
MLflow est aujourd’hui l’outil open source le plus utilisé pour industrialiser des modèles de machine learning. De la phase d’expérimentation au déploiement, la plateforme couvre tout le cycle de vie d’un modèle : suivi d’expériences, gestion centralisée des artefacts, versioning, packaging, et même déploiement.
Dans cet article, on va comprendre ce qu’est réellement MLflow, les problèmes qu’il résout dans un workflow de machine learning moderne.
On prendra en main la plateforme avec un cas pratique simple : entraîner et versionner un modèle de classification sur le dataset Iris.
Qu’est-ce que MLflow ?
MLflow est une plateforme open source pensée pour structurer et automatisatiser tout le cycle de vie du machine learning : de l’expérimentation au déploiement.
Elle s’inscrit pleinement dans les principes du MLOps : la discipline qui vise à appliquer les bonnes pratiques du DevOps au monde du ML afin de rendre les modèles reproductibles, traçables, gouvernables et réellement exploitables en production.
Elle répond à un problème simple : le ML produit énormément de variables (paramètres, code, données, modèles, environnements…) et sans cadre, tout devient rapidement difficile à suivre, à reproduire ou à industrialiser.
Pour résoudre ce chaos, MLflow s’appuie sur quatre modules complémentaires, chacun ciblant une étape clé du workflow ML.
1. MLflow Tracking
Beaucoup d’équipes ML travaillent encore avec des notebooks où les paramètres sont modifiés manuellement avec des résultats notés dans un coin. Résultat : impossible de comprendre pourquoi une expérience fonctionne mieux qu’une autre. Impossible de reproduire un run précis, et encore moins de collaborer efficacement.
MLflow Tracking apporte une réponse directe à ces problèmes.
Il permet :
- d’enregistrer tous les paramètres d’entraînement,
- de loguer automatiquement les métriques,
- de centraliser les artefacts (plots, modèles, fichiers),
- de tracer le code exact exécuté,
- et de reconstituer l’environnement d’exécution.
Chaque exécution est entièrement documenté.
Depuis l’interface web, vous pouvez comparer visuellement vos essais, filtrer les meilleurs runs, et explorer chaque détail de l’expérimentation.
En pratique, MLflow Tracking devient rapidement la mémoire centralisée de votre travail.
2. MLflow Models
Le second pilier de MLflow est MLflow Models. Il fournit un standard unifié pour packager n’importe quel modèle, quel que soit le framework utilisé.
Que vous travailliez avec scikit-learn, PyTorch, TensorFlow, XGBoost, LightGBM, CatBoost ou même des modèles de langage de grande taille, MLflow propose un format homogène qui encapsule tout ce dont le modèle a besoin pour être exécuté.
Concrètement, un modèle enregistré via MLflow inclut à la fois les fichiers de poids, les instructions précisant comment le charger et l’invoquer. Ainsi que les dépendances nécessaires à son fonctionnement (définies dans un fichier conda.yaml ou une liste de packages pip).
Cette approche permet de déplacer un modèle d’un environnement à un autre facilement. Sans devoir reconstruire manuellement toute la stack logicielle autour.
Un modèle MLflow peut ainsi être rechargé en Python en une seule ligne de code, servi instantanément en API REST via la commande mlflow models serve, intégré dans un conteneur Docker pour tourner sur Kubernetes, ou encore déployé sur des plateformes cloud comme Azure ML, SageMaker, Databricks ou Vertex AI.
L’intérêt de ce format standardisé est simple. Une fois packagé, un modèle devient portable, prédictible et réutilisable par d’autres membres de l’équipe ou d’autres systèmes.
Au lieu de gérer des scripts et environnements disparates, tout le monde manipule la même unité logique. Le modèle MLflow, prêt à être testé, validé, comparé ou déployé en quelques minutes.
3. MLflow Registry
Lorsque plusieurs modèles commencent à circuler dans une équipe, un nouveau défi apparaît. Comment les versionner proprement, les comparer, documenter leur historique et décider lequel doit aller en production ?
C’est exactement le rôle du MLflow Model Registry, un espace centralisé qui sert de référentiel officiel pour tous les modèles de l’organisation.
Chaque modèle y possède un nom unique et peut exister sous la forme de plusieurs versions. Chacune étant documentée, annotée et associée à une description.
Le Registry introduit également la notion de stages. Ils permettent d’indiquer le statut opérationnel d’un modèle dans son cycle de vie.
Une version peut ainsi rester en mode expérimental (None), passer en Staging pour être testée, devenir le modèle de référence en Production, ou être reléguée dans Archived lorsqu’elle n’est plus utile.
