
Le Topic Modeling est une des techniques de NLP les plus connues. C’est une méthode qui repose sur de l’apprentissage non supervisée, et dont l’objectif est d’extraire les sujets principaux, représentés par un ensemble de mots, qui apparaissent dans une collection de documents.
Un des modèles les plus utilisés actuellement est celui du Latent Dirichlet Allocation (LDA) qui est une généralisation du Probabilistic Latent Semantic Analysis (PLSA).
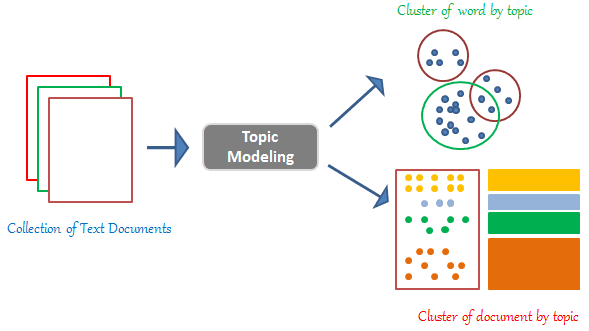
C’est quoi le LDA (Latent Dirichlet Allocation) ?
Le modèle Latent Dirichlet Allocation suppose que chaque document est un mélange d’un petit nombre de topics, et que chaque occurrence d’un mot correspond à l’un des sujets du document. En réalité, chaque mot se voit attribuer un topic selon la loi de Dirichlet.
On obtient donc un premier topic model. Pour générer le suivant, on prend chaque mot et on met à jour le topic auquel il est associé. Ce nouveau thème est celui qui aurait la plus forte probabilité de le générer dans ce document.
Le Latent Dirichlet Allocation n’est pas un algorithme à itération unique. A la première itération, l’algorithme attribue au hasard des mots aux topics. Il passe ensuite en revue chaque mot de chaque document et applique des formules de calcul de probabilité.
Le processus est ensuite répété à travers diverses itérations jusqu’à ce que l’algorithme génère un ensemble de topics et qu’on obtiennent un modèle satisfaisant.
Maintenant que vous savez un peu plus ce dont il s’agit, c’est le moment d’essayer d’appliquer tout ça !
Importation des librairies nécessaires
Pour pouvoir appliquer tout ça on va utiliser les libraires Nltk et Gensim.
On commence par l’import :
!pip install nltk
!pip install gensimimport pandas as pdimport gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from gensim.models import CoherenceModelimport nltk
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from nltk.stem.porter import *
