
Article original « Building with GPT for education: how we built an AI tutor that passed one of the toughest exams « rédigé par Rafael Pinheiro Costa et traduit par Aelia Maury.
Clipping est une startup qui aide les candidats à exceller dans des examens hautement compétitifs. Avec un taux d’approbation de 94% à l’examen « Brazilian Diplomatic Career Examination », nous construisons avec l’IA et les interfaces conversationnelles dans l’éducation depuis 2018, lorsque nous avons remporté les Bot Awards Brazil en tant que meilleur chatbot pour l’éducation aux côtés de marques telles que Magazina Luiza, PagSeguro et Rock in Rio.
Plus tôt cette année, nous avons lancé notre système de correction automatique pour les questions de dissertation, un algorithme propriétaire développé dans le cadre d’un projet de recherche en collaboration avec le Département d’informatique de l’Université de Minas Gerais (UFMG) et le Parc technologique de Bell Horizonte (BHTEC) où nous sommes également une entreprise résidente. Maintenant, nous lançons ClippingGPT (bêta), un tuteur IA qui aide les étudiants à réaliser leur plein potentiel grâce à un tutorat personnalisé.
Beaucoup de personnes nous ont contacté pour obtenir des détails sur la manière dont nous avons formé un modèle qui a non seulement réussi l’examen d’entrée dans la carrière diplomatique, mais aussi surpassé GPT-4 de 26% dans cet examen particulier, réputé comme l’un des plus difficile en Amérique latine. J’ai donc pensé que ce serait une excellente occasion de documenter et de partager ce cas.
TLDR :
a) Le principal problème de l’utilisation de ChatGPT et des LLM dans l’éducation n’est pas la triche, mais les risques de désinformation pendant le processus d’apprentissage en raison d’hallucinations.
b) Il est possible d’atténuer ces risques en formant un modèle sur une base de connaissances externe afin d’améliorer l’exactitude des réponses.
c) Après avoir formé ClippingGPT sur une base de connaissances externe, nous avons validé sa réussite à l’examen d’entrée de carrière diplomatique, surpassant les autres candidats et GPT-4.
d) Le fait qu’une IA formée sur une base de connaissances externe ait réussi avec brio l’un des examens les plus difficiles démontre le potentiel des LLM pour construire des tuteurs intelligents dans le domaine de l’éducation.
J’espère que cet article pourra être utile à ceux qui s’intéressent à l’exploration de l’utilisation responsable de l’IA dans les contextes éducatifs.
Le problème des LLMs dans l’éducation
Bien que GPT et les grands modèles de langage (LLMs) représentent une avancée significative dans le domaine de l’IA, leur utilisation dans l’éducation pose de nombreux défis.
Cela est principalement dû au fait que les LLMs tels que ChatGPT fonctionnent en tant que modèles de langage plutôt que comme bases de connaissances, ce qui rend difficile de confirmer l’exactitude des informations qu’ils fournissent.
Hallucinations
En termes simples, ces modèles statistiques reconnaissent des motifs dans les séquences de mots et prévoient les mots suivants en se basant sur leurs données d’entraînement. Au lieu d’évaluer la véracité des informations, le système est conçu pour anticiper comment une question serait répondue.
ChatGPT écrit parfois des réponses qui semblent plausibles, mais qui sont incorrectes ou sans signification (OpenAI, sur les limites de ChatGPT).

Bien que les modèles de langage soient impressionnants en termes de fluidité, ils ont tendance à générer de fausses déclarations. Celles-ci vont des inexactitudes subtiles aux hallucinations extravagantes [1].
Lorsqu’il s’agit d’apprendre une nouvelle compétence ou de préparer un examen à enjeux élevés, le fait de sembler plausible est contre-productif, voire dangereux.
Une grande partie des discussions actuelles sur l’impact de ChatGPT dans l’éducation porte sur la tricherie, mais les risques de désinformation généralisée lors de l’apprentissage sont bien plus préoccupants.
GPT-4 présente des limitations similaires aux modèles GPT précédents. Plus important encore, il n’est toujours pas entièrement fiable (il « hallucine » des faits et commet des erreurs de raisonnement). Il convient d’être très prudent lors de l’utilisation des sorties du modèle de langage, en particulier dans des contextes à enjeux élevés (Rapport technique GPT-4, OpenAI)[2].
GPT-4 a obtenu un taux de précision de 60 % sur le référentiel TruthfulQA, un test couvrant différentes catégories conçu pour mesurer la véracité d’un grand modèle de langage (LLM).
