
Le machine learning évolue vite, mais s’appuie toujours sur un socle d’outils indispensables. Voici une liste d’outils et de technologies que j’utilise au quotidien pour mener un projet de machine learning ou deep learning de bout en bout : collecte et préparation des données, entraînement de modèles, gestion du code, expérimentation, industrialisation et déploiement.
Python vs R
Arrêtons d’opposer Python et R : les deux ont leur place dans la boîte à outils d’un data scientist moderne.
- Python s’impose pour le prototypage, le deep learning, la data engineering et la production. Son écosystème : scikit-learn, PyTorch, TensorFlow, pandas, en fait un incontournable.
- R reste un excellent choix pour les statisticiens, l’analyse exploratoire, le travail académique et la visualisation avancée (ggplot2 n’a toujours pas d’égal).
Si vous débutez, commencez par Python. Si vous faites beaucoup d’analyse statistique, ajoutez R.
Pandas, NumPy, Matplotlib, SciPy : les incontournables
Lorsque l’on veut entraîner des modèles de machine/deep learning, on doit être capable de mettre en forme efficacement nos données, d’extraire des métriques sur ces modèles et d’évaluer et de visualiser correctement nos résultats. On a plus ou moins d’étapes en fonction du type de données :
- Gestion des données manquantes : Cette étape consiste à identifier, imputer ou supprimer les valeurs absentes afin d’éviter qu’elles ne biaisent le modèle.
- Gérer un éventuel déséquilibre des classes : Lorsque certaines classes sont sous-représentées, il faut rééquilibrer le dataset pour permettre au modèle d’apprendre correctement.
- Mise en forme du dataset : On prépare les variables en les normalisant, encodant ou transformant pour rendre les données exploitables par les algorithmes.
- Séparation en train/test : Le dataset est divisé pour entraîner le modèle d’un côté et évaluer sa capacité de généralisation de l’autre.
- Entraînement des modèles : Le modèle apprend les patterns présents dans les données d’entraînement grâce à un algorithme d’optimisation.
- Optimisation des hyperparamètres : On ajuste les paramètres externes du modèle pour améliorer ses performances sans modifier les données.
- Validation croisée : Le dataset est découpé en plusieurs sous-ensembles afin d’évaluer la robustesse du modèle sur différents segments de données.
- Détecter et prévenir l’overfitting : On surveille si le modèle mémorise trop les données d’entraînement et on applique des techniques pour limiter ce phénomène.
- Visualisation des résultats : Les performances et comportements du modèle sont représentés graphiquement pour faciliter l’interprétation et la prise de décision.
Avant de parler d’IA, il faut revenir aux fondamentaux. Aucune démarche sérieuse en machine learning n’est possible sans un minimum de maîtrise des outils scientifiques de base.
Pandas
Véritable couteau suisse du data scientist, il permet de manipuler facilement des données tabulaires. Nnettoyage et transformation des colonnes, gestion des valeurs manquantes, création de nouvelles features, jointures entre tables.
On peut aussi l’utiliser pour la préparation du dataset avant l’entraînement d’un modèle. C’est l’outil que vous utiliserez probablement le plus au quotidien.
NumPy
Numpy sert de moteur mathématique à l’essentiel de l’écosystème Python. Il est conçu pour manipuler efficacement des matrices et des tenseurs. Il permet d’exécuter rapidement des opérations vectorisées. Et il fournit les briques de base sur lesquelles reposent plusieurs frameworks de machine learning et de deep learning. Comprendre NumPy, c’est comprendre ce qui se passe sous le capot lorsque vous entraînez un modèle.
SciPy
Scipy prolonge les capacités de NumPy en ajoutant des fonctions avancées de statistiques, d’optimisation ou d’algèbre linéaire. Dès qu’une analyse nécessite un test statistique précis, un solveur d’équations complexes ou une méthode d’optimisation fine, SciPy devient incontournable.
Matplotlib
Enfin, la visualisation joue un rôle majeur dans l’exploration et la validation des modèles. Matplotlib reste la librairie la plus flexible pour construire n’importe quel graphique.
Seaborn simplifie grandement la visualisation statistique en produisant des graphes élégants avec peu de code.
Quant à Plotly, il permet d’aller vers des visualisations interactives. Particulièrement utiles pour des dashboards ou des analyses partagées en entreprise.
Ensemble, ces outils constituent le cœur d’un workflow de machine learning bien structuré :
- préparation des données
- analyse exploratoire
- visualisation des patterns
- compréhension des distributions
- détection des anomalies
- validation des modèles.
Ils forment une base solide sur laquelle repose tout projet de data science.