nltk.download('wordnet')
nltk.download('omw-1.4')Préparation des données
On commence tout d’abord par réaliser certaines opérations sur nos données.
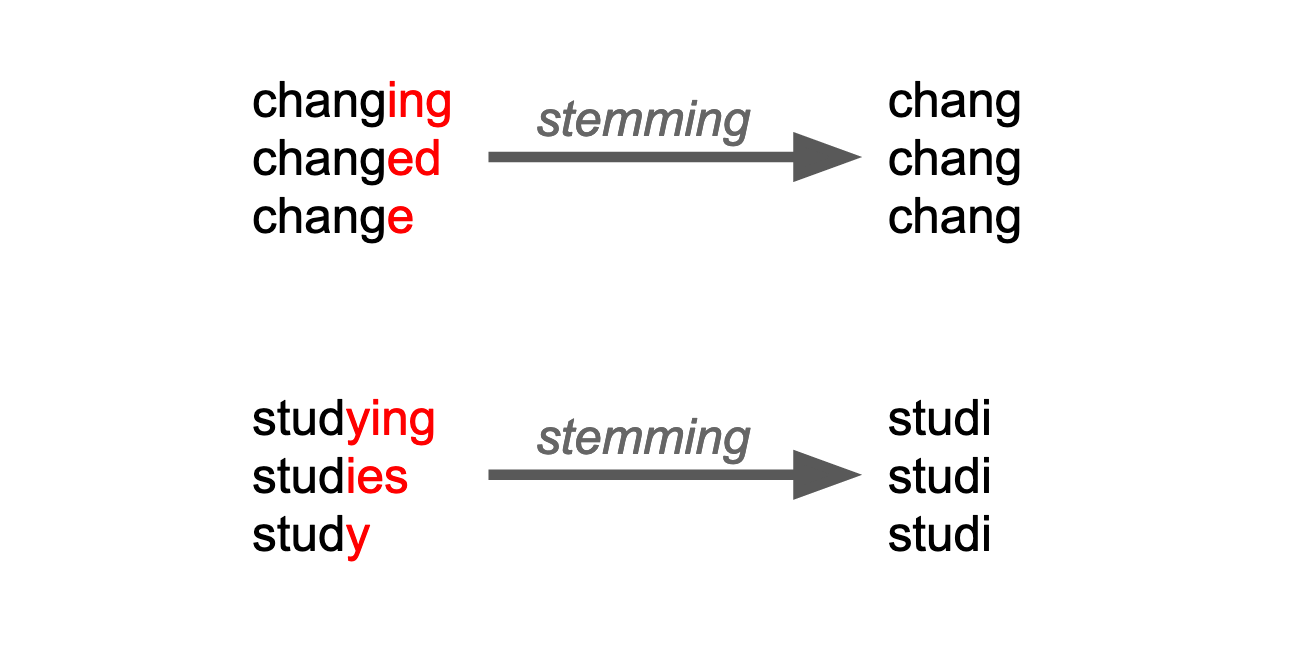
Notamment la suppression des stopwords (the, or, and…) et des mots de moins de 3 lettres, puis la lemmatisation (l’opération de mettre les mots sous leur forme canonique) après avoir supprimé les valeurs nulles ou manquantes.
L’opération la plus importante est la racinisation (stemming) en anglais qui consiste à transformer les mots en forme radicale c’est ce que fait la fonction SnowballStemmer de Nltk.
stemmer = SnowballStemmer('english')def lemmatize_stemming(text) :
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='n'))def preprocess(text) :
result = []
for token in gensim.utils.simple_preprocess(text) :
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3 :
result.append(lemmatize_stemming(token))
return resultprocessed_docs = [preprocess(doc) for doc in data]
Conversion des données
On stocke nos données après leur nettoyage dans un dictionnaire de gensim, pour ensuite les convertir au format Bag Of Words. C’est-à-dire en couple mot/nombre d’occurrences, où la clé est représentée par le mot et la valeur par son nombre d’occurrences.
dictionary = gensim.corpora.Dictionary(processed_docs)dictionary.filter_extremes(no_below=15, no_above=0.1, keep_n=1000)bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
Exécution du LDA
On applique le topic modeling à l’aide de la fonction LdaMulticore de gensim en prenant bien soin de préciser le nombre de topic à extraire du corpus, le mapping entre les identifiants des mots (entiers) et les mots (chaîne de caractères) et le nombre à effectuer d’itération dans le corpus.
Le nombre de topic à extraire constitue une variable importante du modèle, son choix est souvent cruciale tout comme celui du nombres de classes en clustering par exemple.