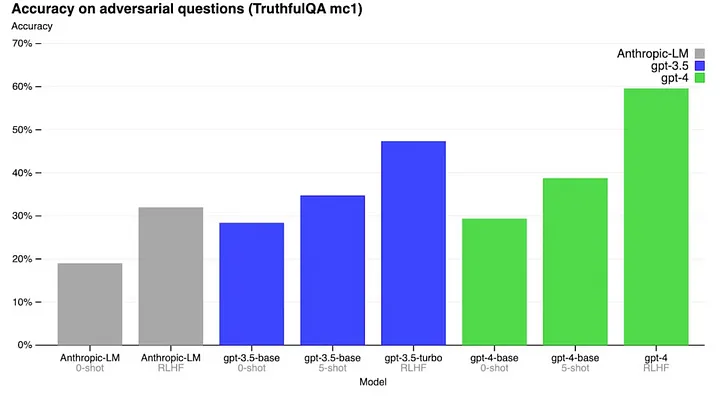
Contenu obsolète
Les informations obsolètes posent un autre problème. En général, GPT-4 ne dispose pas de connaissances sur les événements survenus après la coupure de la grande majorité de ses données de pré-entraînement en septembre 2021.
La base de connaissances de ChatGPT n’a pas été mise à jour de GPT 3.5 à GPT-4. De nouvelles mises à jour ne seront pas disponibles prochainement, car OpenAI a confirmé que l’entreprise ne forme pas GPT-5 et « ne le fera pas de sitôt ».
Biais linguistique
Le biais linguistique est également important.
GPT a tendance à générer davantage d’hallucinations dans des langues autres que l’anglais, en raison de la prédominance de l’anglais dans ses ensembles de données d’entraînement.
Pourquoi est-ce un problème ? Sur les près de 8 milliards de personnes dans le monde, seulement 5 % utilisent l’anglais comme langue maternelle. Il y a des angles morts dans les données d’entraînement de GPT et la plupart de ses utilisateurs sont significativement impactés par cela.
Essayez d’approfondir des sujets tels que l’histoire, la politique internationale, etc. Il suffit de quelques prompts (sollicitations) pour repérer des résultats préoccupants.
GPT-4 n’a pas réussi à fournir une réponse précise à une question assez simple sur l’histoire du Brésil.
Des biais linguistiques se manifestent car la majorité du contenu sur Internet est en anglais ou dans quelques autres langues dominantes, ce qui rend les grands modèles de langage plus performants dans ces langues. Cela peut entraîner des performances biaisées et un manque de soutien pour les langues à ressources limitées [3].
Les LLM ne sont qu’un point de départ
Il est peu probable qu’une solution aux hallucinations, au contenu obsolète et aux biais se produise rapidement. Et c’est tout à fait normal !
En réalité, ce sont plus des fonctionnalités que des bugs.
Les LLM, tels que ChatGPT, ont été conçus comme un point de départ pour d’autres modèles plus petits qui résolvent des problèmes plus spécifiques.
Le potentiel de GPT et d’autres grands modèles de langage réside dans le fait que leurs modèles génériques permettent à d’autres de construire des systèmes plus petits reposant sur une base de connaissances externe afin de résoudre des problèmes spécifiques.
Nous arrivons à la fin de l’époque de ces modèles géants
Sam Altman, PDG d’OpenAI, le 13 avril
Nous avons développé ClippingGPT pour valider le potentiel des modèles plus petits dans les environnements éducatifs.
Dans la section suivante, nous détaillons notre hypothèse.
ClippingGPT : Tester une hypothèse sur l’utilisation des LLM dans l’éducation
Notre hypothèse :
Un modèle plus petit formé sur une base de connaissances spécifique et à jour surpasse GPT-4 dans l’examen d’entrée de carrière diplomatique au Brésil ?
Pourquoi l’examen d’entrée de carrière diplomatique brésilienne ?
(1) Nous disposons déjà des données prétraitées nécessaires pour le test : Clipping a été une référence pour les examens complexes au Brésil depuis plus de 5 ans et nous disposons de données exclusives prétraitées pour la construction d’une base de connaissances externe solide pour l’expérience.
(2) Il s’agit de l’un des examens les plus complexes en Amérique latine : L’examen d’entrée de carrière diplomatique est généralement considéré par les étudiants brésiliens comme l’examen le plus éprouvant et sélectif, composé d’épreuves écrites évaluant des connaissances approfondies dans une vaste gamme de matières, comprenant des domaines tels que : la politique internationale, l’histoire du Brésil, la géographie, le droit constitutionnel et le droit international public, l’économie, l’anglais, le français, l’espagnol et la langue portugaise.
