
Le problème le plus simple et le plus ancien en machine learning est la régression linéaire. Après avoir expliquer le principe théorique, on verra comment faire de la régression en pratique avec Python. Vous verrez c’est très simple. Je ne sais même pas si on peut parler de machine learning, mais bon ça fait plus stylé 😎

Mais attention ! Malgré sa simplicité le modèle de régression est encore très utilisé pour des applications concrètes. C’est pour cela que c’est l’un des premiers modèles que l’on apprend en statistiques.
Fonctionnement de la régression linéaire
Le principe de la régression linéaire est très simple. On a un ensemble de points et on cherche la droite qui correspond le mieux à ce nuage de points. C’est donc simplement un travail d’optimisation que l’on doit faire.
En dimension 2, le problème de régression linéaire a l’avantage d’être facilement visualisable. Voilà ce que ça donne.
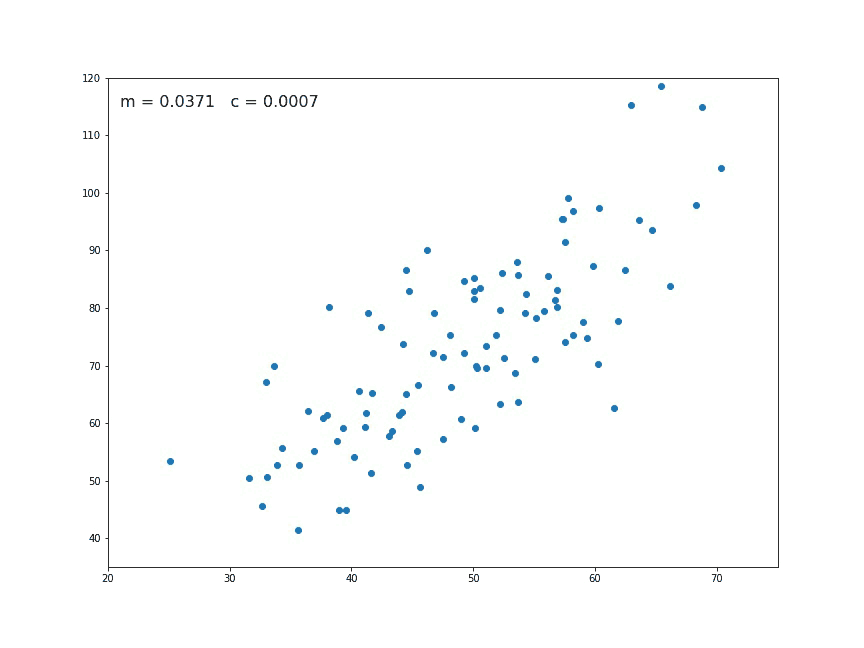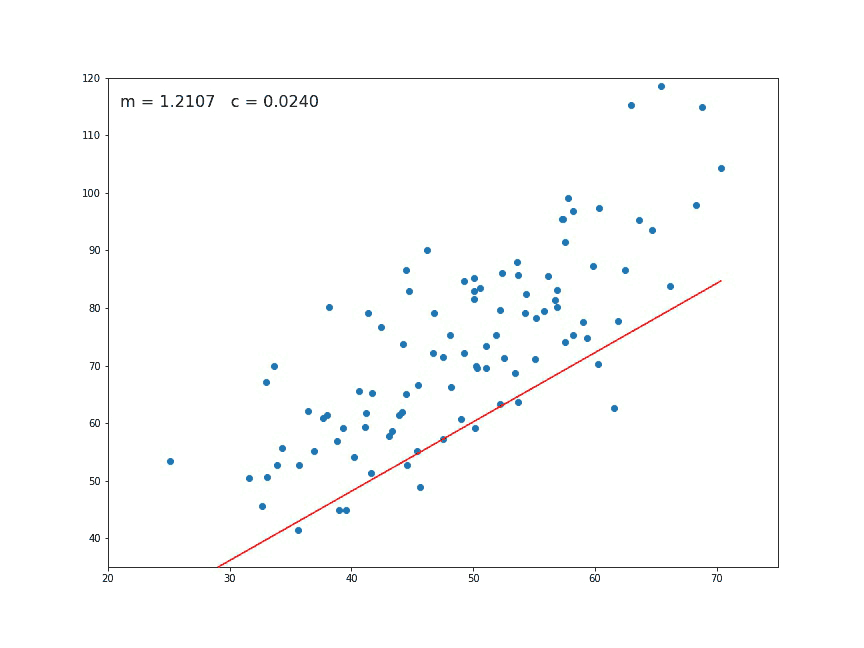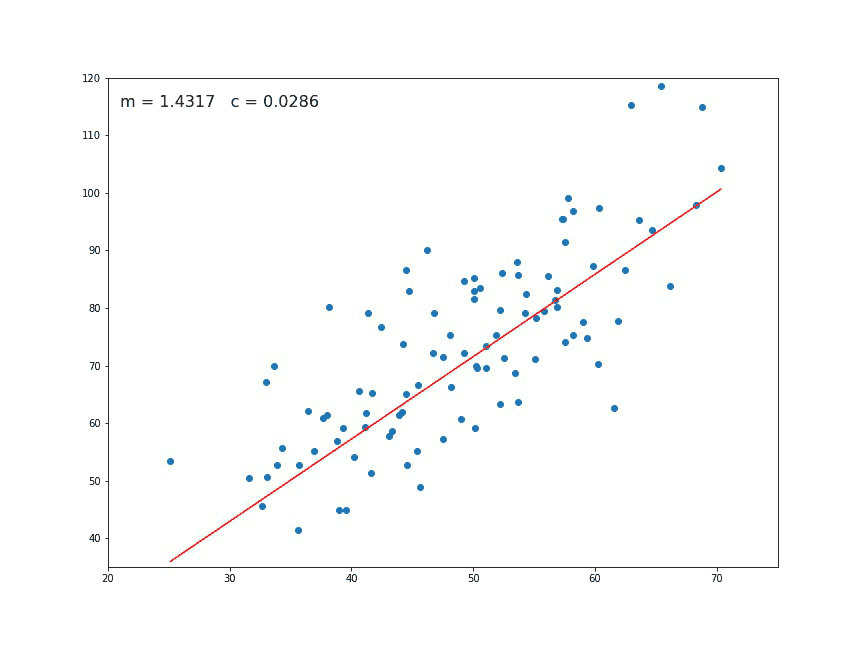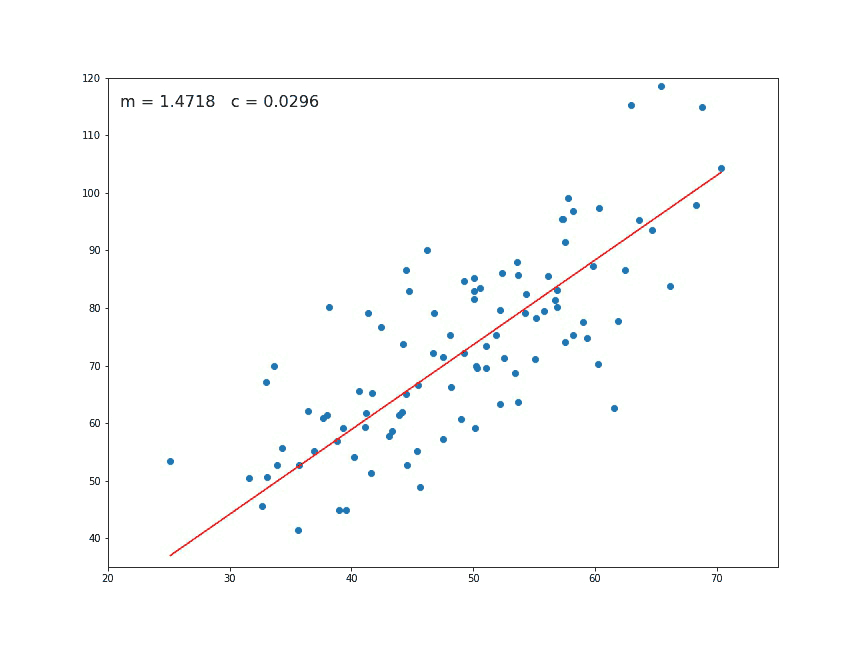
La régression linéaire est souvent utiliser comme un moyen de détecter une éventuelle dépendance linéaire entre deux variables. Elle sert aussi souvent lorsqu’il s’agit de faire des prédictions.