lda_model = gensim.models.LdaMulticore(bow_corpus, num_topics = 10, id2word = dictionary, passes = 1000)
topics = []
for idx, topic in lda_model.print_topics(-1) :
print("Topic: {} -> Words: {}".format(idx, topic))
topics.append(topic)Cohérence du modèle
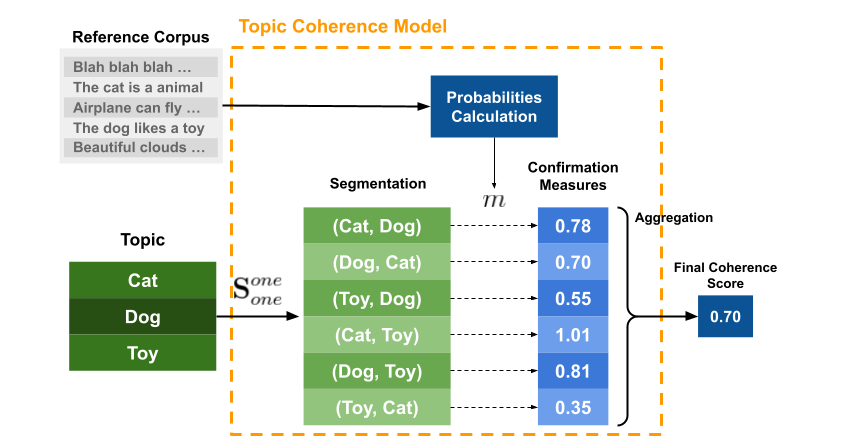
Les mesures de cohérence évaluent le degré de similitude sémantique entre les mots les mieux notés dans le topics. Ces mesures aident à faire la distinction entre les topics sémantiquement interprétables et les topics dû à des inférences statistiques.
Pour un bon modèle LDA la cohérence doit être comprise entre 0.4 et 0.7 au-delà et en dessous le modèle est très probablement erroné. La cohérence pour un modèle LDA est calculée en procédant aux étapes suivantes :
- Segmentation : création de paires de mots à partir de sous-ensembles ;
- Calcul des probabilités : calcul probabilité d’occurrence d’un mot ;
- Mesure de confirmation : vérification « dans quelle mesure » un sous-ensemble de mots supporte un autre sous-ensemble de mots dans chaque paire ;
- Agrégation : agrégation de toutes les valeurs calculées à l’étape précédente en une seule valeur qui est notre score final de cohérence de sujet.
Pour ce faire on utilise la fonction CoherenceModel comme suit :
coherence_model_lda = CoherenceModel(model=lda_model, texts=processed_docs, dictionary=dictionary)
coherence_lda = coherence_model_lda.get_coherence()