(3) Être à jour est une partie essentielle de cet examen : les candidats sont censés se tenir au courant des développements dans les domaines susmentionnés, notamment en ce qui concerne les derniers événements en politique internationale.
(4) La majorité des connaissances est basée sur des textes en langue non anglaise : cette contrainte constitue un cas intéressant d’utilisation au-delà de l’ensemble de données centré sur l’anglais sur lequel GPT a été formé.
La méthodologie : comment avons-nous procédé ?
(1) Nous avons utilisé GPT-4 pour générer des réponses aux questions d’examen de rédaction contenues dans l’examen de rédaction officiel administré aux candidats à la carrière diplomatique en 2022 ;
(2) Ensuite, nous avons demandé à un groupe d’enseignants spécialisés dans la préparation des candidats à l’examen diplomatique d’évaluer les réponses sans savoir préalablement qu’elles étaient générées par notre modèle d’IA (notation aveugle) ;
(3) Nous avons formé ClippingGPT sur une base de connaissances externe et généré avec notre modèle de nouvelles réponses au même examen, puis nous avons répété le processus de l’étape 2 (notation aveugle) ;
(4) Enfin, nous avons comparé le score final obtenu par ClippingGPT selon 2 paramètres : a) les scores obtenus par GPT-4 ; b) les scores obtenus par les candidats ayant été approuvés lors du dernier examen en 2022.
Les résultats : ce que nous avons découvert ?
Les résultats globaux de ClippingGPT sont les suivants :
- 23e place ;
- score de 597,79 ;
- surclassement de 26 % par rapport à GPT-4.
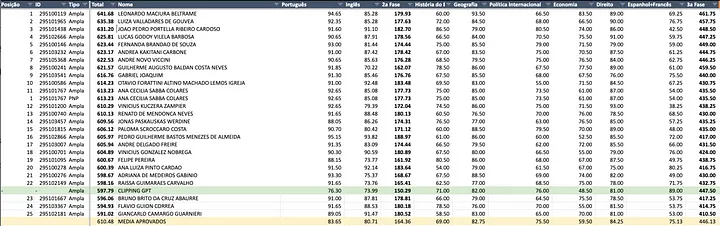
Quant à GPT-4, il a obtenu un score de 473,8, se classant à la 177e place et n’ayant pas réussi à se hisser parmi les 35 candidats approuvés.
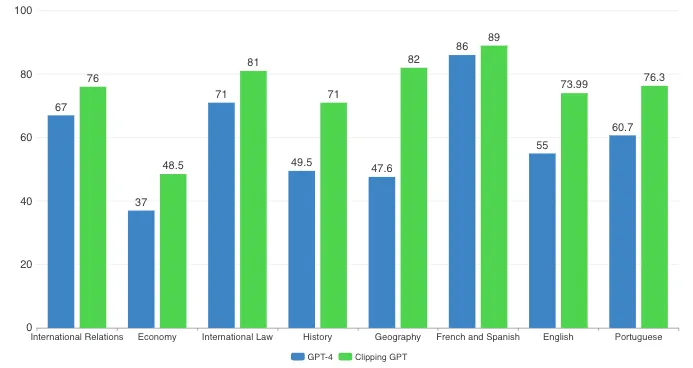
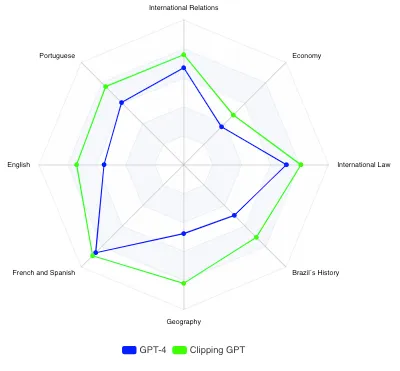
Quelques informations sur les résultats :
(1) La plus grande différence entre GPT-4 et ClippingGPT se situe dans les domaines de la géographie et de l’histoire du Brésil. Dans ces deux matières, une grande partie du contenu nécessaire pour répondre aux questions demande aux candidats une maîtrise de la littérature spécifique mettant en évidence des faits et des arguments locaux et régionaux peu susceptibles de figurer dans l’ensemble de données utilisé pour former GPT-4. Il peut y avoir une corrélation ou cela peut signifier que notre modèle a surmonté certains angles morts dans des sujets spécifiques, ce qui a conduit à de meilleures performances. La précision s’est considérablement améliorée. Cependant, les hallucinations n’ont pas été complètement éliminées.