Grâce à ce mécanisme, le Registry offre un véritable workflow de gouvernance : on sait en permanence quel modèle est déployé, avec quelle configuration il a été entraîné, qui l’a validé et quelles versions l’ont précédé.
Ce niveau d’organisation transforme la manière de collaborer autour des modèles. Au lieu de gérer des fichiers dispersés dans des dossiers, des mails ou des checkpoints locaux, toute l’équipe travaille sur une source de vérité unique, fiable et traçable.
4. MLflow Projects
Dans le machine learning, deux frustrations reviennent constamment : l’impossibilité de reproduire exactement un notebook exécuté par un collègue, et la difficulté à reconstituer l’environnement précis nécessaire pour relancer une expérience.
MLflow Projects a été conçu pour éliminer ces zones d’ombre en proposant un format léger qui décrit de manière explicite tout ce qu’un projet ML doit contenir : le code utilisé, les dépendances nécessaires, l’entrée principale du programme et les paramètres attendus.
Grâce à cette structure, chaque projet devient immédiatement reproductible. Il peut être relancé localement d’un simple appel de commande, orchestré dans un pipeline CI/CD, exécuté sur un cluster de calcul ou déployé dans un environnement cloud sans qu’aucune ambiguïté ne subsiste sur la configuration à utiliser.
L’idée est simple : encapsuler une expérience de façon suffisamment claire pour qu’elle puisse être rejouée à l’identique, où que vous soyez et quel que soit le contexte d’exécution.
Même si ce module est souvent moins mis en avant que MLflow Tracking ou le Model Registry, il reste fondamental pour bâtir des workflows robustes.
Dès qu’une équipe cherche à partager, automatiser ou industrialiser ses expérimentations, MLflow Projects devient un outil clé pour garantir la cohérence et la fiabilité du processus de bout en bout.
Comment utiliser MLFlow ?
Pour illustrer le fonctionnement de MLflow, on va s’appuyer sur un exemple très simple : la classification du dataset Iris. Il s’agit d’un jeu de données classique en machine learning, composé de mesures de fleurs (longueur des pétales, largeur des sépales, etc.) et d’une étiquette correspondant à l’espèce.
Dans cet exemple, nous allons entraîner un modèle random forest, avec la fonction RandomForestClassifier. L’objectif n’est pas de maximiser les performances du modèle, mais simplement d’observer comment MLflow capture automatiquement les paramètres, les métriques et les artefacts générés pendant l’entraînement.
En réalité, peu importe la complexité du projet : que vous entraîniez un simple modèle scikit-learn, un réseau de neurones PyTorch, un modèle TensorFlow de plusieurs millions de paramètres ou même un LLM, le code lié au tracking MLflow reste le même. Seule la partie spécifique au modèle (le code d’entraînement lui-même) change.
Setup de notre environnement
On commence par installer MLflow :
pip install mlflowPuis scikit-learn pour l’exemple :
pip install scikit-learnLa commande pour lancer l’interface MLflow est très simple :
mlflow uiL’outil s’ouvrira par défaut dans votre localhost au port 5000 s’il est disponible.
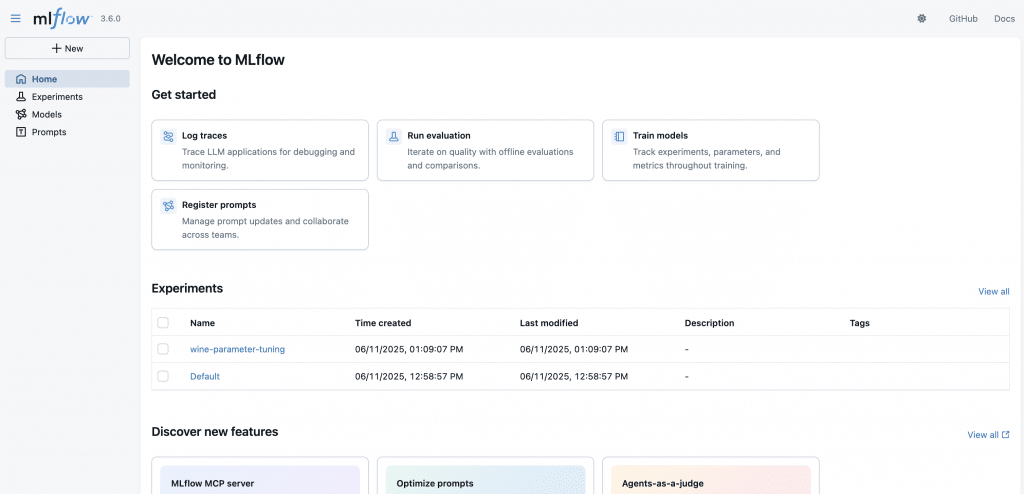
Initialiser MLflow Tracking
Voici le code python qui comporte le code pour l’entraînement du modèle ainsi que le tracking. Il doit être lancé dans le même répertoire de travail que celui dans lequel on a lancé mlflow :
import mlflow
import mlflow.sklearn
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Charger les données
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Démarrer un run MLflow
with mlflow.start_run():
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
acc = accuracy_score(y_test, preds)
# Enregistrer une métrique
mlflow.log_metric("accuracy", acc)
# Enregistrer le modèle
mlflow.sklearn.log_model(clf, "model")Dès qu’on lance un entraînement il s’ajoute dans la liste de l’expérience « Default ». On pourrait créer une liste d’expérience séparée, si on veut séparer nos différents projets par exemple.
