
Kaggle est une plateforme sur internet regroupant un certain nombre de compétitions dans le domaine de la data science. Les entreprises publient des données et un défi en lien avec ces données. Un classement des réalisations est fait par la plateforme et cela permet souvent au meilleur de gagner beaucoup d’argent. Les compétitions sont de niveaux différents et permettent de bien se former au machine learning. J’espère que ce tutoriel kaggle vous plaira 🙂

J’ai décidé de lancer une série de tutoriels pour vous montrer ce que l’on peut faire avec le machine learning, à travers différents problèmes tirés de ce site.
Le premier problème est un passage presque obligé pour tout Kaggler qui se respecte ! Il s’agit de « Titanic : Machine learning from disaster ».
Prise en main du site
Une fois sur le site, vous devrez créer un compte à votre nom. Dans votre profil vous pouvez consulter les dernières réalisations des autres membres sur les différents problèmes. L’interface est très intuitive et facile à utiliser. Pour commencer, rendez-vous dans la section ‘’Competitions’’ de la barre d’accueil. Vous trouverez une grande liste de problèmes à résoudre, certains permettent de gagner des prix (pouvant aller jusqu’à des centaines de milliers de dollars). Vous trouverez aussi beaucoup de problèmes éducatifs, comme celui que nous allons réaliser aujourd’hui.
Premier problème : prédire si un passager du Titanic a survécu ou non
Une fois que vous êtes dans la page qui recensent toutes les compétitions, cliquez sur ‘’Titanic : Machine Learning from Disaster’’. C’est sur ce problème que nous allons travailler pour commencer. Il permet de se familiariser avec la plateforme et permettra à certains d’entre vous d’écrire leur premier algorithme de machine learning.
Ce premier problème permet de se familiariser avec la plateforme Kaggle. L’objectif de cet exercice est de prédire si un passager du Titanic a pu survivre ou non connaissant certaines données sur ce passager : nom, âge, classe, sexe, etc..
La première chose que vous devrez faire sera de rejoindre la compétions : cliquez sur le bouton Join Competition.Vous pouvez commencer par lire la présentation dans l’onglet ‘’Overview’’. L’onglet ‘’Data’’ vous permet d’avoir une aperçue des données fournies. Il nous est fourni pour ce défi trois fichiers en format csv. Le premier fichier, gender_submission.csv, est un exemple de ce à quoi vos résultats devront ressembler. Le second fichier, test.csv, est le fichier qui nous permettra de tester notre algorithme.
Le dernier fichier, train.csv, est celui qui contient les données d’entrainement de notre modèle, il recense plusieurs données sur les passagers et indique pour chacun d’entre eux s’il a survécu ou non.La variable survived vaut 1 pour les passagers qui ont survécus, 0 pour ceux qui n’ont pas survécus.
Une fonctionnalité intéressante de Kaggle, est que vous pouvez coder directement sur la plateforme. Vous n’avez qu’à vous rendre dans la section Notebook. Vous pouvez commencer à coder. Un processeur GPU est mis à votre disposition, et il est au moins aussi performant que celui de Google Colab.
Résolution du premier problème Kaggle
Pour résoudre ce problème, je vous propose d’utiliser l’algorithme random forest, ce n’est pas la meilleure approche de résolution mais c’est la plus simple lorsqu’on débute.
Tout comme Google Colab, Kaggle vous propose une plateforme pour coder et tester vos modèles directement en ligne. C’est une fonctionnalité très intéressante puisqu’elle vous permet d’utiliser la puissance d’un GPU sans forcement avoir le hardware qui correspond. C’est l’idéal lorsque vous débutez en deep learning.
Dans un premier temps, il faut importer les bibliothèques Numpy et Pandas. Numpy est la bibliothèque de Python qui permet de faire de l’algèbre linéaire. Pandas est très pratique pour importer et analyser des données. Au début de votre Notebook, insérez les lignes de codes suivantes
import numpy as np
import pandas as pdLes fichiers csv fournies par Kaggle sont disponible dans le dossier ‘’/kaggle/input/…’’, vous pouvez les importer et en afficher un extrait avec les lignes suivantes :
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
Pandas permet le traitement de grands tableaux de données très facilement. La commande pd.read_csv permet d’importer des fichiers de types csv et de les convertir au format dataframe qui est particulièrement adapté au traitement de données.
La commande .head() permet d’avoir un aperçu des 5 premières lignes du tableau. Cela permet par exemple de vérifier que l’import de votre table c’est bien déroulé.
On peut déjà étudier quelques paramètres sur nos données. Les lignes suivantes permettent d’afficher le pourcentage de femmes et d’hommes qui ont survécus. On peut voir grâce à ces résultats que le sexe de la personne est une caractéristique importante pour déterminer si une personne a survécu ou non.
femme = train_data.loc[train_data.Sex == 'female']['Survived']
ratio_femme = sum(femme)/len(femme)
print('% de femmes qui ont survécus :', ratio_femme)
homme = train_data.loc[train_data.Sex == 'male']['Survived']
ratio_homme = sum(homme)/len(homme)
print('% de femmes qui ont survécus :', ratio_homme)La première ligne permet de créer une liste avec un 1 si une personne a survécu, un 0 sinon.
La commande sum(femme) calcule le nombre de femmes qui ont survécus (le nombre de 1 dans le tableau), len(femme) est le nombre total de femme. D’où le calcul pour la ratio.
Les résultats montrent qu’à priori si le passager est un homme sa probabilité d’avoir succombé dans l’accident est plus élevée. Ce résultats est d’autant plus fiable que les données sont assez équilibrées.
