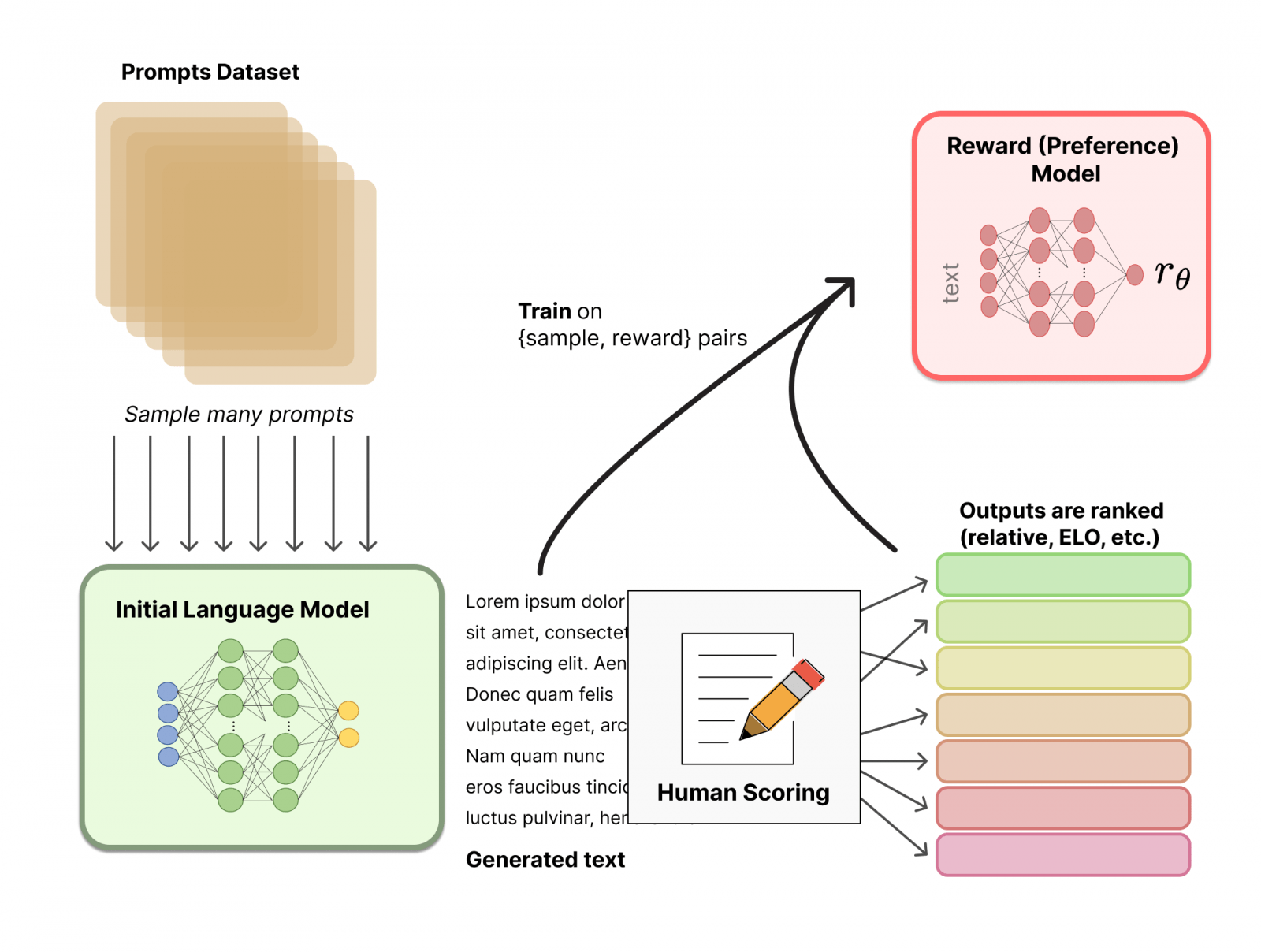
Le RLHF (Reinforcement Learning from human feedback) est une approche d’apprentissage par renforcement qui utilise les commentaires et les évaluations des humains pour guider l’apprentissage d’un modèle d’intelligence artificielle.
Contrairement à l’apprentissage par renforcement traditionnel, où l’agent doit apprendre à partir de récompenses ou de pénalités pour ses actions, dans le RLHF, l’agent reçoit des commentaires des humains sur la qualité de ses actions.
Ces commentaires peuvent être sous forme de réponses binaires (comme « bon » ou « mauvais ») ou de notes sur une échelle (comme une note de 1 à 5).