(2) Le français et l’espagnol sont des valeurs aberrantes avec une plus petite variation. Dans le cas de cet examen de rédaction particulier, la structure diffère, les candidats sont invités à traduire et à résumer. Contrairement aux autres examens, aucune connaissance externe n’est requise. Cela explique les scores similaires.
(3) Pour l’examen de langue portugaise, un résultat curieux. Tant ClippingGPT que GPT-4 ont obtenu des scores inférieurs à la moyenne des candidats admis. Selon Guilherme Aguiar, titulaire d’un doctorat en langue portugaise et chargé d’évaluer les examens de langue portugaise : « Les réponses au test de langue portugaise impressionnent par leur cohérence interne de l’argumentation, même si les textes présentent une série de déficiences structurelles et grammaticales qui compromettent le score obtenu, qui reste néanmoins dans la plage de notes de passage ». Cela peut s’expliquer par le fait que les essais sont évalués selon des règles conservatrices de ponctuation, de régence de certains verbes et noms, ainsi que d’autres normes qui ne font pas consensus parmi les experts en grammaire, et qui ont joué un rôle dans les résultats, nous le croyons.
💡Opportunité : De nouvelles avancées peuvent être réalisées grâce à des mesures pratiques visant à réduire les hallucinations, telles que l’ajustement de la température du modèle (proche de 0), l’ingénierie des instructions (nous avons utilisé différentes instructions pour chaque sujet), la chaîne de réflexion, etc. [4]
Dans la section suivante, nous abordons plus en détail sur le plan technique la manière dont nous avons entraîné GPT avec des connaissances supplémentaires pour atteindre les résultats mentionnés ci-dessus.
- ClippingGPT : construction d’un modèle d’IA pour l’éducation
Comme dans ChatGPT, notre utilisateur peut interagir de manière conversationnelle avec le modèle. La principale différence réside dans le fait que nous l’avons entraîné à effectuer un rappel factuel dans une base de connaissances propriétaire fiable avant de renvoyer les réponses. Cela augmente la probabilité que sa réponse finale soit cohérente et correcte.
ClippingGPT fournit une réponse précise à la question sur l’histoire du Brésil à laquelle GPT-4 n’a pas réussi à répondre correctement.
Les techniques d’embeddings et de fine-tuning sont utilisées pour entraîner GPT sur des données distinctes, mais elles servent à des fins différentes et impliquent des méthodes d’entraînement différentes. Le fine-tuning est plus adapté pour enseigner au modèle un style, tandis que les embeddings sont recommandés comme moyen d’enseigner au modèle des connaissances. Dans notre cas d’utilisation, nous cherchions à éviter les hallucinations et le contenu obsolète. Il s’agit principalement d’un problème lié aux connaissances.
Par conséquent, les embeddings semblaient être l’approche naturelle. En résumé, l’embedding consiste à transformer du texte en nombres, ce qui permet à GPT de comprendre les relations entre les mots et d’identifier des schémas dans une série de mots pour prédire les mots suivants. En termes plus simples, c’est ainsi que GPT construit progressivement des réponses, allant des plus basiques aux plus sophistiquées. Les embeddings sont également extrêmement utiles pour stocker et récupérer des informations grâce à la similarité sémantique.
Notre modèle a été construit en utilisant des « embeddings » pour rappeler les connaissances.
Étape 1 : Création d’embeddings pour une base de connaissances
Tout d’abord, nous avons préparé la base de connaissances à partir de laquelle nous voulons que notre modèle puise des informations fiables et actuelles. Ce faisant, nous prévoyons que les réponses seront obtenues à partir d’une source de confiance, ce qui permettra de réduire la possibilité d’inexactitudes.
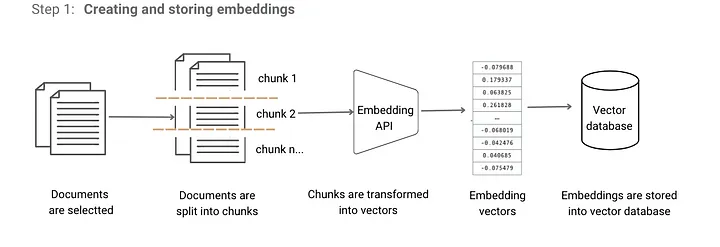
Pendant le traitement des données, nous avons :
– divisé les documents en sections (morceaux) ;
– transformé chaque morceau en embedding à l’aide de l’API OpenAI ;
– stocké les embeddings dans une base de données vectorielle (nous avons utilisé Redis) ;
💡 Opportunité : Si vous utilisez la reconnaissance optique de caractères (OCR) pour certains documents, le nettoyage des données devient extrêmement important. Des informations clés telles que les dates et les nombres peuvent être compromises lors de l’étape de traitement.
