
OpenAI a rendu possible le fine tuning de ChatGPT, via la version GPT-3.5, en août 2023.
Dans cet article je t’explique tout ce que tu dois savoir et je t’offre même un petit notebook Google colab à la fin pour que tu puisses le faire toi même.
Avant de rentrer dans le vif du sujet, je vais reprendre les bases, expliquer ce qu’est le fine-tuning et quand est-ce qu’il sera utile dans ce cas là.
Je donnerais des infos sur le pricing de l’API de ChatGPT pour cette partie (je te rassure c’est pas très cher ahah).
Ensuite je te donne le code python pour :
- préparer ton dataset
- fine-tuner ChatGPT sur ce dataset
- utiliser ton modèle
Ce qu’il faut savoir
Avant de commencer le fine-tuning du modèle, je vais expliquer ce que c’est, quand est-ce qu’il est utile. Je parlerais aussi des spécificités liées à l’API de ChatGPT et de son pricing.
Qu’est-ce que le fine-tuning et quand est-ce utile ?
En deep learning, le fine tuning fait référence à une technique où un modèle pré-entraîné sur une grande base de données est ensuite légèrement réentraîné (ou affiné) sur un ensemble de données plus petit et spécifique à une tâche donnée.
Cette méthode est particulièrement utile lorsque l’on dispose de peu de données pour une tâche spécifique, car elle permet de bénéficier des connaissances générales acquises par le modèle lors de son entraînement initial sur une grande base de données.
Dans le cas de ChatGPT et des LLM en général, le fine tuning sera utile dans les cas où le prompting ne suffit pas et où le modèle a besoin de plus de connaissances spécifiques.
OpenAI précise que le fine-tuning doit rester la dernière option, lorsque le prompting classique n’a pas suffit.
Combien faut-il de données ?
Cette question est important, malheureusement je n’ai pas de réponse.
Ni moi ni personne d’ailleurs, il y a un gros débat dans la communauté des chercheurs en deep learning sur les quantités de données necéssaires pour le fine tuning d’un modèle.
OpenAI fixe à 10 le nombre minimal d’exemples (un exemple est une paire question – réponse), mais suggère de donner entre 50 et 100 paires question / réponse pour avoir de meilleurs résultats.
Pricing de l’API pour le fine-tuning
Voici le pricing donné par OpenAI sur son site :
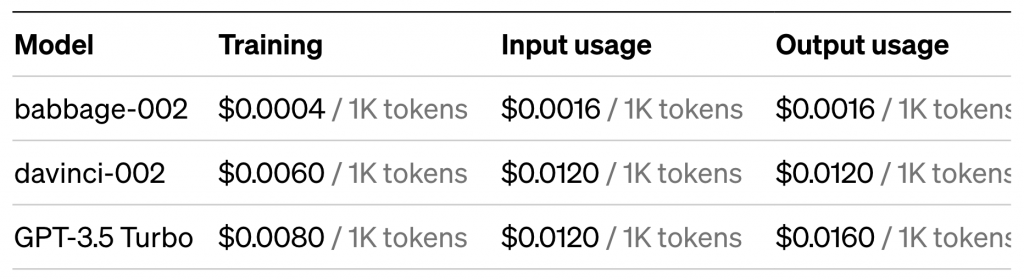
Une époque d’entraînement coûte 0.008$ pour 1000 tokens (environ 750 mots).
Donc un entraînement sur un dataset de 75000 mots (environ 100k tokens), couterait autour de 0,80$ par époque. Pour commencer à avoir des résultats on va faire 3 époques en moyenne ce qui fait 2,40$.
Il faut remarquer aussi que le coût d’inférence est environ 2 fois plus cher sur un modèle fin-tuné que sur le modèle de base.
OpenAI propose des outils qui permettent d’évaluer les coûts de fine-tuning et d’inférence sur ces modèles.
Fine-tuner ChatGPT via Python et l’API d’OpenAI
Maintenant qu’on connaît le principe du fine-tuning et les spécificités introduites par OpenAI pour ChatGPT, on peut rentrer dans le vif du sujet.
Installation et import des librairies
Pour que ça soit plus simple je te conseille d’utiliser Google Colab. Mais tous les codes proposés fonctionnent en local.
On commence par installer la librairie d’OpenAI puis importer le module :
!pip install openai
import openaiSetup de la clé API
Maintenant, il faut se rendre sur son espace perso OpenAI pour générer une clé API, et la copier-coller ici :
openai.api_key = "VOTRE_CLE_API"Tu peux générer une clé API ici en allant dans « Personal » puis « View API keys ».
Sur l’espace perso on peut aussi contrôler la facturation et fixer des limites de budget. Je conseille de le faire au cas où tu ferais une erreur dans ton code.
Préparation du dataset
On va maintenant préparer notre dataset.
Pour cela il faut 2 choses :
- créer un message system qui permet de définir le rôle de l’assistant
- créer des paires de questions réponses
Pour le message system il suffit de décrire l’assistant que l’on souhaite au final, OpenAI donne l’exemple suivant :
Marv is a factual chatbot that is also sarcastic.En ajoutant les paires questions / réponses le fichier d’entraînement doit ressembler à ça :
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}Il faut le mettre dans un fichier .txt avec un exemple par ligne.
On change ensuite l’extension en .jsonl .
Donc le fichier de data doit être au format json lines (.jsonl), avec un exemple par ligne.
Je rappel qu’il faut au minimum 10 exemples.
J’ai appelé mon fichier « ./train.jsonl », je vérifie que mon fichier est bon en l’enregistrant sur le server d’OpenAI, ce code va me donner un id de fichier qui sera utilisé au moment de l’entraînement :
openai.File.create(
file=open("./train.jsonl", "rb"),
purpose='fine-tune'
)Fine-tuner ChatGPT
Une fois que le dataset est prêt et que l’on a notre id de fichier, on lance le fine-tuning de cette manière :
openai.FineTuningJob.create(training_file="VOTRE_FILE_ID", model="gpt-3.5-turbo")Le fine-tuning prend un peu de temps mais le code s’execute en arrière plan sur les serveurs d’OpenAI. Tu recevras un email avec l’id du modèle une fois celui-ci entraîné.

Une fois le ou le(s) modèle(s) entraîné(s), on peut retrouver les informations avec ce code :
openai.FineTuningJob.list(limit=10)Utilisation du modèle fine-tuné
Une fois l’email reçu avec l’id de modèle (la partie avec les étoiles sera incluse dans l’email), on peut l’utiliser comme ça :
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo-************",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello! Descripe yourself in simple words"}
]
)
print(completion.choices[0].message)Voilà, tu sais maintenant comment fine-tuner ChatGPT, j’espère que tu vas pouvoir créer des choses intéressantes, n’hésite pas à me contacter sur Linkedin si besoin.
Et comme promis, voici le lien du Colab.



Laisser un commentaire