
Meta AI vient de rendre open-source un nouveau modèle de NLP, j’ai nommé No Language Left Behind (NLLB).
Le modèle permet de faire de la traduction entre plus de 200 langues différentes, y compris entre des langues sous-représentées dans le dataset (comme l’Urdu ou l’Asturien).
Le constat de Meta AI, était que la plupart des modèles de NLP sont entrainés sur des gros dataset et donc pour des langues très parlées dans le monde. D’où le nom choisi pour le modèle, pas de langue laissée derrière.
Ce modèle devrait pas mal améliorer les traductions proposées jusqu’ici sur Facebook et Instagram. Mais il a aussi été construit pour améliorer les interactions dans le metaverse imaginé par Meta.
Sur le site de Meta AI vous pouvez trouver des histoires traditionnelles pour enfants, traduites depuis des centaines de langues vers des centaines de langues (mais certaines histoires ne sont pas traduites en français 😅).
Our researchers made a fun storybook demo that uses the latest AI advancements from the No Language Left Behind project to translate stories originally written in languages like Indonesian, Somali, and Burmese into more languages for readers. Check it out: https://t.co/9oe8Ugd5aO pic.twitter.com/4XIbnIk6Jw
— Meta AI (@MetaAI) July 6, 2022
NLLB : Construction automatique du dataset
La construction du dataset pour l’entraînement de ce modèle est faite de façon quasi automatique.
Dans beaucoup de modèle de NLP on associe une phrase dans une certaine langue avec une phrase, dont la signification est identique, dans une autre langue. Et lorsque l’on entraîne le modèle avec des documents, les documents sont structurés de la même façon et avec la même signification.
Avec l’approche de Meta, l’idée est de construire des paires de phrases dans différentes langues même quand les documents sont structurés différemment et n’ont pas le même sujet. Et donc ça permet de construire un dataset conséquent, même pour des langues avec moins de données.
Le modèle qui a permit la construction du dataset, repose sur une approche teacher-student. Le modèle teacher est pré-entraîné pour réaliser une certaine tâche, et on a des méthodes pour permettre au second réseau de neurones, le student, de s’entraîner pour la même tâche.
Entraînement de NLLB-200
Les modèles de traductions de textes sont souvent construits spécifiquement pour une paire de langues. C’est pour cela que si on veut traduire un texte du français au japonais, il est préférable de passer par l’anglais.
Le modèle NLLB a été entrainé une seule fois, pour toutes les langues. Cette approche peut poser des problèmes d’overfitting vu le déséquilibre du dataset.
L’approche utilisée repose sur du Self-supervised learning avec des méthodes de data augmentation faites au préalable.
Evaluation du modèle
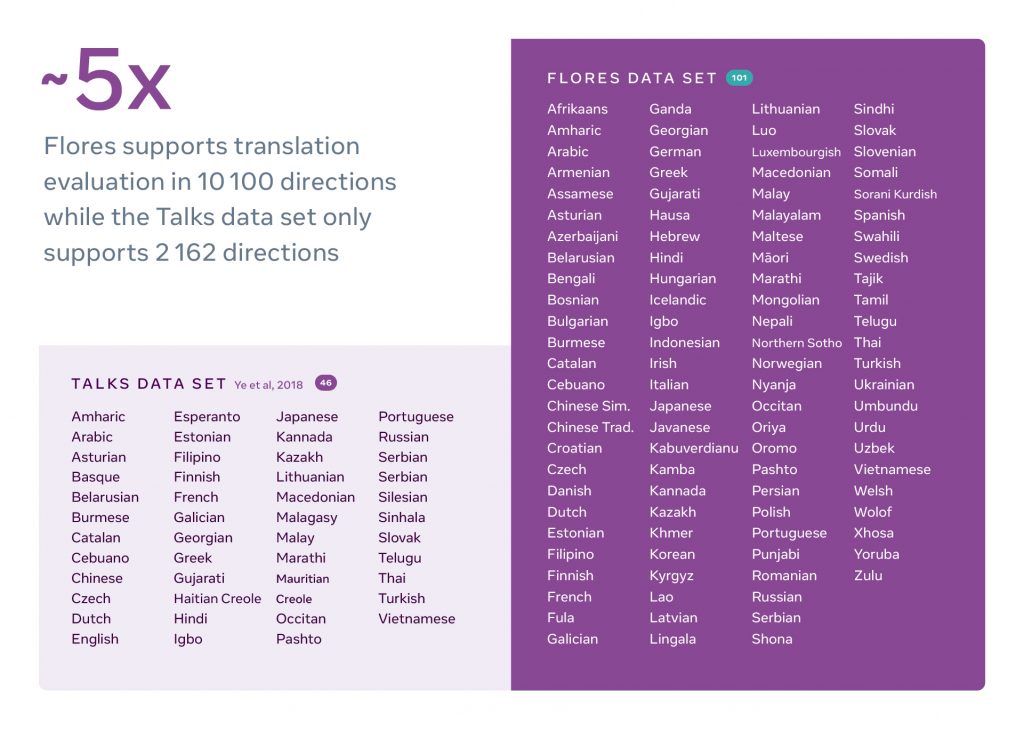
Pour mesurer les performances du modèle, Meta a multiplié par 2, manuellement, la taille de FLORES-101, la référence pour l’évaluation des modèles de traduction.
FLORES-101 avait été proposé par Meta, l’année dernière, et couvrait déjà 101 langues, aujourd’hui il en couvre plus de 200.
Pour aller plus loin
📃Paper: https://bit.ly/3aqnn3X
⚙️Model: https://bit.ly/3afublb
🛤️Benchmark: https://bit.ly/3OPffJr


Laisser un commentaire