
L’estimation de poses est une technique de computer vision qui permet de détecter la posture d’une personne sur une image ou une vidéo, afin d’en extraire un modèle biomécanique. Cette technique a de nombreuses applications. Elle permet de mieux comprendre les comportements des personnes visibles dans une image et détecter leurs actions.
En sport, elle permet d’analyser plus finement les gestes réalisés par les athlètes. En sécurité, elle peut être utilisée pour détecter des actions suspectes. Son grand avantage est de pouvoir extraire des modèles biomécaniques sans marqueurs.
L’estimation de poses humaines en 2D, à partir d’une seule caméra, est un challenge complexe à résoudre. Il y a une infinité de postures possibles, un nombre indéterminé de personnes sur chaque image et les contacts et chevauchements sont nombreux. Par ailleurs, la morphologie et les vêtements portés par les personnes peuvent avoir un impact sur les prédictions du modèle.
L’estimation de poses humaines est un sujet qui a occupé les chercheurs en computer vision pendant de nombreuses années et plusieurs méthodes ont été proposées.
Modélisations du corps humains
Avant de présenter les différentes approches d’estimation de poses, il convient de définir ce qu’est une pose humaine.
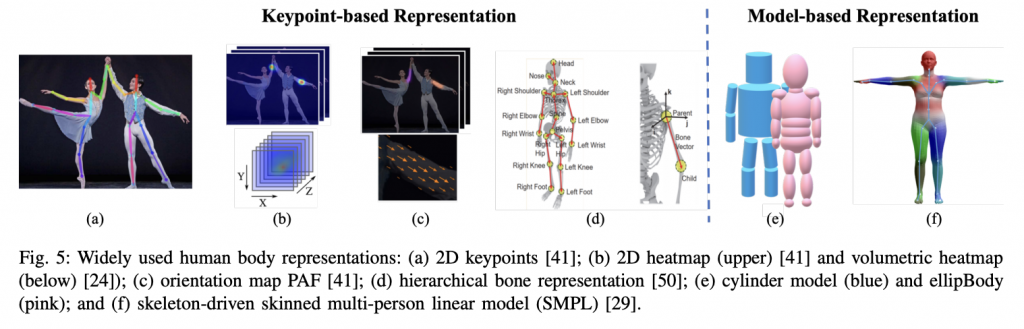
Le corps humain est un objet complexe constitué de 206 os différents, 639 muscles et 360 articulations, avec un grand nombre de degrés de liberté. Plusieurs représentations existent et proposent des modélisations plus ou moins complexes du corps humain.
Ces modèles se divisent en deux catégories. Les représentations dites keypoints-based, qui modélisent le corps sous forme d’un ensemble de points clés qui correspondent à des articulations. Et les représentations model-based. Ceux sont des modèles 3d composés d’un assemblage de formes et permettant d’avoir une description plus riche du corps.
Principe de l’estimation de poses humaines
Single vs multi-person
Dans le cadre de l’estimation de poses il est d’usage de différencier les cas avec plusieurs personnes (multi-person) sur l’image et les cas avec une seule personne (single-person).
Dans un contexte single-person l’architecture du modèle est souvent similaire. Le modèle prend une image en entrée et il est composé de deux parties.
La première partie joue le rôle d’encodeur et va permettre, en utilisant des réseaux de neurones de convolution, d’extraire des caractéristiques sous la forme d’un vecteur. La deuxième partie, qui est un modèle de régression, joue le rôle de décodeur et permet d’estimer la pose de la personne à partir du vecteur de ses caractéristiques.
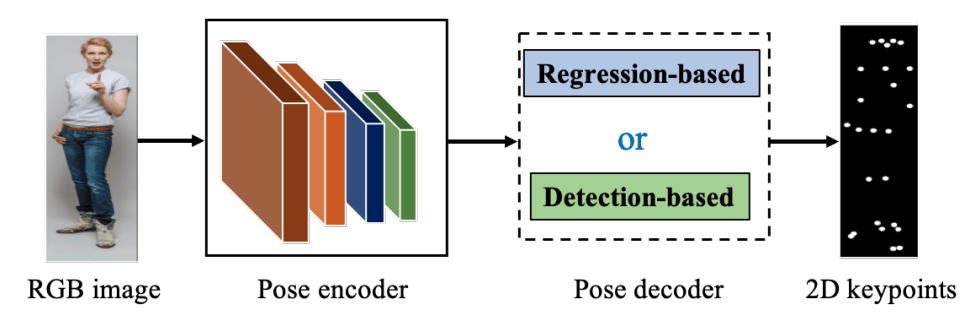
Dans la plupart des solutions proposées, l’encodeur a une architecture de réseau très profond dit réseau de neurones résiduel (ResNet).