Et oui ! Je vous ai dit de ne pas sous-estimer cette méthode !

Notion d’erreur quadratique moyenne
Pour évaluer la précision d’une droite d’estimation, nous devons introduire une métrique de l’erreur. Pour cela on utilise souvent l’erreur quadratique moyenne (ou mean squared error).
L’erreur quadratique moyenne est la moyenne des carrées des différences entre les valeurs prédites et les vraies valeurs. Bon peut être que ce n’est pas assez clair dit de cette manière. Voici la formule.
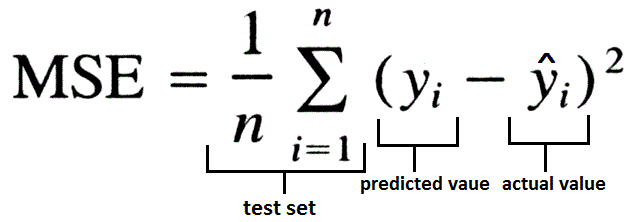
Par exemple si vos valeurs sont les suivantes :
y = [1,1.5,1.2,0.9,1]Et que les valeurs prédites par votre modèle sont les suivantes :
y_pred = [1.1,1.2,1.2,1.3,1.2]L’erreur quadratique moyenne vaudra alors :
MSE = (1/5)*((1-1.1)²+(1.5-1.2)²+(1.2-1.2)²+(0.9-1.3)²+(1-1.2)²)
= 0.012 = 1.2%Avec Python, le calcul grâce à Numpy est simple :
MSE = np.mean((y - y_pred)**2)Au delà de la régression linéaire, l’erreur quadratique moyenne est vraiment primordiale en machine learning. C’est souvent la métrique d’erreur qui est utilisée (c’est ce qu’on appelle la loss function). Il y a plusieurs raisons à ça.