Étapes 2 et 3 : recherche et fourniture de réponses
À un niveau élevé, voici comment fonctionne le modèle :
1. Dans un premier temps, il récupère des informations pertinentes par rapport à la requête de l’utilisateur.
2. Ces informations sont ensuite ajoutées à la requête de l’utilisateur.
3. Enfin, la requête enrichie est envoyée à l’API pour générer une réponse.
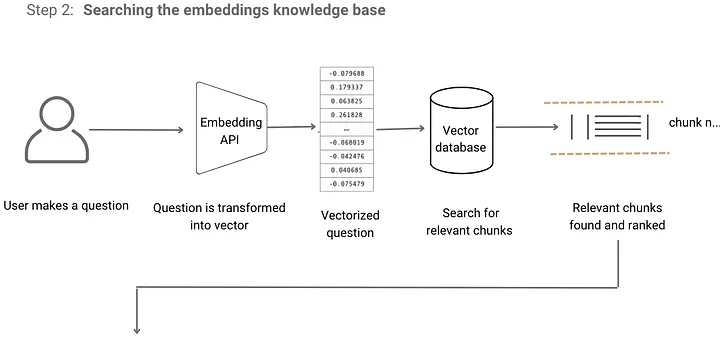
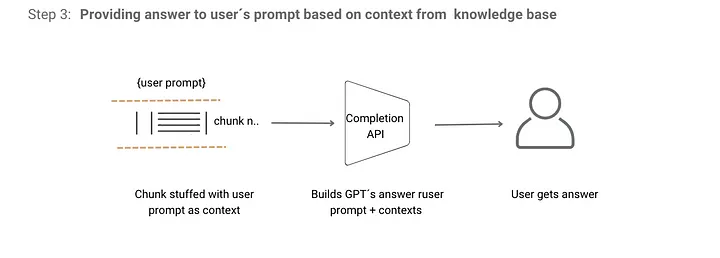
Étape 2 : Lorsque l’utilisateur pose une question à ClippingGPT, celui-ci traite l’entrée de l’utilisateur et la transforme en un vecteur à l’aide de l’API d’Embeddings d’OpenAI. Il analyse ensuite la distance entre le vecteur de la requête de l’utilisateur et les vecteurs de différentes sections. Ensuite, il classe ces sections en fonction de leur pertinence, indiquant où la réponse potentielle peut être trouvée.
Étape 3 : Le modèle intègre ces sections pertinentes en tant que contexte dans un message envoyé à GPT. Cette requête enrichie est ensuite envoyée à l’API de Complétion d’OpenAI, qui génère et renvoie la réponse.
💡 Opportunité : Diverses méthodes, telles que HyDE [5], Dera [6] et Reflexion [7], peuvent améliorer les résultats. Notre plan est d’itérer ces techniques en incorporant des modifications mineures dans l’architecture ci-dessus.
- Conclusion et prochaines étapes
Dans le domaine de l’éducation, la principale préoccupation liée à l’utilisation de ChatGPT et d’autres LLM réside dans les risques de désinformation liés aux hallucinations, aux informations obsolètes et biaisées lors de l’apprentissage. Ces risques, bien qu’importants, peuvent être atténués, comme notre expérience avec ClippingGPT l’a démontré.
Former un modèle sur une base de connaissances externe peut considérablement améliorer l’exactitude des réponses de l’IA.
Pour les prochaines étapes, nous allons itérer sur d’autres techniques pour améliorer continuellement notre modèle (Hyde, Dera, Reflections, etc.), tout en explorant de nouvelles approches pour aborder les hallucinations.
References:
[1] S Lin, J Hilton, O Evans. TruthfulQA: Measuring How Models Mimic Human Falsehoods. 2021
[2] OpenAI. GPT-4 Technical Report. 2023.
[3] E Ferrara. Should ChatGPT be Biased? Challenges and Risks of Bias in Large Language Models. 2023
[4] V Dibia. Practical Steps to Reduce Hallucination and Improve Performance of Systems Built with Large Language Models. 2023
[5] Gao, Luyu, et al. HYDE: Precise Zero-Shot Dense Retrieval without Relevance Labels. 2022
[6] Nair, Schumacher, Tso, Kannan. DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents. 2023
[7] Shinn, Labash, Gopinath. Reflexion: an autonomous agent with dynamic memory and self-reflection. 2023



Laisser un commentaire