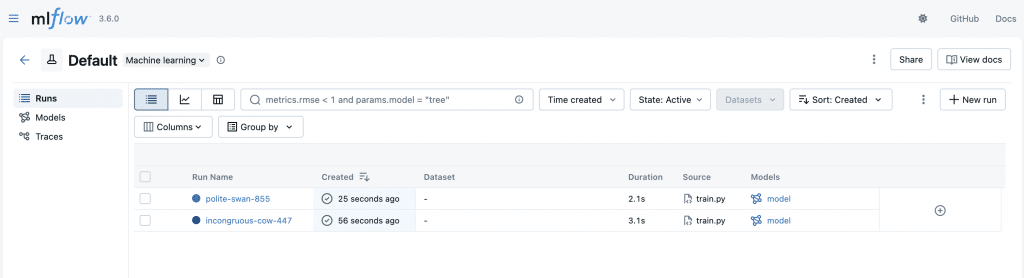
On peut ouvrir une page détaillée pour un entraînement donné :
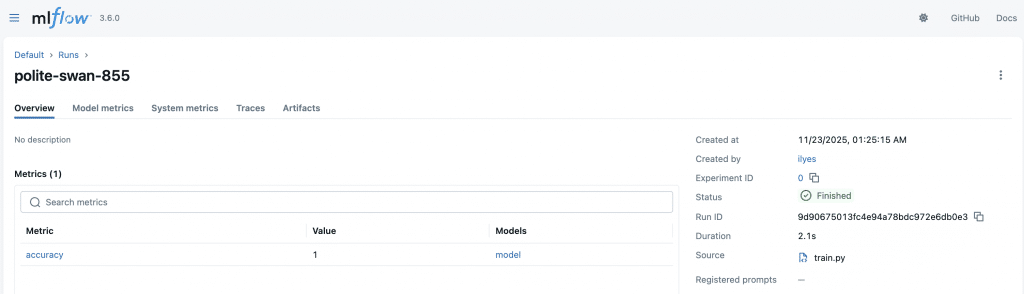
On peut voir plusieurs informations utiles comme : le temps d’entraînement, l’auteur de l’entraînement, le fichier utilisé, etc.
Pour ce premier exemple on a demandé à mlflow de tracker uniquement l’accuracy, via :
mlflow.log_metric("accuracy", acc)Enfin, on peut comparer des résultats d’entraînement, simplement en les sélectionnant puis en cliquant sur « Compare » :
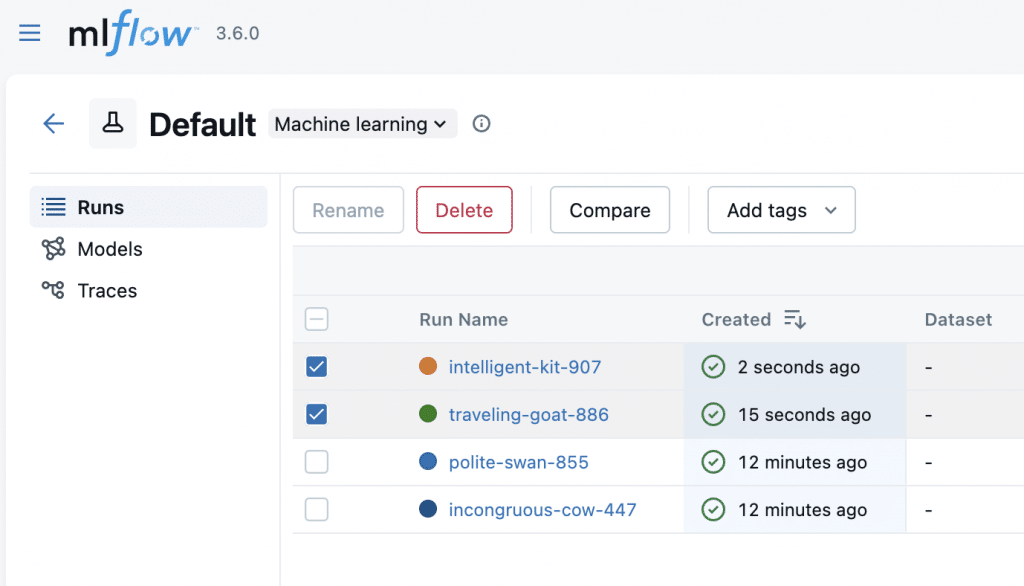
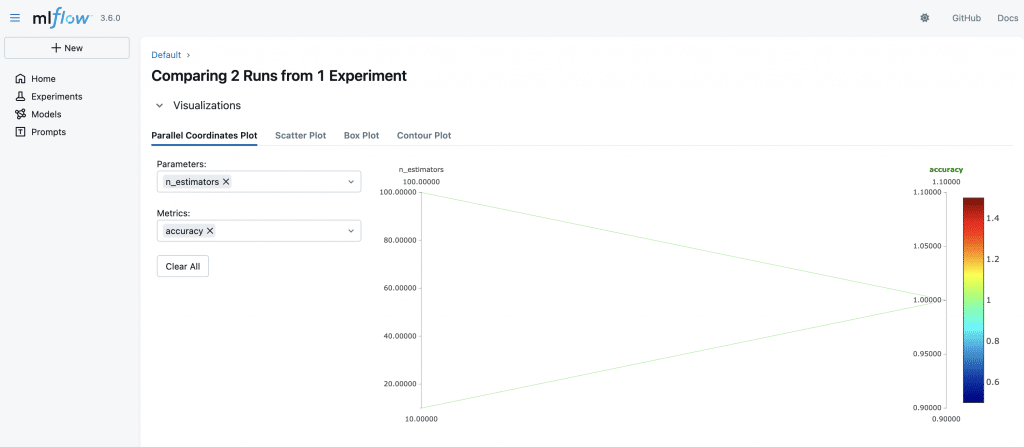
Pour que la comparaison ait du sens, on peut ajouter le tracking d’un hyper-paramètre du modèle au choix. Ici j’ai fait varier le nombre d’estimateurs et j’ai ajouter cette ligne :
mlflow.log_param("n_estimators", n_estimators)Voici le résultats de la comparaison :
Activer MLflow Autolog
On peut travailler de manière encore plus direct. La fonctionnalité Autolog de MLFlow capture automatiquement : les paramètres du modèle, les métriques, les artefacts.
Il suffit simplement de remplacer le code python par :
mlflow.autolog()
with mlflow.start_run():
clf = RandomForestClassifier()
clf.fit(X_train, y_train)Enregistrer et promouvoir un modèle
MLflow Registry vous permet d’organiser vos modèles comme un véritable produit logiciel. Chaque modèle peut être versionné proprement, documenté avec une description claire et enrichi de métadonnées utiles pour l’équipe.