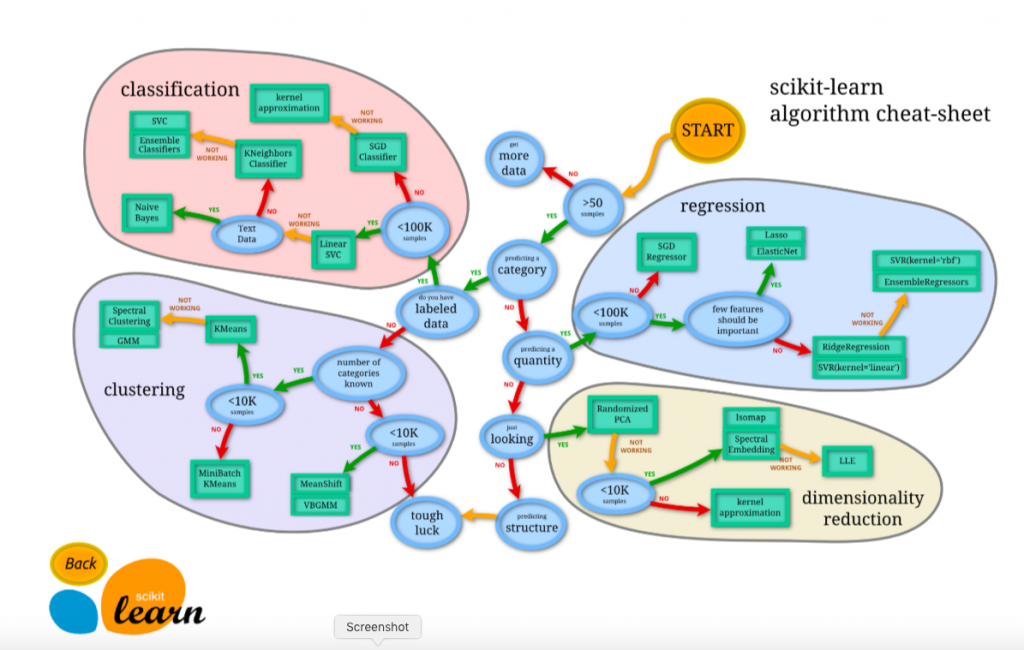
Scikit-learn, la référence des outils de machine learning
Scikit-learn reste aujourd’hui la référence incontournable pour tout ce qui touche au machine learning classique.
La bibliothèque offre un ensemble très riche d’algorithmes couvrant la classification. Qu’il s’agisse d’un SVM, d’une Random Forest ou d’un Gradient Boosting. Ainsi que la régression et le clustering, avec des méthodes comme k-means ou DBSCAN.
Elle propose également des outils puissants pour la réduction de dimension, notamment l’ACP/PCA, t-SNE ou encore UMAP. Ce qui en fait un allié essentiel pour explorer ou simplifier des données complexes.
Scikit-learn brille par son écosystème complet de pipelines, de fonctions de validation croisée, de recherche d’hyperparamètres et d’évaluation des performances. Elle permet de structurer proprement un projet de machine learning de bout en bout.
Plus récemment, la bibliothèque s’intègre encore mieux aux pratiques modernes de MLOps grâce à des API compatibles ONNX. Grâce aussi à des optimisations qui tirent parti des GPU, renforçant ainsi son rôle clé dans l’industrialisation des modèles.
PyTorch et TensorFlow pour le deep learning
Le deep learning s’est imposé comme la base de l’IA moderne, et deux frameworks dominent le paysage : PyTorch et TensorFlow. Ils ont le même objectif, faciliter l’entraînement de réseaux de neurones, mais leur syntaxe et leurs usages diffèrent.
PyTorch
Ce framework s’est imposé ces dernières années comme la référence de la communauté scientifique et de la recherche.
Sa grande force vient de son mode d’exécution dynamique, proche du python natif, qui permet de construire et modifier un modèle en cours d’exécution de manière intuitive.
Cette flexibilité en fait un choix naturel pour les travaux expérimentaux, les architectures complexes et les modèles génératifs modernes. Son écosystème est riche, notamment avec TorchVision pour la vision par ordinateur. TorchText et TorchAudio pour le NLP et l’audio. Ou encore PyTorch Lightning qui apporte une structure plus propre aux projets.
Par ailleurs, PyTorch s’intègre parfaitement aux environnements cloud et GPU, ce qui renforce son adoption massive dans les laboratoires et les startups d’IA.
TensorFlow
De son côté, Tensorflow reste un framework très solide et largement utilisé dans les environnements industriels. Son modèle d’exécution initial, statique et optimisé, favorise les pipelines reproductibles et la mise en production à grande échelle.
TensorFlow se distingue également grâce à TensorFlow Lite pour les applications mobiles et embarquées, TensorFlow Serving pour le déploiement de modèles en API, et son intégration fluide avec l’écosystème Google Cloud, notamment Vertex AI.
Keras, qui sert de surcouche unifiée, simplifie grandement la construction de modèles et rend le framework plus accessible aux débutants et permet des usages avancés.
Les autres framework de deep learning
En résumé, PyTorch est généralement préféré pour la recherche, la rapidité d’expérimentation et la flexibilité. TensorFlow demeure un excellent choix pour l’industrialisation, l’optimisation et les solutions déployées à grande échelle.
Pour aller plus loin, il existe aussi d’autres frameworks qui peuvent s’avérer utiles selon les besoins : JAX pour la recherche en optimisation et les modèles différentiables haute performance, MXNet historiquement développé par Amazon, MindSpore proposé par Huawei, ou encore ONNX Runtime, particulièrement efficace pour accélérer et déployer des modèles issus de différents frameworks.
