
Petite devinette.
Quel est le point commun entre l’IA de Squid game qui arrive à tuer les bonnes personnes au 1, 2, 3 soleil, l’IA du PSG qui détecte automatiquement que Messi ne court pas beaucoup et celle d’Amazon qui sait instantanément ce que vous avez pris dans le rayon (repose le paquet de gâteau, je t’ai vu) ?
C’est que toutes ces IA reposent sur de la computer vision, qui est l’un des domaines de l’intelligence artificielle les plus actifs. Ses applications sont infinies, et de plus en plus d’industries en dépendent (repose les gâteaux je t’ai dit!).
Dans cet article je présente les techniques de computer vision les plus utilisées, et je parle de leurs différentes applications.
De la détection à la segmentation automatique d’objets
La technique de computer vision la plus utilisée est la détection automatique d’objets. Ca tombe bien car c’est aussi celle que l’on maitrise le mieux! Ses applications vont de la gestion du traffic routier à la détection de tumeurs, en passant par la vidéo surveillance.
Dans un des articles de La revue IA j’ai montré les étapes pour entraîner un modèle de détection automatique des joueurs en football professionnel.
En pratique, un modèle de détection d’objets va tracer un rectangle (appelé bounding box) autour de l’objet qui est détecté, mais dans certains cas on a besoin d’une plus grande précision, c’est là qu’intervient la segmentation.
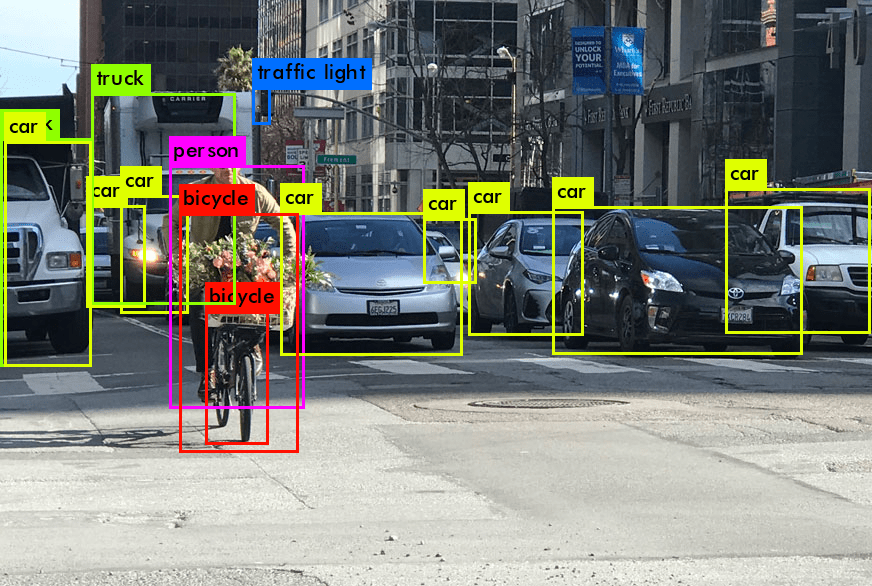
La segmentation automatique d’image permet de détecter de façon plus précise les contours de l’objet, plutôt que de le localiser grossièrement avec une bounding box.

La référence pour la détection automatique d’objets est YOLO, et Detectron 2 est très utilisé pour faire de la segmentation.
Tracking video
Dans le cadre de la détection automatique d’un objet, on cherche seulement à localiser l’objet sur une image. Il arrive parfois que l’on est besoin de détecter puis de suivre à travers plusieurs images le même objet ou la même personne. Cette technique s’appelle tracking automatique.
Elle repose sur des modèles d’extraction de features assez précis et sensibles aux variations intra-classe (entre 2 personnes différentes par exemple). Elle est très utilisée dans les systèmes de vidéo surveillance ou en sport.
Un des outils qui peut être utilisé pour du tracking de personne est DeepSort, il est open source et facile à utiliser.
La computer vision pour la détection et la classification d’actions
De manière générale la computer vision permet à la machine de mieux comprendre ce qui passe dans une image ou une vidéo. Aujourd’hui on peut entraîner des modèles capables de détecter et de classifier les actions qui sont réalisées par un humain dans une image ou une vidéo.
La détection d’activités humaines a des applications dans de nombreux domaines mais elle reste encore très peu utilisée en pratique. Elle peut être utilisé pour les interactions humains-machines, pour de la surveillance ou encore dans le sport.