Vous pouvez également le faire évoluer à travers différents stades. Par exemple le placer en Staging pour les tests internes, le promouvoir en Production lorsqu’il devient la version officielle. Ou encore l’archiver lorsqu’il n’est plus d’actualité.
L’ensemble de ces transitions est conservé dans l’historique du Registry, ce qui offre une traçabilité complète et permet de comprendre facilement comment un modèle a progressé au fil du temps.
Conclusion
MLflow est aujourd’hui un standard incontournable pour industrialiser le machine learning. Il apporte structure, traçabilité et fiabilité à vos workflows, que vous soyez data scientist, ML engineer ou responsable d’un produit IA.
Grâce à MLflow Tracking et Autolog, vous bénéficiez d’un suivi complet des expériences, tandis que le Model Registry vous permet de versionner et de promouvoir vos modèles avec un niveau de gouvernance digne d’un cycle logiciel mature.
Mais l’intérêt de MLflow ne s’arrête plus au machine learning « classique ». L’écosystème évolue rapidement vers des applications basées sur des LLM, des pipelines d’IA génératives plus complexes et des systèmes multi-agents.
Pour répondre à ces nouveaux besoins, MLflow a récemment intégré des fonctionnalités orientées LLMOps, notamment grâce aux améliorations de la version 3.x : suivi des prompts, traçabilité des appels aux modèles, capture des embeddings, logging automatique des entrées et sorties, et instrumentation fine des coûts et du comportement des LLM.
Ces avancées rendent possible un niveau d’observabilité qui était jusqu’ici réservé aux plateformes spécialisées.



Laisser un commentaire