
Dans les différents projets où l’on a utilisé random forest, il s’agissait de faire de la classification. Nous pouvons aussi faire de la régression avec random forest.

Dans ce tutoriel nous allons voir comment l’utiliser pour prédire le loyer d’un logement à Paris. Pour ce faire nous coderons sur Python en utilisant le module scikit-learn.
Données et présentation du problème
J’ai récupéré la base de données sur la plateforme data gouv. La base de données a été publiée par la mairie de Paris dans le cadre de l’encadrement des loyers.
Data gouv est une source de données plutôt fiable que je vous conseille pour vos projets. Surtout lorsque l’on sait que la qualité des données est un point crucial en machine learning.
La base Encadrement des loyers 2019 contient un certains nombre d’informations sur plus de 2000 logements à Paris :
- id_zone : numéro de zone
- id_quartier : numéro de quartier
- nom_quartier : nom du quartier
- piece : nombre de pièces
- epoque : période de construction
- meuble_txt : meublé/non meublé
- ref : loyer de référence
- max : loyer maximum
- min : loyer minimum
- geo_shape : géométrie du logement
- geo_point_2D : coordonnées du logement
Pour construire le modèle nous utiliserons nom_quartier, piece, epoque, meuble_txt. L’objectif sera de prèdire le loyer de référence ref.
Implémentation de random forest pour la régression
Si vous avez suivi mes anciens projets vous connaissez déjà scikit-learn. Si ce n’est pas le cas jetez-y un œil !
On commence par importer les modules utiles :
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressorEnsuite on importe la base de données que l’on souhaite traiter avec le module Pandas :
data = pd.read_csv('logement-encadrement-des-loyers.csv',sep = ';')data.head() permet d’avoir un aperçu du tableau de données pour s’assurer qu’il a été importé correctement :
data.head()On commence par mettre les données dans le format souhaité. On met de côté l’attribut ref qui n’est autre que la variable que l’on souhaite prédire.
La fonction get_dummies de Pandas nous permet d’encoder les variables catégoriques avec l’encodage one-hot. Le principe de cette encodage est très simple, on transforme la colonne en une matrice composée de tous les valeurs possibles, avec un 1 lorsque l’option est réalisée et 0 partout ailleurs. L’image suivante vous permettra de mieux comprendre le principe.
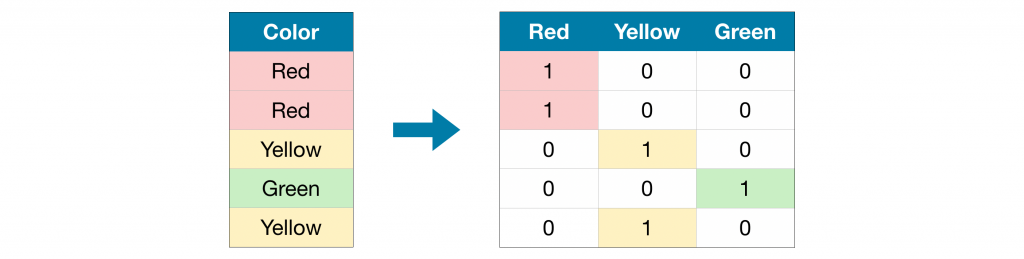
Ensuite, comme toujours, on sépare notre dataset en données d’entraînements et données de test. Voici le code à écrire :
X = pd.DataFrame(data,columns = ['nom_quartier','piece',
'epoque','meuble_txt'])
Y = data['ref']
X = pd.get_dummies(X)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,
test_size = 0.2)Il ne nous reste plus qu’à entraîner le modèle. La seule différence avec le random forest que l’on utilise habituellement et que c’est le regressor (et non pas le classifieur).
regressor = RandomForestRegressor(n_estimators = 10,
random_state = 0)
regressor.fit(X_train, Y_train)Maintenant on peut regarder nos résultats sur les données de test. Pour cela rien de plus simple !
y_pred = regressor.predict(X_test)Visualisation et évaluation du modèle
On peut regarder les performances de notre modèle en comparant les résultats prédits et ceux attendus.
Pour cela on commence par importer matplotlib.pyplot pour la visualisation.
import matplotlib.pyplot as pltOn trace pour les 20 premières valeurs le prix de référence prédits par notre modèle et le prix attendus :
import matplotlib.pyplot as plt
plt.title('Performance du modèle')
plt.plot(list(y_pred)[:20])
plt.plot(list(Y_test)[:20])
plt.legend()Le résultat obtenu est plutôt bon pour un premier modèle :
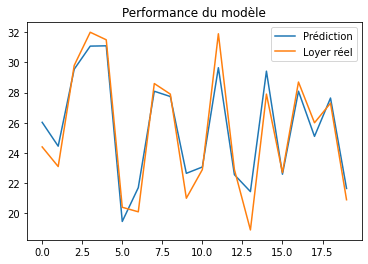
Evidemment le fait d’avoir des bons résultats sur les premières valeurs ne donne aucune indication sur la performance globale du modèle. Pour cela on utilise plutôt des métriques comme l’erreur quadratique moyenne ou la MAPE.
Il intéressant de voir comment avec un modèle aussi simple on a réussi à avoir d’aussi bonnes performances. On peut même aller plus loin en exploitant de façon plus précise les données.
Par exemple en calculant la surface et en prenant en compte la géométrie des logements. De même on aurait pu exploiter de façon plus poussée la localisation. Plutôt que d’utiliser le découpage par défaut donné par la mairie de Paris, prendre en compte les positions exactes pourrait nous aider.



Bonjour, savez vous afficher ces données avec le module folium ? merci
bonjour comment esque je peux faire une machine learning de mon pc du gernre il me les emplacement de mes differents dosssier ou logiciel de ma machine
bonjour exemple de base de donnée pour les diffèrents logiciel, dossier , image, etc… qui se trouve dans un pc