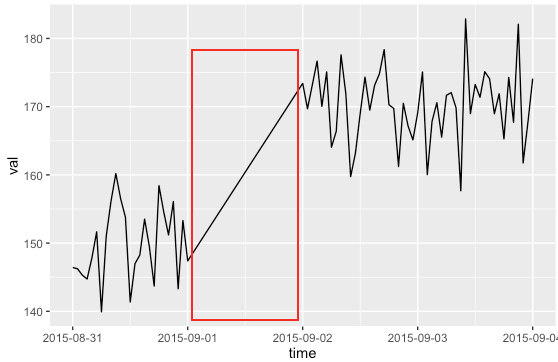
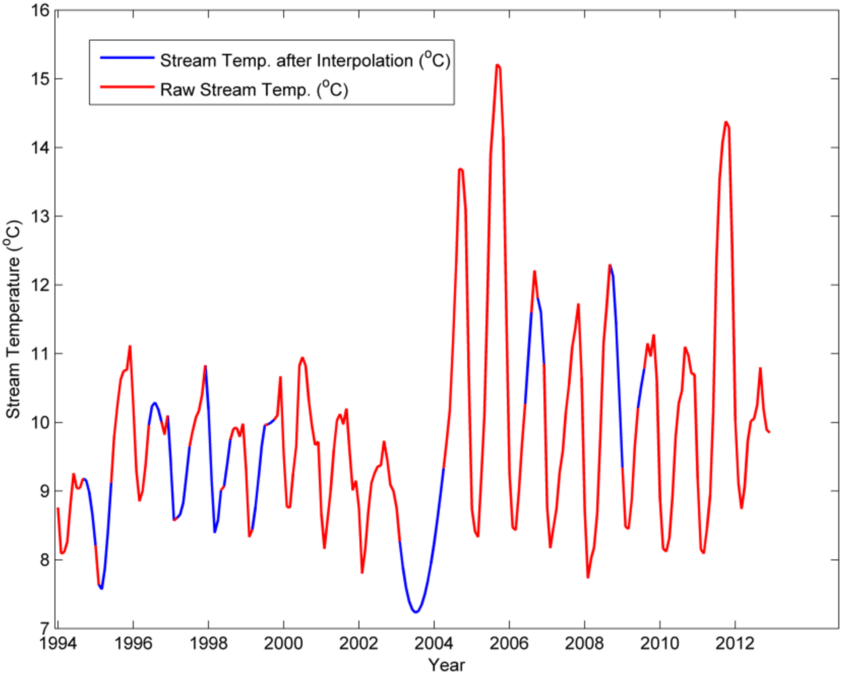
Regression avec une variable corrélée
Avant de commencer la création de votre modèle, il est important de bien comprendre vos données. En particulier, l’étude des corrélations entre vos variables est importante. En plus d’éviter de fausser l’entraînement de vos modèles, elle peut vous aider à compléter des valeurs manquantes.
Si vous voyez une forte corrélation entre une variable X1 et une variable X2, vous pourrez compléter les valeurs manquantes de l’une en utilisant les valeurs disponibles de l’autre en faisant une simple régression.
Pour tracer la matrice de corrélation commencez par créer un sous dataframe de votre dataframe de base qui ne contient pas de valeurs manquantes, puis calculer la matrice des corrélations :
df_full = df.dropna(inplace=False)
df_full.corr()Cherchez ensuite les variables fortement corrélées, visualiser la dépendance entre ces variables sur un scatter plot :
import matplotlib.pyplot as plt
plt.scatter(df_full['X1'],
df_full['X2'])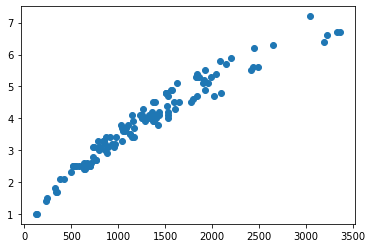
Le scatter plot est souvent suffisant pour déterminer le type de régression nécessaire. Par exemple ici il est clair qu’on a une dépendance polynômiale.
Vous pouvez ensuite l’implémenter avec Scikit-learn.
Code pour une régression linéaire :
from sklearn.linear_model import LinearRegression
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score
x = df_full['X1'][:, np.newaxis]
y = df_full['X2'][:, np.newaxis]
model = LinearRegression()
model.fit(x,y)
y_predict = model.predict(x)
rmse_linear = np.sqrt(mean_squared_error(y,y_predict))
print(rmse_linear)
plt.scatter(x, y)
plt.plot(x, y_predict, color='g')
plt.show()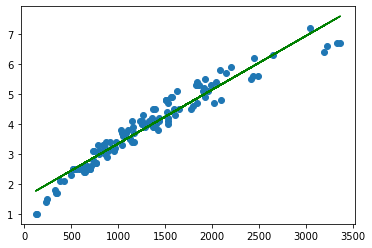
Code pour une régression polynômiale :
from sklearn.preprocessing import PolynomialFeatures
x = df_full['X1'][:, np.newaxis]
y = df_full['X2'][:, np.newaxis]
polynomial_features = PolynomialFeatures(degree = 2)
x_poly = polynomial_features.fit_transform(x)
model_2 = LinearRegression()
model_2.fit(x_poly, y)
y_poly_pred = model_2.predict(x_poly)
# Mesure des scores obtenus :
rmse = np.sqrt(mean_squared_error(y,y_poly_pred))
print(rmse)
plt.scatter(x, y, s=10)
sort_axis = operator.itemgetter(0)
sorted_zip = sorted(zip(x,y_poly_pred), key=sort_axis)
x_p, y_poly_pred_P = zip(*sorted_zip)
plt.plot(x_p, y_poly_pred_P, color='r')
plt.title("Régression polynômiale de degré 2")
plt.show()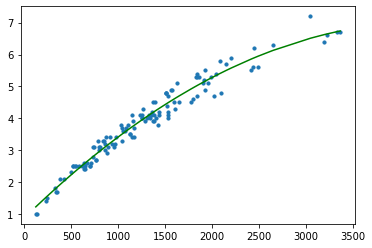
Voilà, il ne reste plus qu’à reprendre le dataframe initial et remplacer les valeurs manquantes de X2 en faisant une prédiction à partir de X1.
Garder les données manquantes et utiliser des méthodes d’apprentissage adaptées
Certains algorithmes peuvent être entraînés avec des valeurs manquantes. C’est par exemple le cas de k-nn, de certaines méthodes bayésiennes ou de random forest. Les résultats ne sont pas garantis si vous avez trop de données manquantes, mais dans certains cas ces méthodes méritent d’être considérées.
Lorsque vous voulez entraîner un réseau de neurones, certains suggèrent de simplement transformer vos valeurs manquantes en 0 et d’entraîner votre modèle avec ces nouveaux vecteurs. Il semblerait que les poids affectés aux données soient beaucoup plus faibles lorsque la valeur est nulle. Avec Pandas vous pouvez transformer les nan en 0 en faisant ça :
df.fillna(0)Pour conclure, les données manquantes ne sont qu’un des nombreux problèmes que vous êtes amenés à résoudre lorsque vous traitez des données de la vie réelle. Il est primordiale de passer du temps sur l’étude de vos données et d’évaluer leur qualité, cela vous évitera bien des déconvenues au moment de l’entraînement de vos modèles.


Laisser un commentaire