Chacun répond à des cas d’usage spécifiques et enrichit l’écosystème très dynamique du deep learning.
SQL : un incontournable parmi les outils de machine learning
On prédit la fin de SQL depuis des années, mais la réalité est tout autre. Le langage reste central dans le travail quotidien des data scientists.
Même dans un environnement dominé par les solutions NoSQL, les Data Lakes massifs et les Data Warehouses modernes, SQL demeure l’outil le plus fiable et le plus efficace pour : interroger de grandes bases de données, explorer rapidement des datasets volumineux, préparer des features ou orchestrer des transformations complexes.
Sa présence est indispensable dans les infrastructures cloud, qu’il s’agisse de BigQuery ou Snowflake. En pratique, un data scientist qui ne maîtrise pas SQL travaille avec un sérieux handicap.
GitHub et gitLab

Travailler efficacement en machine learning nécessite une véritable rigueur logicielle, et c’est précisément là que Git, GitHub et GitLab deviennent indispensables.
Ces outils permettent de versionner proprement son code, de collaborer sereinement grâce aux branches et aux merge requests. On peut sécuriser ses projets en conservant une copie distante, bien plus fiable que des fichiers disséminés en local.
Ils offrent également un espace organisé pour stocker modèles, notebooks et documentations, tout en facilitant l’automatisation grâce aux pipelines CI/CD. Un simple README bien structuré ou un fichier requirements.txt peut transformer un projet en ressource claire et réutilisable. Tant pour soi-même que pour les autres.
Même lorsqu’on travaille seul, utiliser Git est un véritable gain de temps. Dès qu’on travaille en équipe, il devient absolument incontournable.
Docker

Docker n’est plus un outil réservé aux DevOps : il est devenu un élément central du travail des data scientists et des ML engineers.
Grâce à lui, il est possible d’encapsuler un environnement de développement complet, d’éviter les conflits de versions entre machines et de garantir la reproductibilité des résultats, ce qui est indispensable dans un projet scientifique ou industriel.
Docker facilite également le packaging de modèles de machine learning pour les exposer sous forme d’API. Tout en permettant de standardiser et d’automatiser les workflows data, en local comme sur le cloud.
Aujourd’hui la maîtrise de Docker n’est pas un bonus, c’est une compétence clé pour ceux souhaitant travailler et collaborer efficacement.
Providers cloud et MLOps
Après avoir assuré la reproductibilité et la portabilité des environnements grâce à Docker, l’étape suivante consiste à maîtriser les outils qui permettent de déployer et d’opérer des modèles de machine learning à grande échelle.
Les data scientists sont désormais attendus sur toute la chaîne de valeur, de la conception du modèle à son intégration dans un environnement cloud ou dans une application métier.
Les principales plateformes, comme Google Cloud avec Vertex AI, AWS avec SageMaker ou encore Azure ML, offrent des solutions complètes pour entraîner, évaluer, déployer et monitorer les modèles dans des pipelines solides et reproductibles.
Des outils comme Databricks simplifient encore l’ingénierie de données et le machine learning à grande échelle, tandis que Hugging Face facilite le déploiement de modèles open-source et l’utilisation d’API performantes.
Cette évolution du métier pousse les data scientists à devenir de véritables profils hybrides, capables de combiner compétences analytiques, développement logiciel et maîtrise des infrastructures cloud.
Focus sur MLFlow
Dans ce contexte, MLflow occupe une place essentielle en tant que standard ouvert du suivi d’expériences et de la gestion du cycle de vie des modèles.
Il permet d’enregistrer automatiquement les paramètres, les métriques et les versions de modèles, facilitant la comparaison d’expérimentations et la reproductibilité scientifique.
MLflow propose également un modèle unifié de packaging via MLflow Models, qui rend le déploiement plus simple, que ce soit localement, sur un serveur dédié ou dans un service cloud.
Sa fonctionnalité MLflow Registry centralise la gestion des versions de modèles, leur validation et leur transition entre les environnements de test, de staging et de production.
Grâce à sa flexibilité et à son intégration avec tous les principaux frameworks de machine learning et de deep learning, MLflow est devenu un pilier incontournable des pratiques MLOps modernes.
Conclusion
Cette liste n’a évidemment rien d’exhaustif, mais elle rassemble les outils qui constituent aujourd’hui le socle indispensable de tout data scientist ou machine learning engineer souhaitant travailler efficacement en 2025.
Maîtriser ces technologies permet non seulement d’adopter une démarche plus rigoureuse et mieux structurée, mais aussi d’expérimenter plus rapidement, de collaborer proprement et de déployer des modèles fiables dans des environnements réels.
À mesure que le domaine évolue, de nouveaux outils apparaissent et d’autres gagnent en maturité, mais ceux présentés ici offrent une base solide pour progresser, monter en compétence et développer des projets d’IA réellement opérationnels.



Laisser un commentaire