Reconstruction de scènes
La reconstruction de scènes consiste à retrouver la forme en 3D d’une structure (objet, personne, animal, paysage, etc.) à partir d’une ou plusieurs images en 2D de cette structure. Elle permet d’extraire le profil complet de la structure sous forme d’un modèle mathématique complet, à partir duquel on peut extraire toutes les dimensions et les courbures.
Là encore les applications sont infinies. En sport elle permet d’extraire les contraintes biomécanique subie par le corps d’un athlète. En médecine elle permet d’avoir des visualisations 3d complètes de l’anatomie d’une personne. En architecture d’intérieur elle permet de créer des modèles 3d d’une maison.
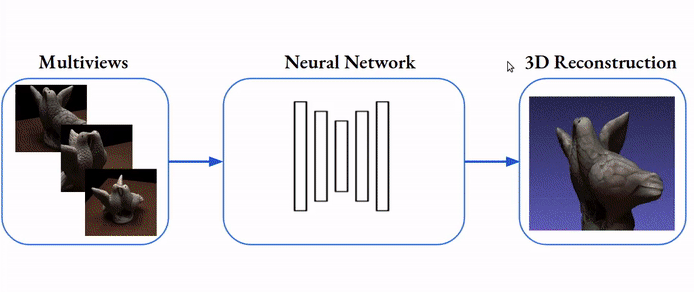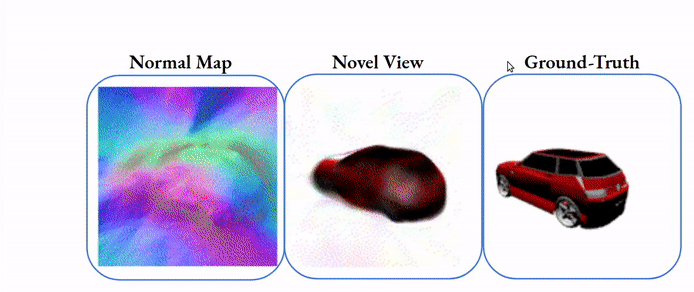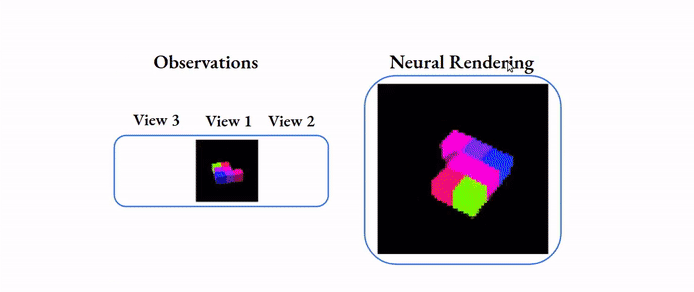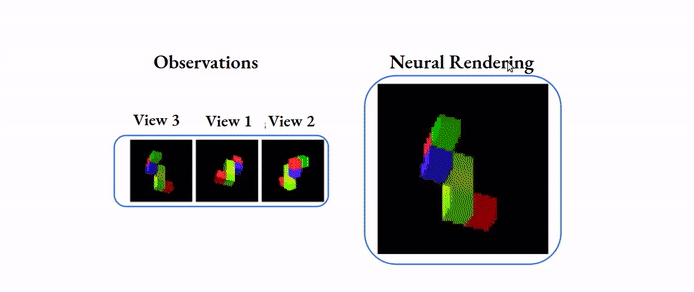
Computer vision pour l’estimation automatique de poses humaines
L’un des sous-domaines de la computer vision les plus à la mode est l’estimation automatique de poses humaines. Cette technique consiste à détecter les personnes présentes dans une image ou une vidéo et extraire leurs postures exactes. Il s’agit de détecter pour chaque personne les positions d’un ensemble de points clés correspondants à des parties du corps.
Les applications de l’estimation de poses humaines vont de l’analyse de performances en sport à la prévention des accidents de travail dans les chantiers. En sport, on peut décortiquer de façon plus fine les gestes effectués par les athlètes, détecter automatiquement des actions ou encore extraire des métriques sur les efforts musculaires fournis. Dans le domaine du BTP on est capable de mieux identifier les gestes à risque effectués par les travailleurs, comme ceux opérés pour soulever des objets lourds.
Le même principe permet de détecter des points clés sur les mains ou sur le visage d’une personne. On peut ainsi prédire automatiquement les sentiments d’une personne sur une photo. C’est aussi sur ce principe que reposent les modèles de traduction du langage des signes.
Même si des applications intéressantes de cette technique émergent, elle reste encore expérimentale. C’est d’ailleurs souvent le cas lorsque l’on veut étudier des images en 2D (à partir d’une seule caméra), on doit se limiter à l’information disponible sur l’image sans prendre en compte les éventuels effets liés à la perspective ou à l’angle de la caméra.
OpenPose est un outil assez intéressant pour l’estimation de poses humaines.

Il existe d’autres techniques de vision par ordinateur que l’on n’a pas mentionnées dans cet article, comme l’OCR par exemple (Opitcal Caracter Recognition).
Même si toutes ces applications sont intéressantes et assez prometteuses, il est important de souligner que les modèles disponibles actuellement ne sont pas toujours très performants, surtout lorsque les données disponibles sont issues d’une caméra unique.
Par ailleurs, l’entraînement d’un modèle robuste est couteux en données et en puissance de calcul. Des techniques comme l’auto ML ou le self-supervised learning permettront sans doute de résoudre partiellement ces problèmes mais restent assez peu utilisées et ne sont pas encore très bien maitrisées.



Laisser un commentaire