
Une étude statistique faite de manière hâtive peut conduire à des conclusions douteuses. Les biais en IA sont un problème bien réel. L’overfitting est le plus courant. Sur le site ‘’Spurious correlations’’, on trouve un certain nombre de corrélations entre des variables. Et, a priori, elles n’ont rien à voir entre elles.

Ainsi, l’importation de pétrole des USA depuis la Norvège serait corrélée avec le nombre de personnes tuées dans une collision avec un train. Le taux de divorce dans le Maine serait corrélé avec la consommation de margarine. Étrange n’est-ce pas ?
Ce biais intervient lorsque l’on veut trop interpréter les données en voulant expliquer des phénomènes autrement que par le hasard. Dans les exemples que j’ai donnés précédemment, le fait que l’on ait affaire à des coïncidences est évident. Malheureusement il n’est pas toujours facile de le voir.
Corrélation n’est pas causalité
Pour ne pas se faire avoir en lisant les résultats d’une étude statistique, il est important de comprendre que deux variables peuvent être corrélées, sans qu’aucun lien de causalité entre ces deux variables n’existe. Et réciproquement, il peut y avoir causalité sans corrélation.
On distingue plusieurs cas de surinterprétation. Le premier consiste à conclure que deux variables corrélées ont un lien de causalité alors que ce n’est pas le cas. Comme dans les exemples évoqués dans l’introduction.
Le second, moins grave mais quand même trompeur, consiste à omettre de préciser qu’il y a une chaîne de causalités qui entraîne cette corrélation. Par exemple, dans les pays où on mange beaucoup de viande, le nombre de prix Nobel est élevé. Ah, donc la viande rend plus intelligent ? Eh bien non, cela peut être dû au fait que les pays riches consomment plus de viande et c’est aussi ceux qui remportent le plus de prix Nobel.
Il peut y avoir surinterprétation, lorsque deux variables sont interdépendantes. On ne peut pas dire que la première variable implique la deuxième ou inversement. Conclure dans ce cas qu’un des phénomènes implique l’autre est un mensonge.
Lors d’une étude statistique où l’on cherche à déterminer si deux variables sont en adéquation, on énonce une hypothèse appelée »hypothèse nulle » ou plus simplement H0. Elle permet de vérifier s’il y a adéquation entre les deux variables ou non. L’expérience n’a donc que deux issues : soit ‘’on rejette H0’’ soit ‘’on ne rejette pas H0’’. La formulation est importante ici : quelque soit le résultat de l’expérience, H0 ne sera jamais vrai, elle sera au mieux non rejetée. Le biais peut ainsi être évité.
Automatiser le processus peut aggraver les biais
L’algorithme utilisé par le site ‘’spurious correlation’’ étudie des corrélations entre des milliers de jeux de données. C’est pourquoi, même si la probabilité de trouver de fausses corrélations est faible. On peut en trouver certaines : la probabilité de gagner au loto est faible mais sur des millions d’essais il peut y avoir un gagnant. Les résultats que je vous ai énoncés dans l’introduction sont deux résultats parmi des millions. Même si la probabilité de tels résultats est minime, elle n’est pas nulle.
Ainsi, il est très facile de concevoir des algorithmes qui vont trouver des corrélations entre des jeux de données, sans tenir compte de leur signification et de la méthodologie qui a permis de les collecter.
Le biais de confirmation, pour ne rien arranger
Le biais de confirmation est un biais cognitif qui fait que l’on cherche toujours à faire correspondre ce que l’on pense savoir avec ce que l’on observe. Quitte à faire preuve de malhonnêteté, omettant des critères, ou en choisissant ceux qui nous donnent raison.
Ce biais est remarquablement bien illustré sur le site fivethirtyeight. On veut étudier les effets sur l’économie américaine de politiciens démocrates et républicains. Si vous êtes démocrate, vous estimez par exemple que les critères qui définissent une bonne économie sont l’inflation et le taux de chômage, les résultats vous donnent raison. Si vous êtes républicain, vous répondez qu’il est aussi important de considérer le marché boursier et dans ce cas, les résultats vous donnent raison.