En data science il est important de garder un regard critique vis à vis de vos résultats. Il est facile de tomber dans des pièges comme l’overfitting. C’est pour cela par exemple que l’on aime créer des modèles explicables pour s’assurer que tout se fait correctement.
D’ailleurs l’un des avantages de random forest, le modèle que nous allons implémenter, est qu’il est parfaitement explicable contrairement aux réseaux de neurones. Il y a donc un dilemme entre explicabilité et précision. Dans notre cas, lorsque les variables sont majoritairement catégorielles, il n’y a pas vraiment de dilemme puisque les algorithmes avec des arbres de décisions sont beaucoup plus performants.
À présent, nous devons construire le modèle à proprement parler. Nous allons utiliser un algorithme de type random forest. L’image ci-dessous permet de comprendre le fonctionnement de l’algorithme :
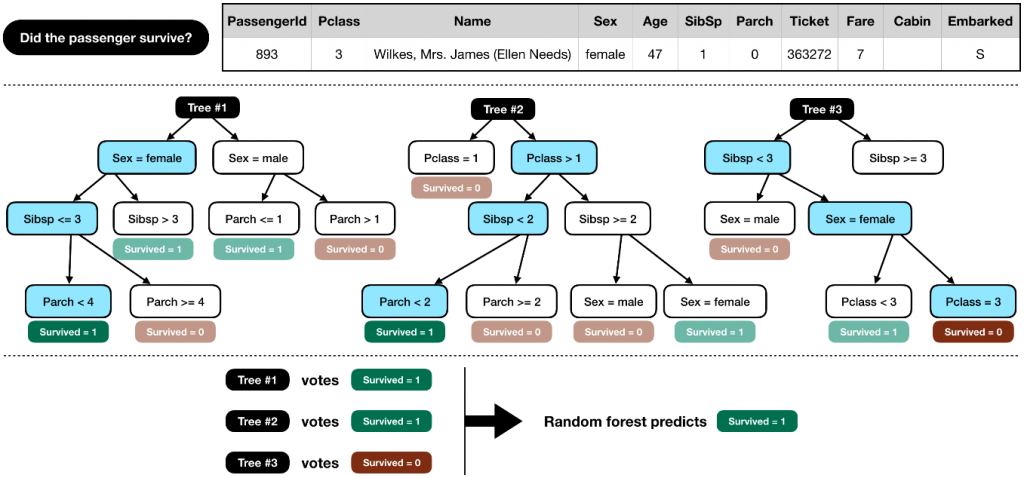
Les arbres représentés, sont ce que l’on appelle des arbres binaires de décisions. À chaque nœud de l’arbre on doit aller à droite ou à gauche suivant les caractéristique de l’individu en question. Sur cette image, uniquement 3 arbres sont représentés, dans notre code nous allons le faire pour 100 arbres.
On récupère les résultats pour chaque arbre (Survived=1 ou Survived=0) puis on fait notre prédiction de façon démocratique pour chacune des deux options. Si plus de 51 arbres sur les 100 au total prédisent Survived, notre prédiction sera de dire que le passager a survécu.
Le code qui correspond à ce programme est le suivant. Pas de panique si vous n’y comprenez rien pour le moment, vous n’avez peut-être pas encore lu notre article sur random forest.
from sklearn.ensemble import RandomForestClassifier
y = train_data['Survived']
features = ['Pclass','Sex','SibSp','Parch']
X_train = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimator=100, max_depth=5, random_state = 1)
model.fit(X_train, y)
predictions = model.predict(X_test)
output = pd.DataFrame({'PassengerId : test_data.PassengerId, 'Survived': prediction})
print(output.head())Voilà ! C’est seulement ça un algorithme de machine learning, rien de bien compliqué 😉.
On commence par importer RandomForestClassifier depuis ScikitLearn. ScikitLearn est une des bibliothèques de références pour le machine learning. Beaucoup d’algorithmes sont déjà implémentés et très bien optimisés pour que vous n’ayez pas à les réecrire.
On enregistre les données sur la survie ou non d’une personne dans la variable y. Puis on crée X et X_test à partir de nos données en utilisant un encodage One Hot. Cela permet de traiter toutes les données comme étant des données numériques.
Nous créons ensuite nos arbres dans ‘model’. Comme je vous l’ai expliqué plus haut on crée 100 arbres. Leur profondeur maximale est de 5 puisque l’on considère 4 features.
C’est ensuite dans model.fit() que tous se joue. C’est là que notre modèle paramètre l’arbre pour que les résultats collent du mieux possible avec nos données d’entrainement.
Une fois le modèle calibré, les deux dernières lignes permettent de fournir nos prévisions sur la survie ou non des passagers.
Une fois que vous avez fait tous ça, vous n’avez plus qu’à soumettre votre travail en cliquant sur le bouton Commit en haut à droite. Avec la méthode proposée, nous avons un taux de réussite de 77,5%. Certaines techniques existent pour améliorer ce score et il y a des algorithmes mieux adaptés comme ceux utilisant des réseaux de neurones.
Sur Kaggle vous verrez que la compétition est rude pour savoir qui aura le meilleur score de prédiction. Certains sont très bons et arrivent à des scores quasi parfait. Néanmoins, cette compétition est parfois un peu inutile.
Dans la majorité des cas notre modélisation des problèmes induit des erreurs assez élevées, ce qui fait qu’un modèle de machine learning n’est de toute façon jamais parfait.

Laisser un commentaire