
Les réseaux de neurones récurrents (RNN) sont au cœur du traitement moderne des données séquentielles. Qu’elles soient textuelles, temporelles, des audios, capteurs ou interactions continues.
Un exemple simple de donnée séquentielle est celui d’une série temporelle représentant la température horaire d’une journée. Ou encore une phrase considérée comme une suite ordonnée de mots.
Les réseaux de neurones classiques, dits feed-forward, traitent chaque élément indépendamment. Ce qui les rend peu adaptés à la modélisation du contexte ou de la dépendance temporelle.
Les réseaux de neurones récurrents (RNN) ont été conçus pour répondre à ce besoin. Leur architecture intègre une notion de mémoire : chaque élément de la séquence est traité en tenant compte de l’état précédent.
Cet article propose une vue claire pour comprendre leur fonctionnement, leurs limites et leurs principales variantes.
Architecture et fonctionnement du RNN
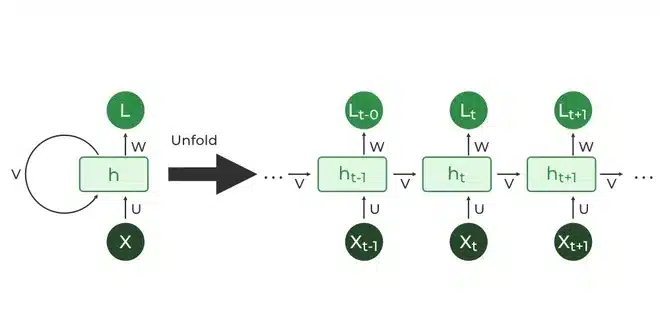
Un RNN peut être imaginé comme un système qui lit une séquence pas à pas. Un peu comme une personne qui lit une phrase en se souvenant des mots précédents pour comprendre le sens global.
À chaque nouvel élément de la séquence, il met à jour une « mémoire interne » qui lui permet de tenir compte du contexte déjà rencontré.
Cette idée de mémoire est au cœur du fonctionnement des RNN. Plutôt que de traiter chaque élément isolément, ils construisent progressivement une compréhension de la séquence grâce à cette boucle interne.
On peut visualiser un RNN comme un petit module qui se répète à chaque étape, transportant avec lui un état qui évolue au fil du temps.
Les limites de cette architecture
L’entraînement d’un RNN repose sur la propagation des erreurs d’un pas de temps à l’autre afin d’ajuster les poids du modèle. Lorsque la séquence est longue, ces erreurs doivent remonter de nombreuses étapes successives, ce qui crée deux phénomènes bien connus :
- le vanishing gradient : les gradients deviennent si petits qu’ils n’ont pratiquement plus d’effet sur les premières étapes de la séquence ;
- le exploding gradient : les gradients deviennent au contraire trop grands, rendant l’apprentissage instable.
On détecte ces problèmes de plusieurs façons. En pratique, on observe souvent que le modèle n’apprend presque rien lorsqu’il souffre de vanishing gradient. Les loss stagnent, les premières parties des séquences sont ignorées. Seules les informations récentes influencent les prédictions.
À l’inverse, un exploding gradient se manifeste par des pertes qui explosent soudainement, des valeurs NaN dans les poids ou une instabilité soudaine de l’entraînement.
L’impact concret est important. Un RNN touché par du vanishing gradient sera incapable de capturer des dépendances longues. Ce qui limite drastiquement ses performances sur des tâches comme la modélisation de texte ou de séries temporelles complexes.
Un exploding gradient, lui, peut rendre le modèle inutilisable en détruisant rapidement les poids.
Pour limiter ces effets, plusieurs approches existent. On peut découper les séquences en segments plus courts, surveiller et ajuster les gradients (par exemple via le gradient clipping), choisir des initialisations plus stables.
On peut aussi ajouter des skip connections. Ils permettent au gradient de circuler plus facilement en créant des raccourcis directs entre différentes couches ou étapes temporelles).
En pratique, on s’oriente vers des architectures conçues précisément pour contourner ces difficultés, comme les LSTM ou les GRU.
Les variantes principales des RNN : LSTM, GRU, Bi-RNN
Face aux limites des RNN simples, plusieurs architectures plus robustes ont émergé :
- Les LSTM (Long Short‑Term Memory)
Les LSTM introduisent un mécanisme de portes (entrée, sortie, oubli) permettant de contrôler finement la circulation de l’information dans le temps.
Leur structure permet de conserver la mémoire sur des séquences beaucoup plus longues et les a rendus incontournables avant l’essor des Transformers.
- Les GRU (Gated Recurrent Unit)
Les GRU simplifient la mécanique des LSTM tout en conservant l’essentiel de leurs avantages.
Elles utilisent deux portes seulement (mise à jour et réinitialisation). Ce qui les rend plus légères et souvent plus rapides à entraîner.
- Les RNN bidirectionnels
Les réseaux bidirectionnels (Bi‑RNN, Bi‑LSTM, Bi‑GRU) traitent la séquence dans les deux sens.
Cette double lecture améliore les performances sur les tâches où le contexte futur est aussi important que le contexte passé, comme l’analyse de texte ou la reconnaissance vocale.
Quelles sont les applications des RNN ?
Les RNN ont été largement utilisés avant la domination des modèles Transformer et restent pertinents dans une grande variété de domaines.
En traitement du langage naturel, ils ont longtemps constitué la base des systèmes de génération de texte, de prédiction de mots ou de classification de documents.
Ils ont également joué un rôle central dans les architectures Seq2Seq utilisées pour la traduction automatique, où leur capacité à encoder puis décoder des séquences était particulièrement adaptée.
Les RNN sont aussi très utilisés pour le traitement de séries temporelles. Qu’il s’agisse de prévision, de détection d’anomalies ou d’analyse de signaux continus.
Leur capacité à modéliser l’évolution d’une variable dans le temps en fait une solution naturelle pour ce type de tâches. Ils ont également occupé une place majeure dans la reconnaissance vocale et l’analyse audio, où la dimension séquentielle est fondamentale.
Enfin, les RNN s’appliquent aujourd’hui à de nombreux autres domaines fondés sur des séquences : clics utilisateurs, données de capteurs biologiques, signaux physiologiques, et bien plus encore.
Même si aujourd’hui les Transformers dominent dans de multiples domaines, les RNN demeurent très utiles pour des systèmes embarqués, des applications en temps réel, ou des contextes où la légèreté du modèle est un critère essentiel.
Conclusion
Les réseaux de neurones récurrents ont joué un rôle fondamental dans l’évolution du deep learning appliqué aux données séquentielles. Leur capacité à intégrer une forme de mémoire interne en fait des outils particulièrement adaptés aux tâches dépendant du contexte.
Même si les architectures Transformer dominent aujourd’hui de nombreux domaines, comprendre les RNN reste essentiel pour saisir l’histoire, les limites et les fondements des modèles séquentiels modernes. Ils constituent la base conceptuelle qui a permis l’émergence des modèles actuels : la notion d’état caché, l’importance du contexte, la dynamique temporelle, ou encore les premières architectures encoder‑decoder.
Au‑delà de leur rôle historique, les RNN rappellent que la modélisation de séquences ne repose pas uniquement sur la puissance de calcul. Mais aussi sur la manière de structurer l’information dans le temps. Ils restent pertinents dans des environnements aux ressources limitées, pour des tâches en temps réel, ou lorsque la simplicité et l’efficacité priment.


Laisser un commentaire