Les ResNet ont été conceptualisés pour pouvoir construire des réseaux très complexes en résolvants les problèmes d’évanescence ou d’explosion du gradient.
Ce problème intervient à cause de l’enchaînement des opérations de multiplications des poids qui font tendre le gradient vers 0 (ou l’infini en fonction de si les entrées sont normalisées ou pas) et empêche l’entraînement des couches les plus éloignées.
Pour éviter cela les ResNet contiennent des skip connections qui permettent de faire passer l’information d’un neurone d’une certaine couche vers un neurone d’une couche beaucoup plus éloignée.
Approches descendantes et ascendantes pour l’estimation de poses humaines
Deux approches existent pour l’estimation de poses dans un contexte multi-person (lorsque plusieurs personnes sont présentes à l’image).
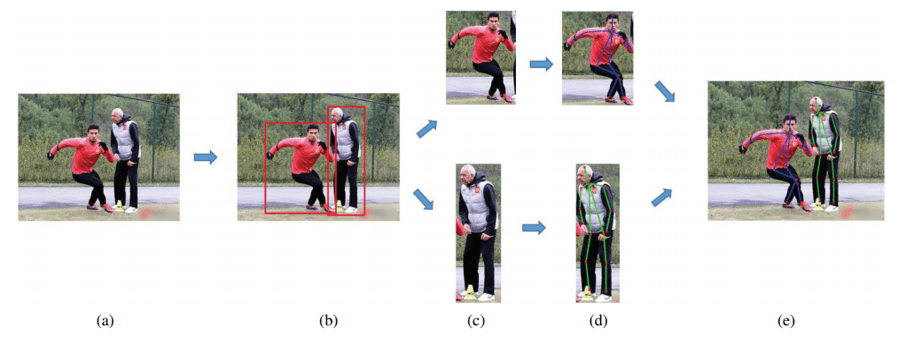
Dans la première approche, dites descendante (top-down), le modèle commence d’abord par détecter et localiser les personnes présentes à l’image, puis extrait la pose pour chaque personne en analysant seulement la partie de l’image dans laquelle cette personne est visible, comme pour une extraction dans un contexte single-person.
Même si l’approche descendante semble assez intuitive, elle présente des défauts notables.
D’abord, l’estimation de la pose dépend beaucoup des performances du modèle de détection, lorsque la détection de la personne échoue, l’estimation de la pose échouera aussi.
Ainsi, dans les scènes ou plusieurs personnes se superposent ou sont proches, cette approche ne sera pas adaptée. Par ailleurs, le temps d’exécution du modèle risque d’être élevé puisque proportionnel au nombre de personnes dans l’image.
La seconde approche est l’approche ascendante (bottom-up). Elle consiste à localiser des articulations du corps humain de façon isolée, puis les assemble en pose à l’aide d’un modèle d’association.
Contrairement à l’approche descendante, l’approche ascendante permet d’avoir des résultats exploitables même dans des situations d’encombrements avec plusieurs personnes qui se superposent. La complexité algorithmique d’un modèle de ce type sera aussi plus faible, les temps d’inférences sont donc meilleurs.
L’outil de référence pour l’estimation de poses humaines est OpenPose. C’est un modèle open-source d’estimation automatique et en temps réel de poses multi-person. Bien qu’il soit développé initialement en C++, OpenPose a une implémentation Python avec Tensorflow et PyTorch.
Les concepteurs du modèle on choisit une approche bottom-up, qui repose donc sur la détection « directe » des parties des corps des personnes présentes sur l’image, sans que le modèle n’ait d’informations préalables ni sur le nombre, ni sur la localisation de ces personnes.

Conclusion
L’estimation de poses humaines à partir d’une caméra unique est un gros défi à résoudre. Les solutions proposées actuellement, bien qu’elles soient déjà exploitables, sont très sensibles à certaines problématiques comme les occlusions ou les problèmes de profondeur.
Des tentatives on été faites pour reconstruire des poses humaines en 3d à partir d’images en 2D mais il est clair que les modèles entraînés ne sont pas utilisables.
Certains outils open source ont été proposés pour faire de l’estimation de poses humaines en temps réel et sur des plateformes plus contraignantes en terme de puissance de calcul. Un exemple de ça est Mediapipe. C’est une boite à outils de plusieurs modèles de vision par ordinateur dont de l’estimation de poses humaines.



Laisser un commentaire