
Avec l’essor de la data science et du Machine Learning, les entreprises entraînent des modèles prédictifs par dizaines… mais très peu survivent au-delà du notebook. Dans la pratique, jusqu’à 80 % des modèles d’IA ne passent jamais en production et restent à l’état de prototype, sans aucun impact sur le business.
Ce fossé entre expérimentation et réalité opérationnelle a donné naissance au MLOps : une discipline d’ingénierie qui s’attaque à tout le cycle de vie des systèmes de machine learning, des données brutes jusqu’au monitoring en production.
Inspiré du DevOps, le MLOps vise à automatiser, fiabiliser et accélérer le déploiement et la maintenance des modèles. L’objectif n’est plus seulement de construire des modèles performants… mais de les rendre déployables, observables et maintenables dans la durée.
Pourquoi le MLOps est devenu indispensable ?
Déployer un modèle de machine learning dans un environnement de production est bien plus complexe que de le développer en laboratoire. Avant l’avènement du MLOps, les équipes rencontraient d’importants obstacles :
- Délais très longs de mise en production : Il fallait souvent 6 à 12 mois pour déployer un modèle ML après son développement, freinant lourdement l’innovation.
- Taux d’échec élevé des projets ML : Jusqu’à 80–90 % des projets n’aboutissaient pas, restant bloqués au stade du PoC.
- Reproductibilité et traçabilité insuffisantes : Les équipes peinaient à retracer quelle version de modèle et quels jeux de données étaient utilisés en production, rendant les déploiements opaques.
- Maintenance difficile des modèles : Faute de surveillance et de procédures de rollback adéquates, il était difficile de corriger rapidement un modèle défaillant.
- Dégradation des performances dans le temps : Sans surveillance, la dérive des données (data drift) ou des concepts finissait par rendre les modèles obsolètes ou moins précis.
Ces difficultés s’amplifient à l’échelle industrielle. Pour des entreprises gérant des milliers de modèles ML en production (comme Netflix ou Uber), les méthodes artisanales ne pouvaient tout simplement pas passer à l’échelle ni assurer la fiabilité requise.
La dette technique cachée
L’un des fondements intellectuels du MLOps provient de l’article séminal de Google Hidden Technical Debt in Machine Learning Systems. Il a mis en lumière un concept fondamental : dans un système ML réel, le code ML lui-même ne représente qu’une fraction minime de l’ensemble du système.
Le modèle est encadré par une infrastructure vaste et complexe (collecte de données, extraction de fonctionnalités, gestion des processus, infrastructure de service, surveillance, etc.). Cette infrastructure périphérique est la source majeure de la dette technique.
C’est pour répondre à ces enjeux que le MLOps a émergé. Tout comme le DevOps a rationalisé le développement logiciel, le MLOps offre un cadre robuste pour industrialiser le machine learning, permettant :
- d’automatiser le déploiement des modèles, réduisant les erreurs humaines.
- de gérer efficacement les mises à jour et les versions des modèles.
- de surveiller en continu les performances en production pour détecter rapidement les dérives.
- de garantir la reproductibilité et la traçabilité de chaque expérience et version de modèle.
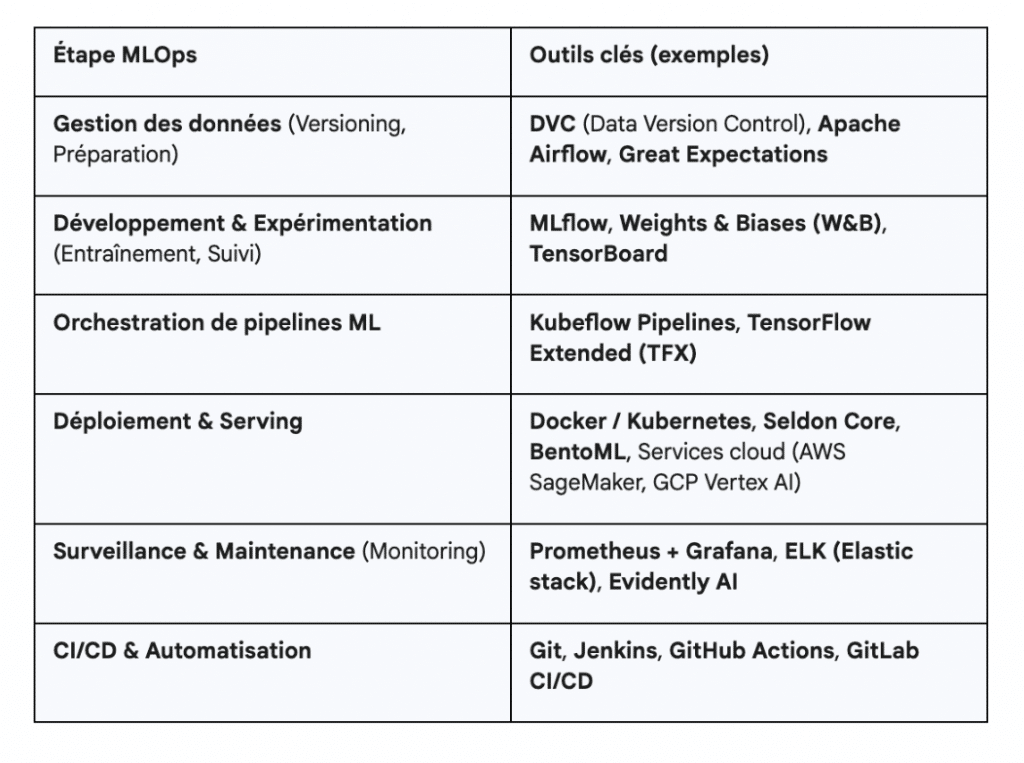
Les composants de base du MLOps
Un projet de machine learning qui vise la production suit un cycle de vie structuré et itératif. Le rôle du MLOps est précisément de transformer ce cycle en un enchaînement fluide, standardisé et automatisé.