Le RLHF peut être utile dans les situations où la définition de récompenses pour l’agent intelligent est difficile ou impraticable.
Cet article à pour objectif de fournir une compréhension approfondie du RLHF pour les lecteurs qui souhaitent en apprendre davantage sur cette méthode d’apprentissage par renforcement novatrice.
Rappel sur le Reinforcement Learning
Avant de définir ce qu’est le RLHF et comment il fonctionne, commençons par rappeler le principe du reinforcement learning.
Le reinforcement learning, ou apprentissage par renforcement, est une méthode d’apprentissage automatique dans laquelle un agent apprend à prendre des décisions en interagissant avec un environnement et en recevant des récompenses ou des punitions en fonction de ses actions.
L’objectif de l’agent est de maximiser la somme des récompenses qu’il reçoit au fil du temps.
L’agent va alterner entre phase d’exploration et phase d’exploitation.
Pendant les phases d’exploration il va entreprendre de nouvelles choses pour rechercher les actions avec fortes récompenses.
Pendant les phases d’exploitation, il va refaire des actions qu’ils lui ont permis de gagner des récompenses par le passée.
Ce comportement est modélisé mathématiquement par une fonction de gain qui augmente ou diminue en fonction des décision de l’agent.
Et cette fonction de gain est souvent facile à calculer puisqu’elle est liée à un environnement concret : temps passé par un utilisateur sur son feed, argent remporté, score dans un jeu vidéo, résultat d’une partie d’échec, etc.
Qu’est-ce que le RLHF ?
Le RLHF est une extension du reinforcement learning qui permet à un agent de prendre des décisions en se basant sur les commentaires des humains plutôt que sur des récompenses objectives.
Cette approche est très utile dans les situations où les règles du jeu sont difficiles à définir et ou les récompenses sont subjectives.
Le RLHF est donc une méthode d’apprentissage par renforcement qui peut aider les agents à s’adapter à des environnements complexes en se basant sur les connaissances humaines.
Cette méthode existe depuis plusieurs années, mais elle a été mise en lumière par OpenAI à travers le modèle de langage ChatGPT.
Elle est très simple à mettre oeuvre, il s’agit de demander à un opérateur humain de classer des sorties proposées par un modèle d’intelligence artificielle par ordre de pertinence.
En collectant un grand nombre de feedbacks et en utilisant des systèmes de ranking comme ELO, on peut considérablement améliorer les performances des modèles entraînés.
Le RLHF est une extension très pertinente de l’apprentissage par renforcement traditionnel :
- Il permet d’intégrer des connaissances humaines et des préférences subjectives dans le processus d’apprentissage. Cela peut conduire à des modèles plus alignés avec les valeurs humaines et à une meilleure performance dans des tâches complexes.
- Il est particulièrement utile dans les situations où la définition de récompenses objectives est difficile ou impossible, comme dans le traitement du langage naturel ou les tâches impliquant des valeurs humaines.
- Le RLHF peut également améliorer la robustesse et l’exploration des agents, en les aidant à mieux naviguer dans des environnements complexes et incertains.
Quelles sont les applications du RLHF ?
Même si c’est une technique récente, le RLHF a été appliqué avec succès pour divers problématiques.
Dans le traitement du langage naturel, par exemple, il a été utilisé pour améliorer les performances des modèles de langage dans des domaines tels que les agents conversationnels, la résumé automatique de texte et la compréhension du langage naturel.
Dans le domaine des jeux vidéo, le RLHF a été employé pour développer des agents intelligents capables de jouer à des jeux vidéo en s’appuyant sur les préférences humaines pour déterminer les meilleures stratégies.
Cela a permis d’améliorer la performance des agents dans les jeux et de les rendre plus adaptés aux préférences des joueurs.
Enfin, le RLHF peut aussi être appliqué dans des contextes tels que la robotique, la prise de décision en entreprise et la médecine personnalisée.
Dans ces domaines, le RLHF permet d’intégrer des connaissances humaines et des préférences subjectives pour guider l’apprentissage des agents intelligents, ce qui peut conduire à des solutions plus adaptées et performantes.
Conclusion
le RLHF est une méthode d’apprentissage par renforcement novatrice qui tire parti des retours humains pour guider l’apprentissage des agents intelligents.
Il offre des avantages significatifs dans les situations où les récompenses objectives sont difficiles à définir, et il a été appliqué avec succès à divers domaines, notamment le traitement du langage naturel et les jeux vidéo.
Les recherches futures pourraient explorer davantage les possibilités offertes par le RLHF et son potentiel pour améliorer encore les performances des agents intelligents dans des environnements complexes.



Laisser un commentaire