Dans les journaux on lira ‘’D’après des études scientifiques, les démocrates (ou républicains) ont un effet bénéfique sur l’économie’’ . Je vous laisse le lien de la page pour trouver les résultats qui vous arrangent.
Le problème des biais en IA
De façon plus générale, comme pour les humains, les biais en IA sont une triste réalité. Les affaires impliquant des IA biaisées sont communes.
Amazon en a fait l’expérience. L’entreprise américaine a conçu un modèle d’aide à la décision pour le recrutement de personnels. Et ils ont observés que dans la majorité des cas, les profils féminins étaient rejetés par l’IA.
La raison à cela est que les données qui ont été utilisées pour l’entrainement du modèle étaient biaisés. La majorité des recrutements fait par Amazon sont des recrutements d’hommes blancs. L’IA a donc surinterprété les données, et en a déduit qu’il fallait recruter surtout des hommes blancs.
De façon similaire, un modèle a été conçu aux Etats-Unis pour calculer la probabilité de récidive chez les criminels. Et comme les données étaient biaisées, le modèle affectait directement une pénalité aux personnes afro-américaines.
C’est pour cela qu’il est important de suivre des protocoles précis lors de la conception de modèles. Cela peut permettre d’éviter des catastrophes sociales de ce genre. C’est encore plus important dans des domaines sensibles comme la santé, le droit ou l’assurance.
La nécessité d’éviter les biais en IA, a accéléré le développement de domaines du machine learning comme l’explicabilité.
Le problème d’overfitting en deep learning
La sur-interprétation statistiques n’est pas le seul problème que l’on rencontre en analyse de données. Pour entraîner un réseau de neurones on a des données labellisées. Lors de l’entrainement on cherche à ce que les sorties données par le modèle soient les mêmes que celles dont ont dispose.
Dans beaucoup de cas, notamment quand l’entrainement est trop long, le modèle peut se mettre à faire de l’overfitting. C’est à dire qu’il commencera à trop coller aux données et ne pourra plus être généralisé.
L’illustration suivante montre ce qu’est l’overfitting pour un problème de régression.
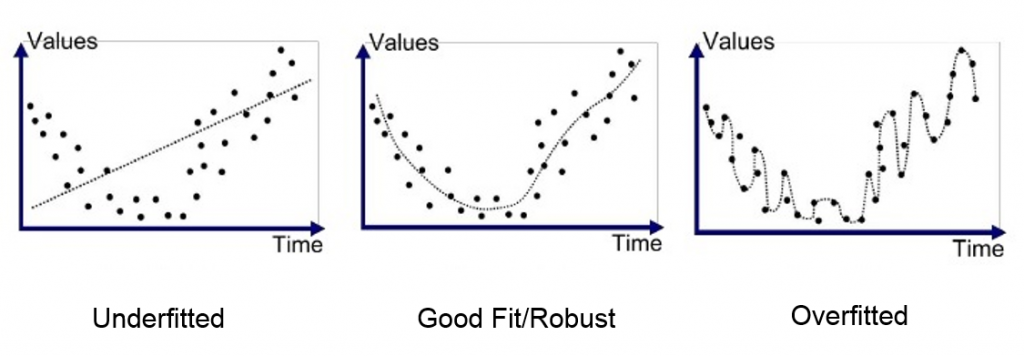
Heureusement des techniques existent pour reconnaitre les cas ou il y a overfitting et pour les éviter. Si ce sujet vous intéresse il pourrait très bien faire l’objet d’un article.
Comme les statistiques, le machine learning doit être manipulé avec précaution, rigueur et honnêteté. C’est seulement comme ça qu’il pourra conduire à des résultats mathématiquement acceptables. Il faut éduquer notre sens critique concernant cela. La responsabilité sociale du data scientist est une notion qui doit être prise en compte. Tellement les biais en IA sont répandus. Pourquoi ne pas crée un code de déontologie de la data science ?



Laisser un commentaire