
La segmentation d’images est une technique de computer vision qui consiste à découper de façon automatique une image en zones de pixels appartenants à une même classe d’objets. La segmentation d’images a de nombreuses applications, notamment en imagerie médicale.
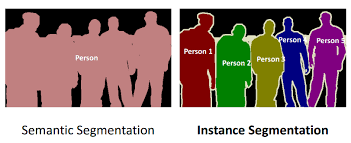
La segmentation d’images se divise en deux types, la segmentation sémantique (semantic segmentation) et la segmentation par instance (instance segmentation).
Dans le cadre de la segmentation sémantique, on cherche à classifier les pixels de l’image comme appartenants ou non à une certaine catégorie. La segmentation par instance en revanche, permet d’avoir plus d’informations sur l’image, en divisant les différentes instances d’un même objet.
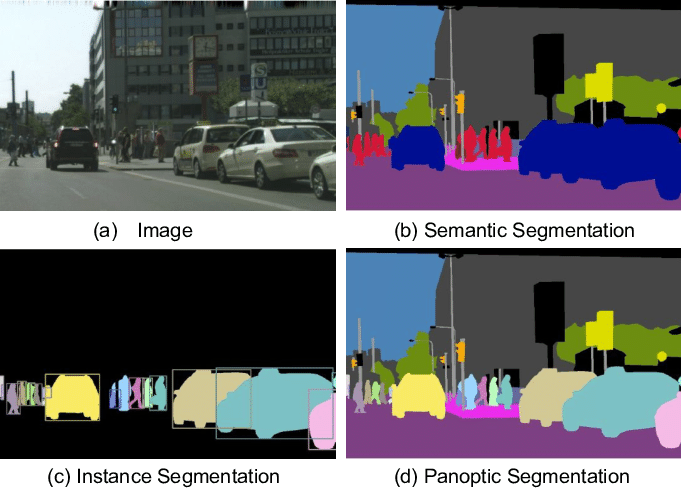
Lorsque l’on souhaite classifier toutes les zones de l’images, en divisant les instances, on parle de segmentation panoptique (panoptic segmentation). Elle consiste en une combinaison des deux types de segmentation.
Dans cet article, on commence par présenter les applications de la segmentation d’images. Et on présente ensuite les différences de fonctionnements de ces 3 types de segmentations.
Quelles sont les applications de la segmentation d’images ?
La segmentation d’image peut être utilisée pour la détection d’objets ou de contours, et permet d’avoir une compréhension plus fine des images et des objets qui la constituent.
Imagerie médicale
L’un des domaines qui utilisent le plus la segmentation d’images est l’imagerie médicale, ou elle permet de découper les images en zones pour compter des cellules, détecter des changements ou des anomalies. Cette supervision des images permet de diagnostiquer des maladies comme le cancer, réaliser des calculs d’âges osseux ou encore donner des scores aux embryons dans le cadre de fécondations in vitro.
Analyse d’images satellitaires
La segmentation d’images est aussi très utilisée pour l’analyse d’images satellitaires. Des modèles de segmentation permettent de détecter les routes, les bâtiments ou les champs.
Une polémique a éclatée ces dernières années concernant l’utilisation des images satellitaires pour détecter les citoyens qui ne déclarent pas leurs piscines. La limitation n’est pas technique ici, un modèle de détection de ce type serait facile à construire, elle est d’ordre juridique et éthique.
Voitures autonomes
La segmentation d’images est de plus en plus intégrées aux caméras embarquées dans les voitures autonomes. Les modèles utilisés dans ce cadre sont assez généralistes et permettent de détecter quasiment tous les objets qu’une voiture pourrait rencontrer sur son chemin (panneaux, piétons, voitures, vélos, animaux, arbres, etc.).
De manière générale, cette technique peut être utilisée à chaque fois que le tracé d’une bounding box (un rectangle) autour de l’objet ne suffit pas, et que l’on a besoin de plus de précision.
Comment fonctionne la segmentation d’image ?
Les méthodes de segmentation d’images ont longtemps reposé sur des techniques de détection de contours classiques. Il s’agit de méthodes mathématiques qui utilisent des opérateurs simples comme la dérivée et le gradient pour détecter les pixels ou un changement brusque d’intensité se produit.
Le modèle détecte ainsi tous les points ou des changements brusques sont repérés, et reconstruit les contours en liant ces points.
Aujourd’hui, de plus en plus de techniques sont proposées et les modèles sont de plus en plus performants. Dans cette partie je présente quelques unes de ces techniques.
Clustering par k-means appliqué à la segmentation d’images
La segmentation d’images est à la base un problème de classification de pixels. Chaque pixel de l’image doit être associé à un ensemble d’autres pixels, que l’on affecte à une classe.
Une des méthodes envisageables pour séparer les pixels en classes est l’utilisation de l’algorithme k-means. Premièrement, on sélectionne un nombre de classes et un ensemble de centres de classes qui correspondent à des pixels sur l’image. Ensuite, une distance entre les centres de classe et chaque pixel de l’image est calculée. Enfin, chacun pixel est affecté à la classe qui minimise la distance entre ce pixel et le centre de la classe.
La distance euclidienne est souvent choisie pour trouver la classe d’un pixel donnée. Pour trouver la distance minimale, il faut passer par des méthodes heuristiques, surtout dans le cas d’images de grandes dimensions.
Découpage en régions et superpixel
Une autre méthode est souvent utilisée pour découper les images en régions, elle repose sur la construction de superpixels. Un superpixel est un assemblage de pixels proches, pour lesquels on a une variance très faible. Les superpixels sont des régions qui ont plus de sens visuellement qu’un pixel isolé.

Un des algorithmes qui permettent de construire ces superpixels est l’algorithme SLIC (Simple Linear Iterative Clustering). Cet algorithme est une variante de la méthode des k-means.
Les pixels sont d’abord encodés sous forme d’un vecteur de taille 5 (pour des images colorées). On a les intensité des différents canaux, R, G et B, et deux valeurs x et y qui correspondent à la position du pixel sur l’image. On doit fixer le nombre de superpixels souhaité, plus il y a de superpixels, moins on perd d’informations. Ce nombre de superpixels va determiner les centres de clusters en les répartissant de façon uniforme sur toute l’image. L’approche basée sur la distance utilisée dans k-means permet ensuite d’affecter chaque pixel à un superpixel.
En pratique, la technique des superpixels est surtout utilisée comme une étape de preprocessing qui permet de réduire la complexité de l’image et simplifier les calculs.
Les réseaux de convolutions (CNN) pour la segmentation d’images
Les récents progrès en deep learning et la démocratisation des réseaux de convolutions ont permis d’améliorer considérablement les techniques de segmentation d’images. Les architectures couramment utilisées sont les mêmes que pour d’autres tâches de vision par ordinateur, comme VGG-16 ou les ResNet.
L’architecture la plus efficace pour la segmentation est mask R-CNN. Elle consiste en 3 réseaux modèles de convolutions indépendants :
- Le premier modèle permet d’extraire des caractéristiques de l’image
- Le second réseau permet de détecter une bounding box (un rectangle) autour de l’instance d’un objet, on parle de region proposal
- Le dernier modèle aura pour but d’affiner la prédiction pour trouver les contours de cet objet de façon plus fine.
Plus récemment, les transformers ont encore améliorer les performances. De manière général, il est clair que les transformers vont constituer la prochaine révolution en vision par ordinateur et en deep learning.
Si vous voulez explorer ce sujet de manière pratique, vous pouvez suivre notre article sur la segmentation d’images avec Python.



Laisser un commentaire