Sans entrer dans les détails théoriques sous-jacents, il se trouve que la régularité de l’erreur quadratique moyenne est très utile pour l’optimisation. L’optimisation en mathématiques est la branche qui s’intéresse à la minimisation des fonctions. Et il se trouve que les fonctions régulières (convexes, continues, dérivables, etc.) sont plus faciles à optimiser.
Pour les plus matheux, cet article sur Towards data science compare les résultats obtenus pour plusieurs mesures d’erreurs. Vous aurez une explication beaucoup plus détaillée.
Trouver l’erreur minimale avec une descente de gradient
En pratique on cherchera à exprimer l’erreur quadratique moyenne en fonction des paramètres de notre droite. En dimension 2 par exemple, l’erreur sera exprimée simplement en fonction du coefficient directeur et de l’ordonnée à l’origine.
Une fois qu’on a cette expression, il s’agit de trouver le minimum de cette fonction. C’est à dire la droite qui minimise l’erreur.
Pour cela on utilise souvent la descente de gradient, mais de nombreuses méthodes d’optimisation existent. Cette question est détaillée dans un de mes articles.
Régression linéaire avec scikit learn
Maintenant que l’on a compris le fonctionnement de la régression linéaire, voyons comment implémenter ça avec Python.
Scikit learn est la caverne d’Alibaba du data scientist. Quasiment tout y est ! Voici comment implémenter un modèle de régression linéaire avec scikit learn.
Pour résoudre ce problème, j’ai récupéré des données sur Kaggle sur l’évolution du salaire en fonction du nombre d’années d’expérience.
Dans le cadre d’un vrai problème on aurait séparé nos données en une base d’entraînement et une base de test. Mais n’ayant que 35 observations, je préfère qu’on utilise tout pour l’entraînement.
On commence par importer les modules que l’on va utiliser :
import pandas as pd # Pour importer le tableau
import matplotlib.pyplot as plt # Pour tracer des graphiques
import numpy as np # Pour le calcul numérique
from sklearn.linear_model import LinearRegression
# le module scikitOn importe maintenant les données. Vous pouvez télécharger le fichier csv ici.
data = pd.read_csv('Salary.csv')
# On transforme les colonnes en array
x = np.array(data['YearsExperience'])
y = np.array(data['Salary'])
# On doit transformer la forme des vecteurs pour qu'ils puissent être
# utilisés par Scikit learn
x = x.reshape(-1,1)
y = y.reshape(-1,1)On a deux colonnes, Years of experience le nombre d’années d’expérience et Salary qui donne le salaire.
D’abord, on peut commencer par tracer la première variable en fonction de l’autre. On remarque bien la relation de linéarité entre les deux variables.
plt.scatter(x,y)La fonction plt.scatter permet de tracer un nuage de points.
Le résultat est le suivant :
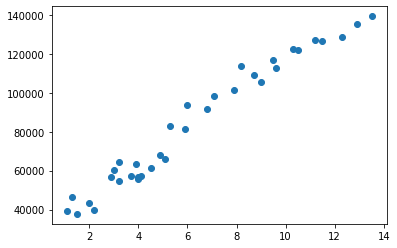
Il est temps de construire le modèle :
reg = LinearRegression(normalize=True)
reg.fit(x,y)
Je rappelle que l’on souhaite trouver la droite f(x)=ax+b qui minimise l’erreur.
Pour accéder à ces valeurs on peut écrire :
a = reg.coef_
b = reg.intercept_Traçons la courbe de prédictions :
ordonne = np.linspace(0,15,1000)
plt.scatter(x,y)
plt.plot(ordonne,a*ordonne+b,color='r')On obtient le résultat suivant :
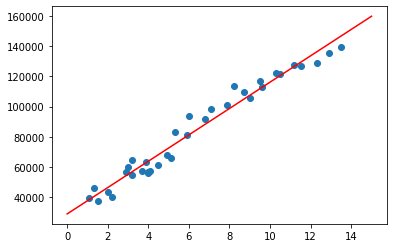
Voilà ! Notre droite de régression linéaire est construite. Maintenant si vous connaissez l’expérience d’un salarié vous pouvez prédire son salaire en calculant :
salaire = a*experience+bTous les codes sont disponibles sur Google Colab à cette adresse.

Laisser un commentaire