print('Coherence Score: ', coherence_lda)PS : dans le cas échéant on ne fait que 100 passages sur notre data set pour établir le topic model, si l’on souhaite avoir un meilleur score de cohérence il suffit d’augmenter le nombre de passages, à partir de 10000 passages on devrait avoir un score très proche de 70% et donc plutôt satisfaisant.
Stockage des résultats
Afin de garder nos résultats dans un Data Frame Pandas on va utiliser le code suivant :
all_topic_model = []
for i in range(len(topics)):
str = topics[i].split(' + ')
topic_model = []
for j in range(10):
weight = str[j][0:5]
word = str[j][7:len(str[j])-1]
topic_model.append((weight, word))
all_topic_model.append(topic_model)df_topic_model = pd.DataFrame(all_topic_model)
df_topic_model.rename(index = {0: "Topic 1", 1: "Topic 2", 2: "Topic 3", 3: "Topic 4", 4: "Topic 5", 5: "Topic 6", 6: "Topic 7", 7: "Topic 8", 8: "Topic 9", 9: "Topic 10"})Visualisation des résultats
On peut également utiliser pyLDAvis pour visualiser les topics de manière interactive directement sur notre Notebook Python :
!pip install pyLDAvisimport pyLDAvis.gensim_modelspyLDAvis.enable_notebook()
pyLDAvis.gensim_models.prepare(lda_model, bow_corpus, dictionary)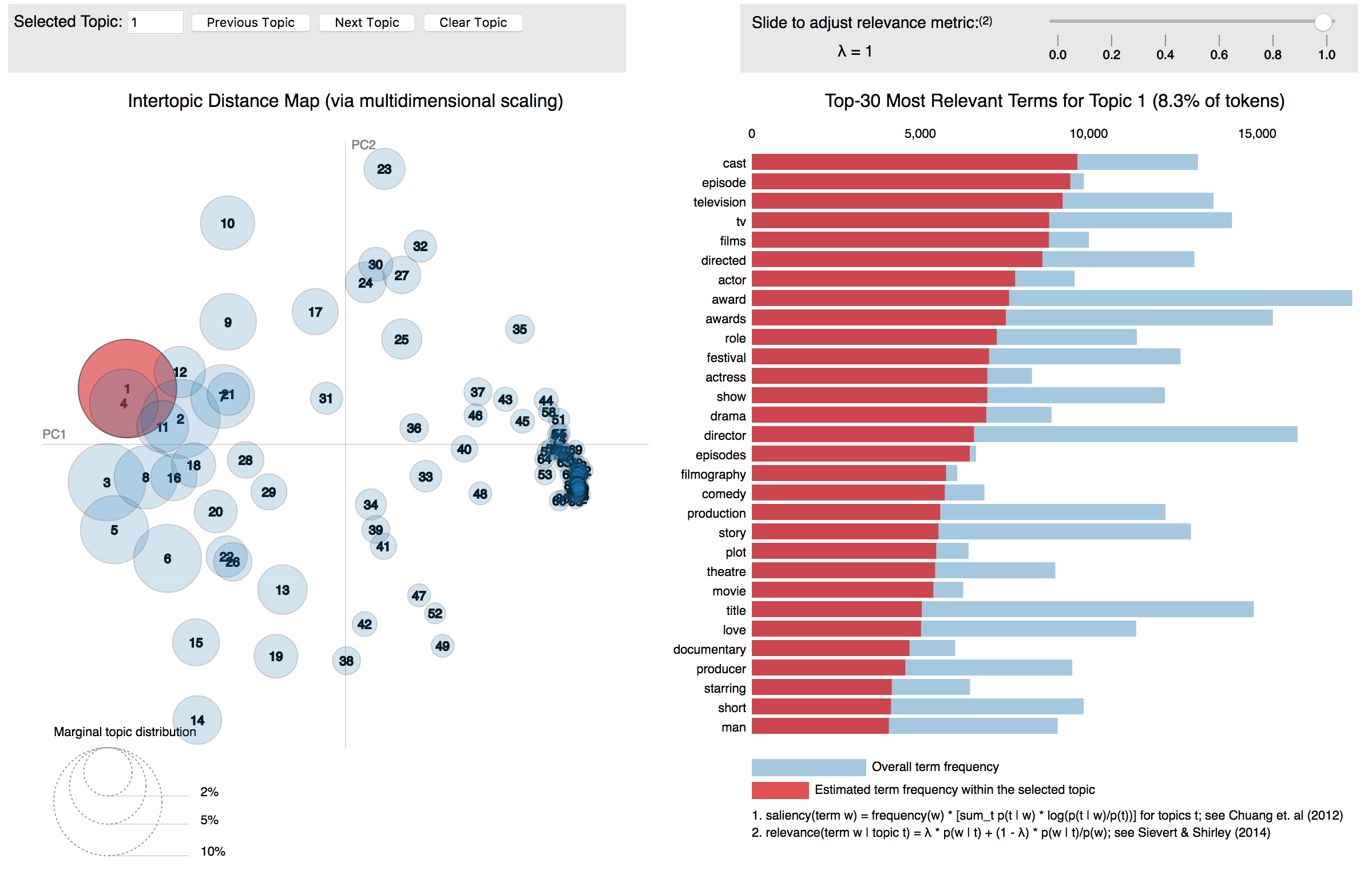
Conclusion
Maintenant que vous êtes un peu plus familiers avec le Topic Modeling en Python vous pouvez explorer toutes les possibilités offertes par ce modèle non supervisé ! Vous pouvez retrouver tous les codes sur le notebook ici appliqué à un data set d’articles de presse de sklearn.
N’hésitez pas à me demander en commentaire si vous avez besoin d’aide 🙂



Hello,
have you a dataset to apply