À chaque étape, on cherche à réduire l’incertitude, renforcer la reproductibilité et accélérer le passage à la production.
Ingestion et préparation des données
Tout commence par les données. Leur qualité conditionne directement la qualité du modèle final. Dans une démarche MLOps, l’ingestion n’est plus une suite de scripts ponctuels, mais un pipeline automatisé.
Des orchestrateurs comme Apache Airflow ou Kubeflow Pipelines assurent la collecte régulière des données, leur transformation (ETL) et leurs tests de qualité.
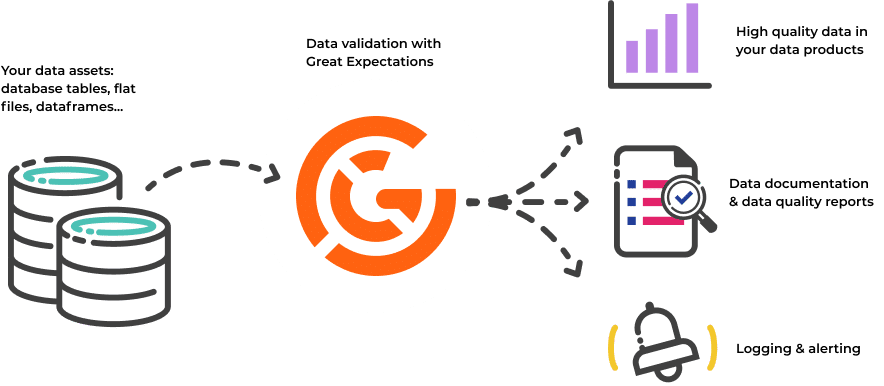
La reproductibilité joue ici un rôle central. Versionner les données, à l’aide d’outils comme DVC (Data Version Control), permet de savoir exactement quel dataset a servi à entraîner un modèle donné. Cela garantit qu’un modèle peut être recréé à l’identique, même plusieurs mois plus tard.
Cette étape inclut également la validation systématique des données grâce à des frameworks tels que Great Expectations, qui détectent les anomalies, incohérences ou ruptures dans les distributions.
Développement et entraînement du modèle
Une fois les données prêtes, on passe à la phase de modélisation. Les data scientists explorent différentes approches, testent des architectures, ajustent les hyperparamètres, puis entraînent plusieurs variantes du modèle.
Pour que cette phase soit productive, l’environnement doit être maîtrisé de bout en bout. C’est ici que la standardisation via Docker et parfois Kubernetes joue un rôle essentiel : l’environnement de développement devient identique à celui qui sera utilisé pour la production.
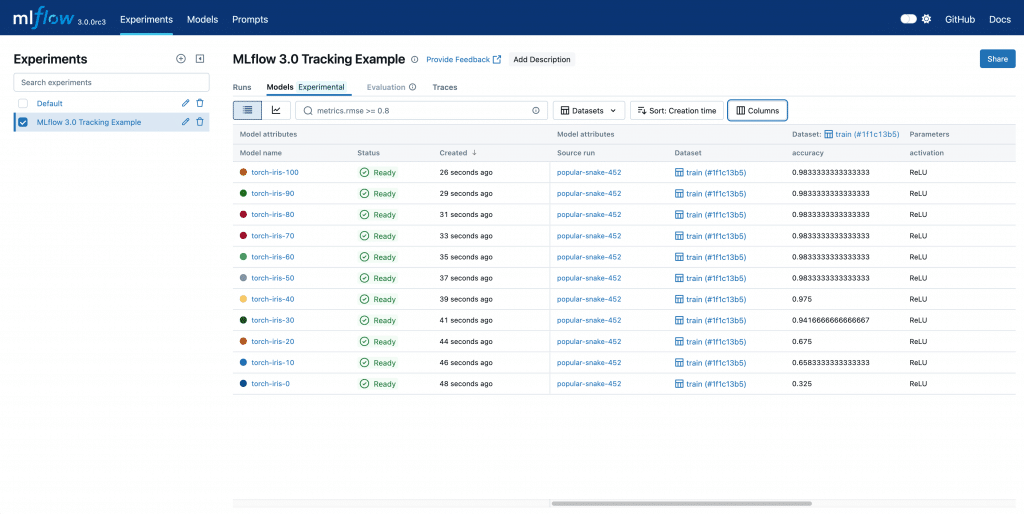
Le suivi des expériences est également une pierre angulaire. Des outils comme MLflow ou Weights & Biases permettent d’enregistrer chaque run, chaque métrique, chaque jeu d’hyperparamètres. Non seulement cela facilite la comparaison entre modèles, mais cela centralise aussi la gestion des modèles entraînés dans un registre unique.
Enfin, les pipelines d’entraînement peuvent intégrer des stratégies d’optimisation (recherche automatisée d’hyperparamètres), ce qui permet d’améliorer les performances de manière systématique et mesurable.
Validation et tests du modèle
Avant tout déploiement, un modèle doit prouver qu’il est fiable. L’évaluation classique sur un jeu de test indépendant mesure sa capacité à généraliser, mais cela ne suffit pas pour un passage en production.
Le MLOps introduit une phase structurée de tests supplémentaires : on ajoute des tests de robustesse face aux données bruitées, tests de biais pour vérifier l’équité, tests de performance pour valider les seuils minimums exigés par le métier.
Vient ensuite la validation d’intégration. Le modèle est déployé en environnement de staging pour vérifier sa latence, sa consommation mémoire, sa capacité à gérer de vrais flux de données.
Cette étape permet d’anticiper les comportements inattendus en conditions réelles et d’éviter les mauvaises surprises une fois en production.
Déploiement du modèle en production
Le déploiement devient une extension naturelle du pipeline de développement. Le modèle, accompagné de toutes ses dépendances, est packagé dans un conteneur Docker, ce qui garantit sa portabilité.
Des pipelines d’intégration et de déploiement continus (CI/CD), gérés via GitHub, GitLab CI ou Jenkins, orchestrent la promotion automatique des modèles : d’abord en test, puis en staging, et enfin en production.
Pour exécuter ces modèles à grande échelle, les organisations s’appuient généralement sur Kubernetes, couplé à des frameworks de serving comme Seldon Core ou BentoML.
Ces outils gèrent la mise à l’échelle automatique, la tolérance aux pannes et l’exposition des modèles sous forme de microservices.
Surveillance du modèle en production
Une fois le modèle en place, le travail ne fait que commencer. En production, un modèle est confronté à des données nouvelles et changeantes, ce qui peut entraîner une dégradation progressive de ses performances.
Le monitoring MLOps surveille simultanément deux dimensions : la santé technique du système (latence, temps de réponse, erreurs) et la qualité prédictive (précision, F1-score, stabilité des prédictions).
Un point critique est la détection de dérive du modèle (drift). Le data drift signale que les données d’entrée ne ressemblent plus à celles du training.
Le concept drift, plus insidieux, indique que la relation entre les variables d’entrée et la cible a changé. Pour analyser cela, les équipes utilisent des outils comme Prometheus, Grafana, ELK, et des solutions spécialisées telles qu’Evidently AI.
Cette surveillance permet de détecter rapidement les défaillances, avant qu’elles n’impactent l’utilisateur final ou les résultats métiers.
Maintenance et réentraînement continus
Le MLOps instaure enfin une boucle d’amélioration continue. Un modèle ne doit pas seulement être mis en production, il doit y rester performant.
Les organisations programment souvent un réentraînement périodique (hebdomadaire, mensuel) ou déclenché par des événements (découverte d’une dérive, chute de performance, modification de la politique métier).
Chaque nouvelle version du modèle est comparée à l’ancienne, puis déployée progressivement grâce à des A/B tests. Lorsque les performances se stabilisent, la nouvelle version prend progressivement le relais.
Ce processus s’accompagne d’une gouvernance rigoureuse : versionnage systématique, archivage des modèles obsolètes, documentation, traçabilité garantissant la conformité réglementaire.
Conclusion
Le MLOps s’est imposé comme un pilier essentiel pour réussir l’industrialisation du Machine Learning. En apportant des méthodes structurées, de l’automatisation et des bonnes pratiques DevOps au monde des modèles prédictifs, il permet de combler le fossé entre le laboratoire et la production.
Adopter le MLOps, c’est investir dans la fiabilité et l’évolutivité des systèmes d’IA de l’entreprise. Les bénéfices se traduisent par des itérations plus rapides, des modèles qui délivrent effectivement de la valeur métier en continu, et une réduction des erreurs en production.
Les data scientists gagnent du temps (moins de tâches manuelles), les équipes IT disposent d’un cadre clair pour opérer les modèles à l’échelle, et l’entreprise s’assure que ses modèles restent performants et pertinents sur la durée.
Et cette discipline devient plus importante que jamais. Avec l’essor des grands modèles de langage (LLM) et des systèmes augmentés par la récupération (RAG), une nouvelle branche émerge : le LLMOps.
Elle applique les mêmes principes que le MLOps, mais à des modèles beaucoup plus volumineux, plus coûteux à évaluer et soumis à des dynamiques différentes (gestion du prompt, évaluation subjective, monitoring sémantique, dérive comportementale, etc.).


Laisser un commentaire